背景
公司有一个渠道系统,专门负责对接三方渠道,主要承担报文转换和参数校验等工作,业务逻辑相对简单,起着承上启下的作用。
最近在优化接口的响应时间时,发现一个诡异的现象:在优化了业务代码后,接口耗时仍然达不到要求。在接口内部打印的请求处理时间与调用方感知的响应时间之间存在大约100ms的差距。例如,程序内部记录耗时150ms,但调用方等待的时间却在250ms左右。
本文将详细记录定位和解决这个问题的全过程。解决方法本身或许不复杂,但关键的挑战在于如何准确找到问题的根源。
定位过程
初步分析代码
渠道系统是一个标准的基于 Spring Boot 的 Web 工程,使用了内嵌的 Tomcat 容器。在分析了代码之后,并未发现特殊之处,也没有额外的过滤器或拦截器,因此初步排除了业务代码导致问题的可能性。
分析调用流程
出现此问题后,首先确认了接口的调用链路。由于是内部测试环境,链路相对简单。
Nginx -反向代理-> 渠道系统
服务器部署在云上,网络走的是云内网。为排除网络因素,首先验证服务器间的网络延迟。
测试客户端到 Nginx 的网络:
[jboss@VM_0_139_centos ~]$ ping 10.0.0.139
PING 10.0.0.139 (10.0.0.139) 56(84) bytes of data.
64 bytes from 10.0.0.139: icmp_seq=1 ttl=64 time=0.029 ms
64 bytes from 10.0.0.139: icmp_seq=2 ttl=64 time=0.041 ms
64 bytes from 10.0.0.139: icmp_seq=3 ttl=64 time=0.040 ms
64 bytes from 10.0.0.139: icmp_seq=4 ttl=64 time=0.040 ms
从 ping 结果看,客户端到 Nginx 主机的网络延迟极低,没有问题。
测试 Nginx 到渠道系统的网络:
(日志相似,显示延迟同样很低)
既然网络看似无问题,便采用排除法。为了缩小问题范围,我们绕过 Nginx,让客户端直接在渠道系统服务器上通过回环地址(localhost)直连,这样可以避免网卡、DNS等因素的干扰。我们测试的是一个空接口。
[jboss@VM_10_91_centos tmp]$ curl -w “@curl-time.txt” http://127.0.0.1:7744/send
success
http: 200
dns: 0.001s
redirect: 0.000s
time_connect: 0.001s
time_appconnect: 0.000s
time_pretransfer: 0.001s
time_starttransfer: 0.073s
size_download: 7bytes
speed_download: 95.000B/s
----------
time_total: 0.073s 请求总耗时
从 curl 日志看,即使通过本地回环地址调用一个空接口,也耗费了 73ms。这很奇怪,因为它已经跳过了中间所有节点和过滤器。接着,我们立刻进行第二次请求:
[jboss@VM_10_91_centos tmp]$ curl -w “@curl-time.txt” http://127.0.0.1:7744/send
success
http: 200
dns: 0.001s
redirect: 0.000s
time_connect: 0.001s
time_appconnect: 0.000s
time_pretransfer: 0.001s
time_starttransfer: 0.003s
size_download: 7bytes
speed_download: 2611.000B/s
----------
time_total: 0.003s
更奇怪的现象出现了:第二次请求耗时变得正常,仅为 3ms。经查阅,Linux 的 curl 默认开启了 HTTP Keep-Alive。但即使关闭 Keep-Alive,每次重新握手也不至于需要 70ms。
经过反复测试,发现了一个规律:连续请求时耗时很短(几毫秒),但如果间隔一段时间(如几十秒)再请求,首次请求又会花费 70ms 以上。
这个现象提示我们,可能与某种缓存机制有关。连续请求时命中缓存,所以快;缓存过期后首次请求需要重新加载,所以慢。
那么,问题点究竟在哪一层?是 Tomcat 层面还是 Spring WebMVC 层面?
借助 Arthas 进行深入分析
光靠猜想无法定位问题。我们尝试将代码导入本地 IDE 启动测试,但无法复现这个 70ms+ 的延迟。本地无法复现,又不能通过加日志方式调试业务代码(因为问题不在业务层),这让人有些头疼。
此时,就是 Java 诊断神器 Arthas 登场的时候了。Arthas 是阿里巴巴开源的 Java 诊断工具,功能强大。我们这次只需要用到它的一个小功能:trace。它可以动态追踪方法内部调用路径,并输出路径上每个节点的耗时,帮助我们精确找到时间消耗在何处。
trace 命令能主动搜索 class-pattern/method-pattern 对应的方法调用路径。- 它会渲染和统计整个调用链路上的所有性能开销。
那么,该追踪什么方法呢?由于对 Tomcat 源码不熟,我们决定先从 Spring MVC 的入口下手,追踪 DispatcherServlet。
追踪 Spring MVC 入口
我们执行 trace 命令,然后再次发起请求。



同时,curl 请求的耗时如下:
[jboss@VM_10_91_centos tmp]$ curl -w “@curl-time.txt” http://127.0.0.1:7744/send
success
http: 200
dns: 0.001s
redirect: 0.000s
time_connect: 0.001s
time_appconnect: 0.000s
time_pretransfer: 0.001s
time_starttransfer: 0.115s
size_download: 7bytes
speed_download: 60.000B/s
----------
time_total: 0.115s
本次调用,客户端感知的总耗时是 115ms。但从 Arthas 的 trace 结果看,Spring MVC (DispatcherServlet) 处理只消耗了约 18ms。那么,剩下的 97ms 去哪了?
本地测试已基本排除 Spring MVC 的问题。最后,也是唯一可能出问题的点,就落在了 Tomcat 身上。
反向查找 Tomcat 调用栈
但我不熟悉 Tomcat 源码,连请求入口类都不清楚。不过没关系,Arthas 提供了 stack 命令,可以反向输出当前方法被调用的路径。我们以 org.springframework.web.servlet.DispatcherServlet 作为起点,查看是谁调用了它。
stack 输出当前方法被调用的调用路径
很多时候我们都知道一个方法被执行,但这个方法被执行的路径非常多,或者你根本就不知道这个方法是从那里被执行了,此时你需要的是 stack 命令。




从 stack 日志可以清晰地看到 DispatcherServlet 的完整调用栈。在跳过 Spring MVC 内部过滤器的追踪后(它们并非耗时元凶),我们将目光投向了 Tomcat 的核心处理类。从命名上推测,org.apache.coyote.http11.Http11Processor.service(HTTP/1.1 处理器)是一个不错的切入点。
追踪 Tomcat 请求处理器
我们对 Http11Processor.service 方法进行 trace。


日志中显示了一个长达 129ms 的耗时点(注意,由于 Arthas 本身会带来性能开销,这个时间比未开启 Arthas 时略长)。这正是我们要找的问题所在!
找到了耗时的方法,但具体是什么操作导致了延迟?我们继续深入 trace,原则是:追踪耗时最长的那个方法。
深入追踪,定位问题根源
我们逐步追踪耗时方法内部的调用。

经过一番手动深入 trace 后,我们追踪到了更底层的资源加载过程。

在这里,发现了一个关键线索:
+---[min=0.004452ms,max=34.479307ms,total=74.206249ms,count=31] org.apache.catalina.webresources.TomcatJarInputStream:getNextJarEntry() #117
这行显示 getNextJarEntry() 方法被调用了 31 次,总耗时 74ms。从类名 TomcatJarInputStream 和 方法名看,这明显是在加载 Jar 包内的资源。那么,是加载了 31 个不同的 Jar 包,还是加载了同一个 Jar 包内的 31 项资源?
查看 TomcatJarInputStream 类的源码注释:
The purpose of this sub-class is to obtain references to the JarEntry objects for META-INF/ and META-INF/MANIFEST.MF that are otherwise swallowed by the JarInputStream implementation.
大意是:这个子类的目的是获取 Jar 包内 META-INF/ 和 META-INF/MANIFEST.MF 资源的引用,这些资源在父类 JarInputStream 的实现中会被“吞掉”。
看到这里,我们大概能猜到问题了:Tomcat 在加载 Jar 包内 META-INF 目录下的资源时产生了耗时。而连续请求不耗时,很可能是因为 Tomcat 对这些资源有缓存机制。
最终确认问题资源
为了最终确认,我们使用 Arthas 的 watch 命令来动态观测方法调用的入参数据,看看具体加载了哪些资源。
watch 方法执行数据观测
“让你能方便的观察到指定方法的调用情况。能观察到的范围为:返回值、抛出异常、入参,通过编写 OGNL 表达式进行对应变量的查看。”
我们 watch TomcatJarInputStream.createZipEntry(String name) 方法的 name 参数。

输出结果一目了然!加载的资源名非常眼熟:swagger-ui.html、springfox-swagger-ui.css、swagger-ui.js.map…… 这些都是 Swagger UI 相关的静态资源。Swagger 是一个流行的 API 文档工具,而 springfox-swagger-ui 是其与 Spring MVC 集成的组件。
结论:问题就出在 Swagger 相关的 Jar 包上。删除相关依赖后,那诡异的 70+ms 延迟果然消失了。
<!-- pom 里删除这两个引用。springfox-swagger-ui 并非 Swagger 官方提供的 Spring MVC 支持包 -->
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger2</artifactId>
<version>2.9.2</version>
</dependency>
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger-ui</artifactId>
<version>2.9.2</version>
</dependency>
那么,为什么 Swagger 会导致每次请求都去加载静态资源?这其实是 Tomcat Embed 版本的一个 Bug。
Tomcat Embed Bug 分析与解决方案
源码分析过程较长,这里直接给出分析结果。
首先,贴一张 Tomcat 处理请求的核心映射关系图,便于理解:
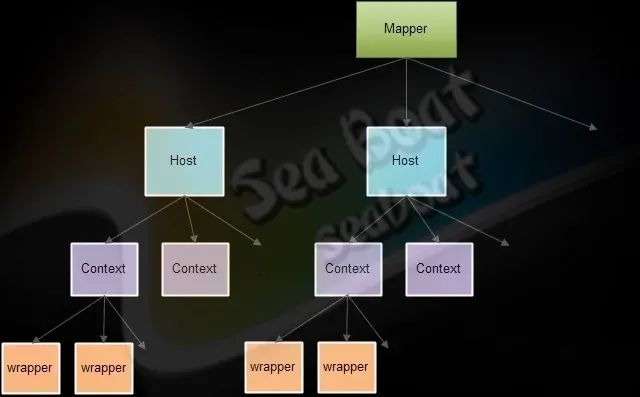
问题根源分析
-
为什么每次请求会加载 Jar 包内的静态资源?
关键在于 org.apache.catalina.mapper.Mapper#internalMapWrapper 这个方法。在有问题版本的 Tomcat 中,处理请求映射的逻辑存在缺陷,导致每次请求都会重新校验和尝试映射静态资源,从而触发 Jar 包内资源的加载。
-
为什么连续请求不会出现问题?
因为 Tomcat 对解析过的静态资源路径是有缓存的(参考 org.apache.catalina.webresources.Cache 类)。请求会优先从缓存中查找,缓存默认的生存时间(TTL)是 5000ms。在缓存有效期内,后续请求不会触发重新加载,所以很快。缓存过期后,首次请求会再次触发加载,导致延迟。
-
为什么在本地 IDE 中启动无法复现?
确切地说,是通过 Spring Boot Maven 插件打包后运行的 FatJar 才会出现此问题。在 IDE 中直接运行 main 方法启动时,由于类路径(Classpath)和资源加载方式的不同(文件系统 vs Jar 包),Tomcat 使用了不同的资源处理逻辑,因此不会触发这个 Bug。
解决方案
根本的解决方法是升级 tomcat-embed 版本。
- 出现 Bug 的版本:
spring-boot:2.0.2.RELEASE,其内置的 tomcat-embed 版本为 8.5.31。
- 修复版本:将
tomcat-embed 升级至 8.5.40 及以上版本即可解决此问题。
方法一:在 Maven 中覆盖 Spring Boot 管理的 Tomcat 版本
如果你的项目通过 Maven 继承或依赖管理引入了 Spring Boot:
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.0.2.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
可以直接在项目的 pom.xml 中覆盖 tomcat.version 属性:
<properties>
<tomcat.version>8.5.40</tomcat.version>
</properties>
方法二:直接升级 Spring Boot 版本
spring-boot 2.1.0.RELEASE 及其后续版本中内置的 tomcat-embed 版本已经高于 8.5.31。因此,直接将 Spring Boot 升级到 2.1.0.RELEASE 或更高版本,也可以一劳永逸地解决此问题。
通过这次实战排查,我们不仅解决了接口响应延迟的问题,也深刻体会到像 Arthas 这样的高级 运维 诊断工具在定位复杂线上问题时的巨大价值。希望这个案例能为你提供一种清晰的问题排查思路。如果你在开发中也遇到了棘手的性能问题,不妨到 云栈社区 和大家一起交流探讨。
 发表于 2026-3-7 04:30:22
|
查看: 147|
回复: 0
发表于 2026-3-7 04:30:22
|
查看: 147|
回复: 0
