使用 Raft 共识算法结合单机 KV 引擎构建分布式 KV 存储,是一种被广泛采用的架构模式,例如 TiKV 和 CockroachDB。此方式同样适用于构建高可用的控制面节点。本文将深入探讨在这种架构下,如何高效地实现 Raft Snapshot。
1 Raft 与 Snapshot
1.1 Raft 基础
Raft 共识算法在网络上已有大量优秀解析。本文仅简述核心概念。
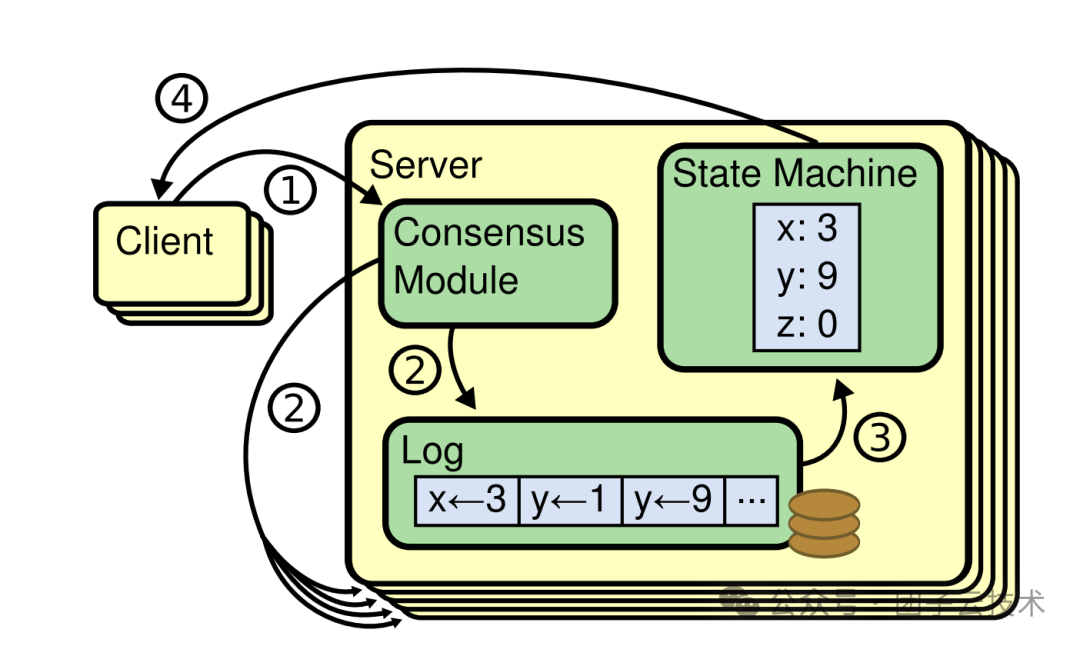 图 - Raft 复制状态机 [1]
图 - Raft 复制状态机 [1]
上图展示了一组 Raft 复制状态机。需要明确的是,Raft 本身只是一个共识算法。
- 我们期望实现高可用的业务逻辑,称为状态机。
- 状态机的每个操作,经由共识算法处理,形成日志,持久化后最终应用到业务状态机。
- 外部调用者称为客户端。
- 整个共识算法、持久化层与状态机,统称为服务端。
1.2 Raft KV 系统设计
基于 Raft 的抽象,一个典型的“Raft + 单机KV引擎”系统可设计如下:
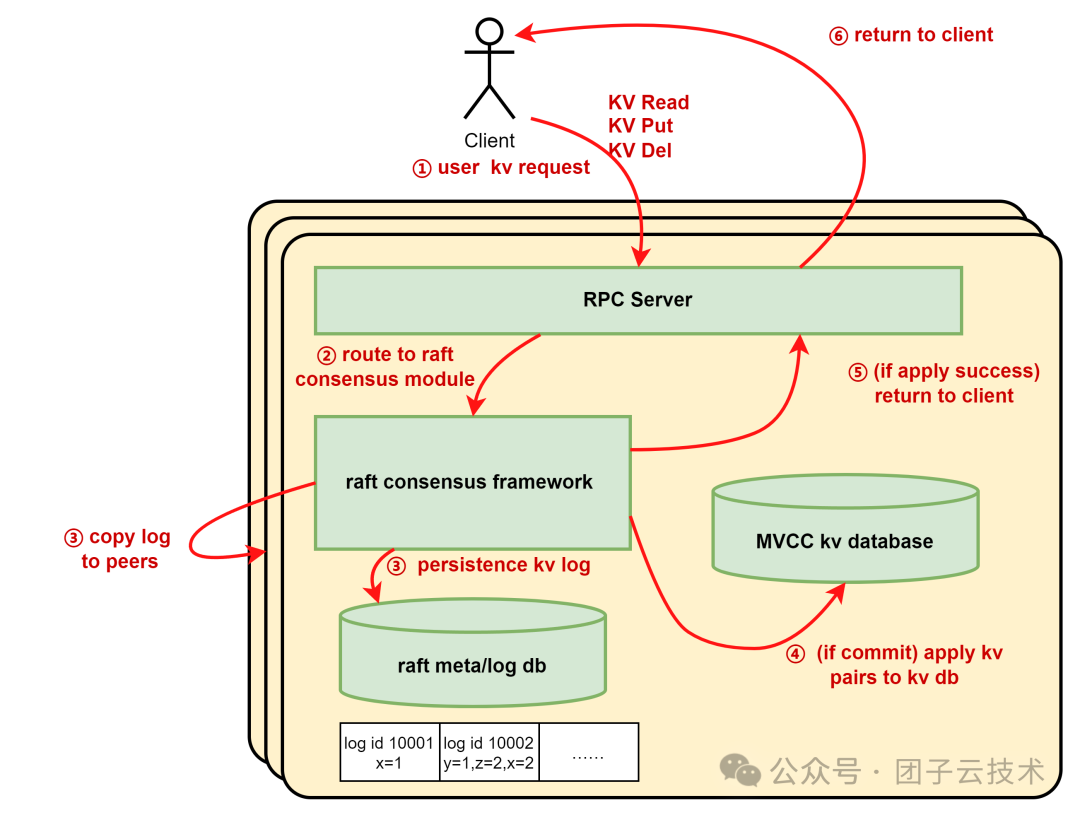 图 - 基于 Raft 的分布式 KV 存储
图 - 基于 Raft 的分布式 KV 存储
其中:
- 状态机:即单机存储引擎,例如 LSM 类型的 KV 数据库 RocksDB。
- 日志:每次 KV 读写操作,如 Put、Del。它们也可以是一组批处理操作。
- 客户端:KV 调用者,发起读或写请求。
- 服务端:包含整个状态机、Raft 框架及日志系统。
服务端对外暴露的接口通常包括:
- KV Get
- KV Put
- KV Del
- KV Batch Get/Put/Del
1.3 Raft Snapshot
(注:此处指 Raft 日志压缩快照,而非 MVCC 数据库快照)
为何需要 Snapshot?根据上述设计,业务状态机在任意时刻的状态,本质上都是由从 0 开始的所有日志顺序 Apply 构建而成。这意味着,从 0 重放日志也能重建出完全一致的状态机。
随着操作不断累积,日志不能无限增长。因此需要在某个时刻为状态机创建快照。一旦快照完成,无论是 Leader 还是 Follower,都可以基于此快照及后续的日志来重建状态机。Raft Snapshot 的核心作用正是完成日志压缩。
1.4 Raft 框架的 Snapshot 接口
Raft 框架不理解应用层状态机的具体语义,因此必须由用户来实现自己的 SnapshotLoader 和 SnapshotSaver。框架则负责调用时机、数据流的持久化或网络传输。
- 在 Save Snapshot 过程中,用户需将自身状态机序列化为数据流,由 Raft 框架负责持久化或传输给其他 Follower。
- 在 Load Snapshot 过程中,用户需将数据流反序列化,恢复为自己的状态机。
例如,baidu/braft 要求用户实现以下快照接口:
// user defined snapshot generate function, this method will block on_apply.
// user can make snapshot async when fsm can be cow(copy-on-write).
virtual void on_snapshot_save(::braft::SnapshotWriter* writer,
::braft::Closure* done);
// user defined snapshot load function
virtual int on_snapshot_load(::braft::SnapshotReader* reader);
而 Go 语言中流行的 hashicorp/raft 框架也定义了类似的接口:
type FSM interface {
// Apply is called once a log entry is committed by a majority of the cluster.
Apply(*Log) interface{}
// Snapshot returns an FSMSnapshot used to: support log compaction, to
// restore the FSM to a previous state, or to bring out-of-date followers up
// to a recent log index.
Snapshot() (FSMSnapshot, error)
// Restore is used to restore an FSM from a snapshot.
Restore(snapshot io.ReadCloser) error
}
1.5 Raft Snapshot 调用时机
Save Snapshot 的触发时机通常有:
- 由定时任务触发。
- 当日志积累到一定数量后触发。无论是 Leader 还是 Follower,都需要 Save Snapshot 以压缩日志条目。
Load Snapshot 的时机主要有两个:
- Raft 节点启动时,需要加载最近一次的快照。
- Follower 节点日志落后 Leader 过多,且 Leader 已对落后的日志进行了压缩,此时 Leader 必须将完整的快照传输给 Follower。Follower 加载快照后,再 Apply 后续的日志。
1.6 注意:Raft FSM 调用的串行性质
在 braft 和 hashicorp/raft 中,框架调用用户状态机 FSM 的 Apply、Snapshot、Restore 等方法一定是串行的。这意味着:
Snapshot 操作类似于一种“中断”,其函数必须快速返回,否则会阻塞后续的 Apply 操作。- 在
Snapshot 过程中,无论直接或间接,都不能再次调用 FSM 本身的操作(例如执行一个写操作),否则会导致死锁。
正是这一性质引出了核心问题:究竟应该如何实现 Snapshot,才能在性能与磁盘 I/O 之间取得最佳平衡?
2 方案 A:锁定并全量 Dump
此方案适用于无法快速获取快照的内存状态机。其流程如下:
- Raft 框架调用
do snapshot。
- 用户锁住整个状态机,阻塞后续所有的客户端请求。
- 在内存中复制一份状态机的完整副本。
- 开启异步线程,将内存副本 dump 到 Raft 框架提供的 I/O Writer。
- 无需等待异步线程结束,立即解锁状态机,使
do snapshot 调用快速返回。
适用场景:
- 状态机数据量不大,全内存存储。
- 本地存储引擎本身不支持 MVCC 快照读。
不适用场景:
- 无法接受内存复制期间的请求阻塞。
- 数据量过大,容易导致 OOM。
这是一个最朴素的方案。如果数据量仅在数百 MiB 级别且对延迟不敏感,该方案完全可行。
3 方案 B:MVCC 引擎创建快照并异步迭代
根据 Raft 算法,日志必定是顺序 Apply 的。但生成快照的过程并不意味着必须完全阻塞后续日志的 Apply。许多框架之所以串行调用 FSM,是为了确保生成快照时,所有已提交的日志都已被处理,即快照的生成不应影响日志的应用顺序。
因此,如果底层使用了支持 MVCC 快照读的本地存储数据库(如 RocksDB),就可以在 Raft 触发 do snapshot 时,立即获取一个快照读句柄,随后立刻返回,不阻塞后续日志的 Apply。同时,利用这个句柄,异步地将所有 KV 对迭代并 dump 到 Raft 框架的 Data Writer 中。
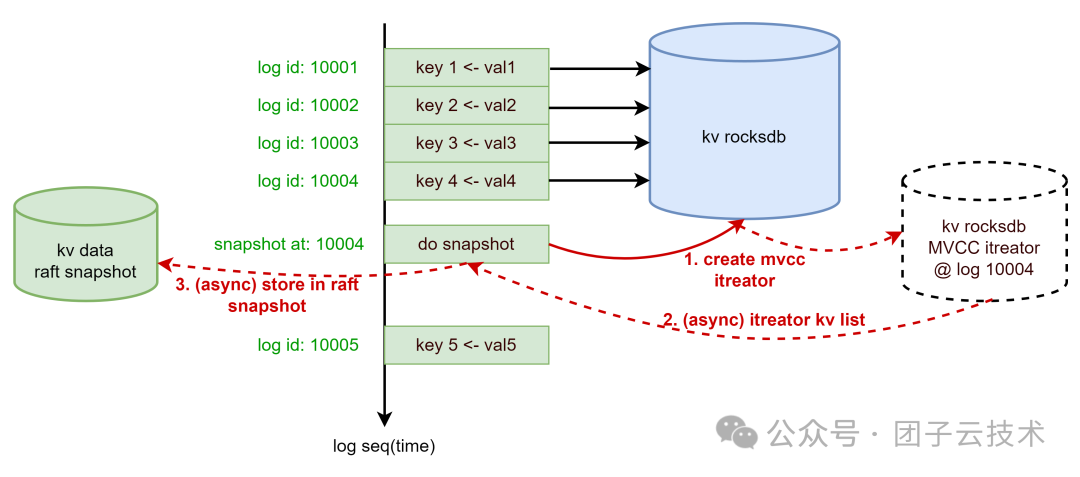
适用场景:
- 本地数据引擎原生支持 MVCC 快照读。
- dump 生成的 Snapshot 文件可直接作为数据库的物理备份。
缺点:
- 数据会被额外写入 Snapshot 文件,产生写放大和空间放大。
- 本质上,同一份 KV 数据分别写入了 Raft Log、Raft Snapshot 和 Local KV Database 三处。
- 当数据量极大时,空间放大和写放大问题将变得不可接受。
本方案是一种相当有效的折中方案。根据笔者调研,etcd 等系统采用了类似方式。其优点是利于备份、迁移和节点重建,管理直观。
4 方案 C:存储引擎即快照
更进一步,我们可以直接将本地 KV Database 视作快照本身,从根本上消除 Raft Snapshot 阶段的写放大与空间放大。
4.1 实现
考虑以下步骤:
- Raft 框架通知需要生成 Snapshot。
- 我们仅记录少量元数据(如当前 Apply Index、快照状态等)。
- Snapshot 函数立即返回,相当于向 Raft 框架写入一个“空”的快照。
虽然我们提交了一个“空”快照,但作为业务状态机,我们明确知道所有 KV 数据都切实存在于数据库中。相应地,在加载这个“空”快照时,只有两种情况:
情况一:自身进程重启,首次启动时加载 Snapshot
由于我们知道自己的 KV Database 一定存储了比上次快照点更新的数据,因此 Load Snapshot 时无需任何操作,直接在现有数据库基础上继续 Apply 后续日志即可。
情况二:Follower 加载 Leader 传输过来的 Snapshot
此时,我们重载 Raft 框架读取 Snapshot 的操作。将方案 B 中读取本地 Snapshot 文件,改为基于 Leader 本地 KV Database 进行全量快照读并流式传输。这对 Follower 是透明的,它接收全量数据后,可将其直接 ingest 到自身的 KV Database 中。
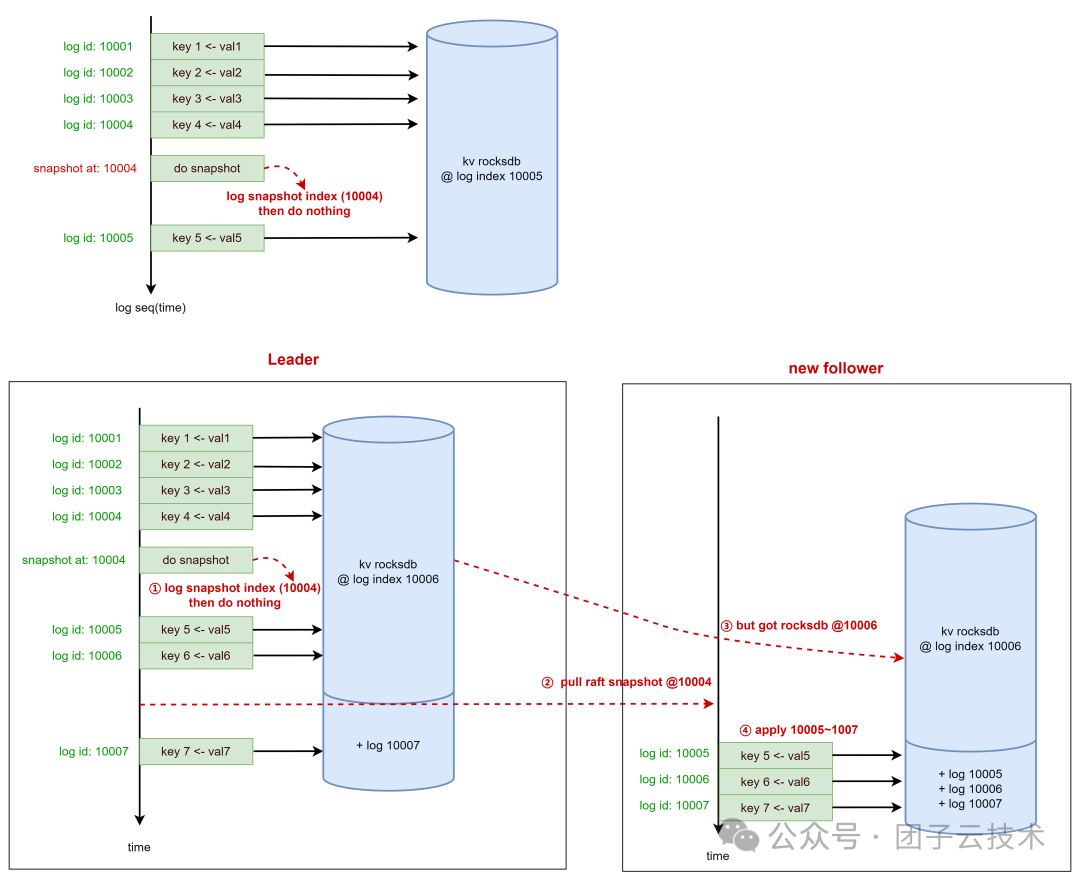 图:KV Database 即 Snapshot
图:KV Database 即 Snapshot
百度开源的 BaikalDB 数据面便采用了此种方式 [5][6][7]。
4.2 重要前提:FSM Log 必须是幂等的
方案 C 数据正确性的一个核心前提,是 KV 状态机的 Log 设计必须是幂等的。考虑以下场景:
- Leader 在
log_id=10004 处生成快照。
- Leader 继续提交并 Apply 日志
10005~10006。
- 一个新 Follower 加入,因日志差距过大,开始加载 Leader 在
log_id=10004 时的快照。
- 此时,新的写请求被提交并 Apply,产生
log_id=10007。
- Follower 加载的快照,其全量 KV 数据版本实际上是
@10006,但 Raft 框架认为该快照对应于 log_id=10004。
- Follower 加载快照后,Raft 框架会再次 Apply 日志
10005~10007。
因此,一条日志可能被多次 Apply 到状态机,这就要求 Log 的设计必须是幂等的。由于我们的 Log 本身就是 KV 的 Put、Del 操作,所以能保证数据的最终一致性。
4.3 优缺点
优点:
- 彻底消除了大数据量下 Snapshot 的写放大和空间放大,性能显著提升。
- 设计巧妙,直接利用了 FSM Log 的幂等性。
缺点:
- 实现复杂度较高,需要深入理解并严谨推演。
- 对于需要全量备份集群的场景,需另行设计备份机制。
5 小结
本文聚焦于 Raft KV 系统中 Snapshot 的实现。在简述 Raft 原理后,探讨了主流 Raft 框架提供的用户层接口及实现注意事项。随后,详细列举并分析了三种 Snapshot 实现方案的原理与优劣。
笔者认为,对于一般的元数据系统,若数据规模可接受,采用方案 B 更为直观和便于维护。对于海量数据存储节点,亟需减少 Snapshot 开销以提升性能时,可考虑实现更为巧妙的方案 C。
6 其他讨论
实现一个完整的 Raft KV 系统,还有诸多有趣议题值得探讨:
- 读请求是否需要经过 Raft 共识?如何保证线性一致性读?
- Raft 节点管理:是先添加节点再同步数据,还是先同步数据再加入集群?
- 扩展到 Multi-Raft 架构后,如何优化网络与存储层?
参考
[1] Raft 论文 - https://raft.github.io/raft.pdf
[2] Raft 算法解析 - https://www.calvinneo.com/2019/03/12/raft-algorithm/
[3] C++ raft 框架 baidu/braft https://github.com/baidu/braft
[4] Go raft 框架 hashicorp/raft https://github.com/hashicorp/raft
[5] baidu/BaikalDB https://github.com/baidu/BaikalDB
[6] braft 快照的实现 https://luobuda.github.io/2022/02/15/braft-snapshot%E5%AE%9E%E7%8E%B0/
[7] BaikalDB基于raft和rocksdb的快照机制的实现原理 https://github.com/baidu/BaikalDB/issues/105
 发表于 2025-12-8 00:33:37
|
查看: 188|
回复: 0
发表于 2025-12-8 00:33:37
|
查看: 188|
回复: 0
