今天,我们来深入探讨一下在大容量文件存储场景中扮演重要角色的技术——分布式文件系统 FastDFS。我们将从其架构设计、工作原理入手,并针对实际使用中可能遇到的几个核心问题进行剖析。
从场景出发:为什么需要分布式文件存储?
想象一下,当你的应用拥有海量用户,每天产生数以亿计的图片、视频或日志文件时,如何高效、可靠地存储并快速访问这些资源?单体服务器的磁盘空间和I/O性能很快就会成为瓶颈。这就引出了我们对分布式文件存储系统的需求。
分布式存储的演进之路
系统架构的演进往往伴随着业务规模的增长。最初,应用代码和文件资源可能都部署在同一台服务器上。
随着文件数量激增,存储压力会挤占服务器的计算资源。一个自然的想法是将文件服务器独立出来。
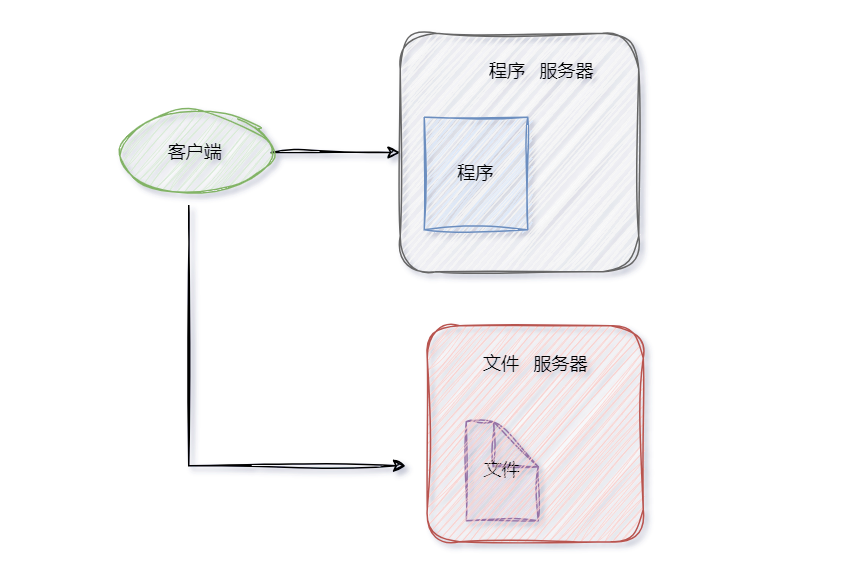
这实现了资源与业务逻辑的解耦,但单台文件服务器的容量和性能限制依然存在。根本的解决之道是使用多台服务器协同工作,也就是构建一个分布式系统。
主流分布式存储框架概览
市面上有多种分布式存储方案可供选择,它们各有侧重:

本文我们将聚焦于国产开源的代表之一——FastDFS。
FastDFS 详解
什么是 FastDFS?
FastDFS 是一个专为互联网应用设计的高性能、开源分布式文件系统。它主要解决了海量非结构化数据(如图片、视频、文档)的存储、同步和访问问题,尤其擅长管理海量小文件。
它的核心功能包括:
- 文件存储:支持存储海量数据文件。
- 文件同步:确保文件在系统内多个副本之间的一致性。
- 文件访问:提供上传、下载等标准文件操作接口。
核心架构与角色
FastDFS 的架构清晰地分为三层,各司其职:
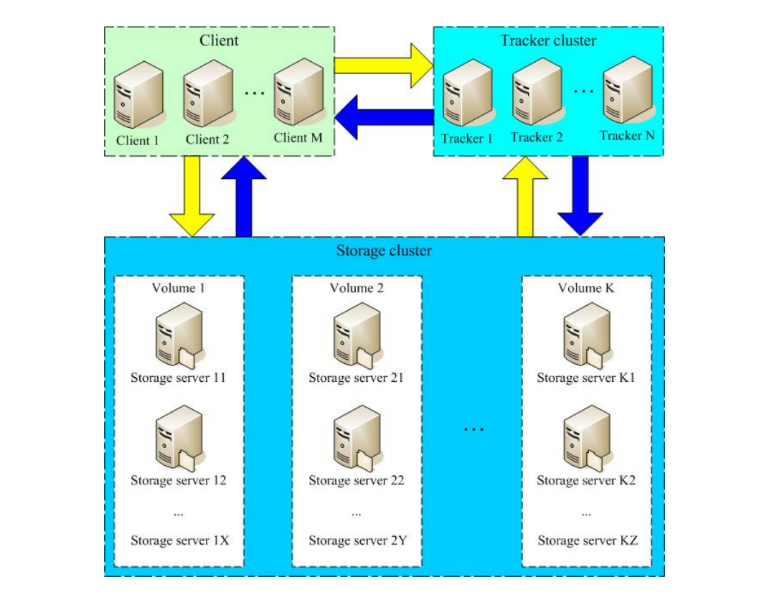
- Client (客户端):你的应用程序,通过调用 FastDFS 客户端 API 进行文件操作。
- Tracker Server (跟踪服务器):这是系统的“调度中心”。它不存储文件数据,而是在内存中维护整个存储集群的状态信息(如 Storage 分组、负载情况)。客户端首先连接 Tracker,由 Tracker 根据负载均衡策略返回一个可用的 Storage 地址。Tracker 本身可以集群部署,避免单点故障。
- Storage Server (存储服务器):这是实际存储文件的“仓库”。它负责文件存储、同步,并提供文件访问接口。同时,它还管理文件的元数据(Metadata),即文件的属性信息,以键值对形式存储,例如
width=1024。
一个 Storage 集群可以划分为多个 Group(卷),每个 Group 内可以包含多台 Storage 服务器。同一 Group 内的服务器存储相同的文件,互为备份,实现了冗余。
核心问题思考与原理剖析
1. 文件如何上传?
上传流程的核心是“由 Tracker 调度,客户端直连 Storage 写入”。
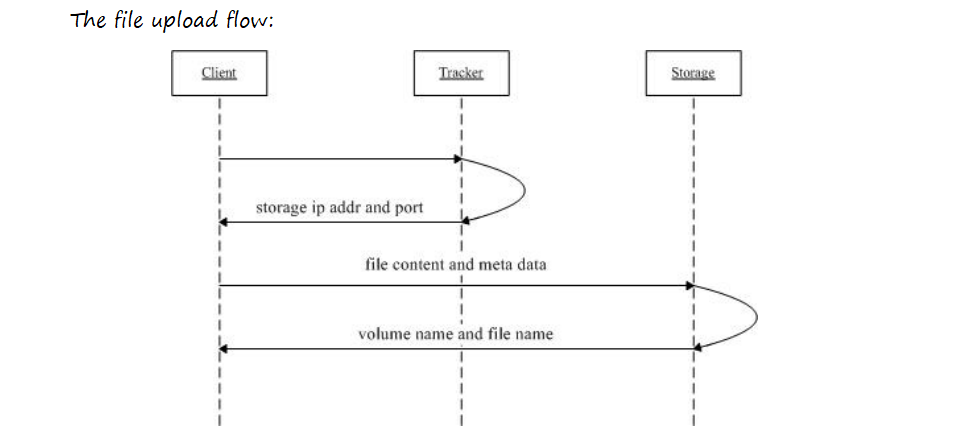
具体步骤:
- 客户端向任意一个 Tracker 发起上传请求。
- Tracker 根据预设策略(如轮询、选择空闲存储节点)选择一个 Storage Group,并返回该 Group 内一台 Storage 的 IP 和端口。
- 客户端直接连接到该 Storage 服务器。
- 客户端将文件内容和元数据(可选的附加属性)发送给 Storage。
- Storage 生成唯一的文件 ID(包含 Group 名、路径等信息)并存储文件,然后将其返回给客户端。
- 客户端保存此文件 ID,作为后续访问该文件的凭证。
2. 文件如何下载?
下载流程与上传类似,也是由 Tracker 定位,客户端直连 Storage 读取。
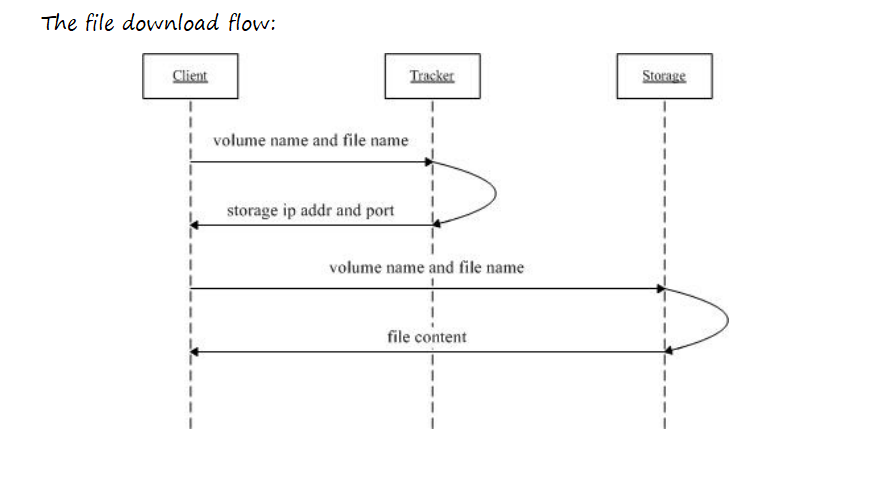
具体步骤:
- 客户端使用文件 ID(内含 Group 和文件名)向 Tracker 发起下载请求。
- Tracker 解析文件 ID,定位到文件所在的 Storage Group 和具体的 Storage 服务器,返回其 IP 和端口。
- 客户端直连该 Storage 服务器。
- 客户端发送文件 ID 请求文件内容。
- Storage 服务器读取本地文件并将其内容返回给客户端。
3. 如何保证高可用与数据可靠性?
FastDFS 通过多副本机制和分组存储来实现 高可用 和数据冗余。
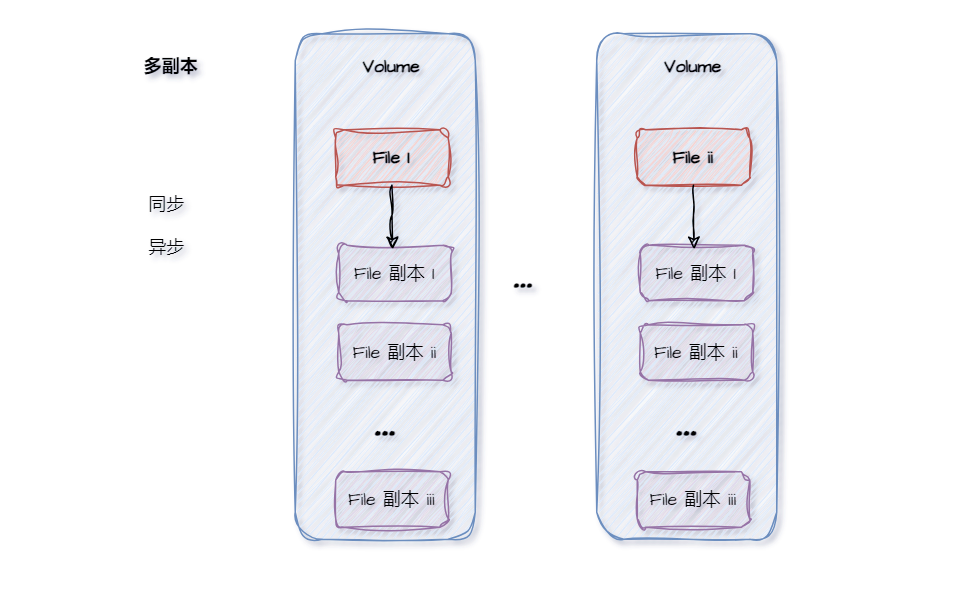
关键设计点:
- 副本位于同组:一个文件及其所有副本都存储在同一个 Group 内,不同 Group 之间资源隔离。
- 副本分布在不同机器:副本会存储在同组内不同的 Storage 服务器上,防止单台机器故障导致数据丢失。
- 同步机制:支持同步和异步两种复制方式,在数据一致性和写入性能之间提供权衡。
- 自动同步:当向 Group 内添加新的 Storage 节点时,系统会自动将已有文件同步到新节点。
4. 如何应对性能瓶颈与扩展?
FastDFS 的架构在设计之初就考虑了可扩展性。
- Tracker 集群:Tracker 可以轻易地横向扩展。增加 Tracker 节点可以分担调度压力,提升系统整体的并发处理能力。
- Storage 水平扩展:
- 垂直扩展(增加 Group):通过创建新的 Storage Group 来扩容,新文件可以存入新 Group,适合业务隔离或容量扩容。
- 水平扩展(Group 内增加节点):在已有的 Group 内增加 Storage 服务器,可以提升该 Group 的并发访问能力和存储容量。
总结与特性对比
FastDFS 以其简洁的架构、高效的性能和良好的扩展性,在众多互联网公司中得到了广泛应用。它特别适合图片、视频等海量小文件的存储场景。最后,我们通过一个简表来回顾其关键特性的优缺点:
| 特性 |
优点 |
缺点 |
| 架构设计 |
角色清晰,易于水平扩展,天然负载均衡 |
文件同步可能存在延迟(异步模式下) |
| 冗余备份 |
多副本机制,支持在线扩容,数据可靠性高 |
存储空间利用率有所牺牲(取决于副本数) |
| 高性能 |
C语言编写,网络通信模型高效,专为文件存取优化 |
单Storage节点性能受限于单机磁盘I/O |
| 功能特性 |
支持断点续传、文件属性、与Nginx无缝集成 |
原生不支持文件修改和删除(通常标记删除),无内置全文检索 |
希望这篇对 FastDFS 的解析能帮助你更好地理解其内部机制。如果你在构建自己的存储服务时遇到类似问题,不妨参考其设计思想。更多关于后端架构与分布式系统的深度讨论,欢迎访问 云栈社区 与广大开发者一同交流。
参考资料
- FastDFS官网地址(中文):http://www.csource.org/
- FastDFS官网地址(英文):http://code.google.com/p/fastdfs/
- 学习地址:http://bbs.chinaunix.net/forum-240-1.html
- 软件包下载地址:http://sourceforge.net/projects/fastdfs/files/
- 源码包下载地址:http://sourceforge.net/projects/fastdfs/files/
- 性能测试报告:https://www.jianshu.com/p/dd08821a2068
- FastDFS的Gitee主页:https://gitee.com/fastdfs100/fastdfs
|  发表于 2026-3-3 12:20:38
|
查看: 186|
回复: 0
发表于 2026-3-3 12:20:38
|
查看: 186|
回复: 0
