对于现代企业而言,灾难恢复(DR)早已不是一道可选题,而是一项必须落实的核心能力。真正的挑战往往在于,如何在有限的预算内,找到恢复速度与成本投入之间的最佳平衡点。
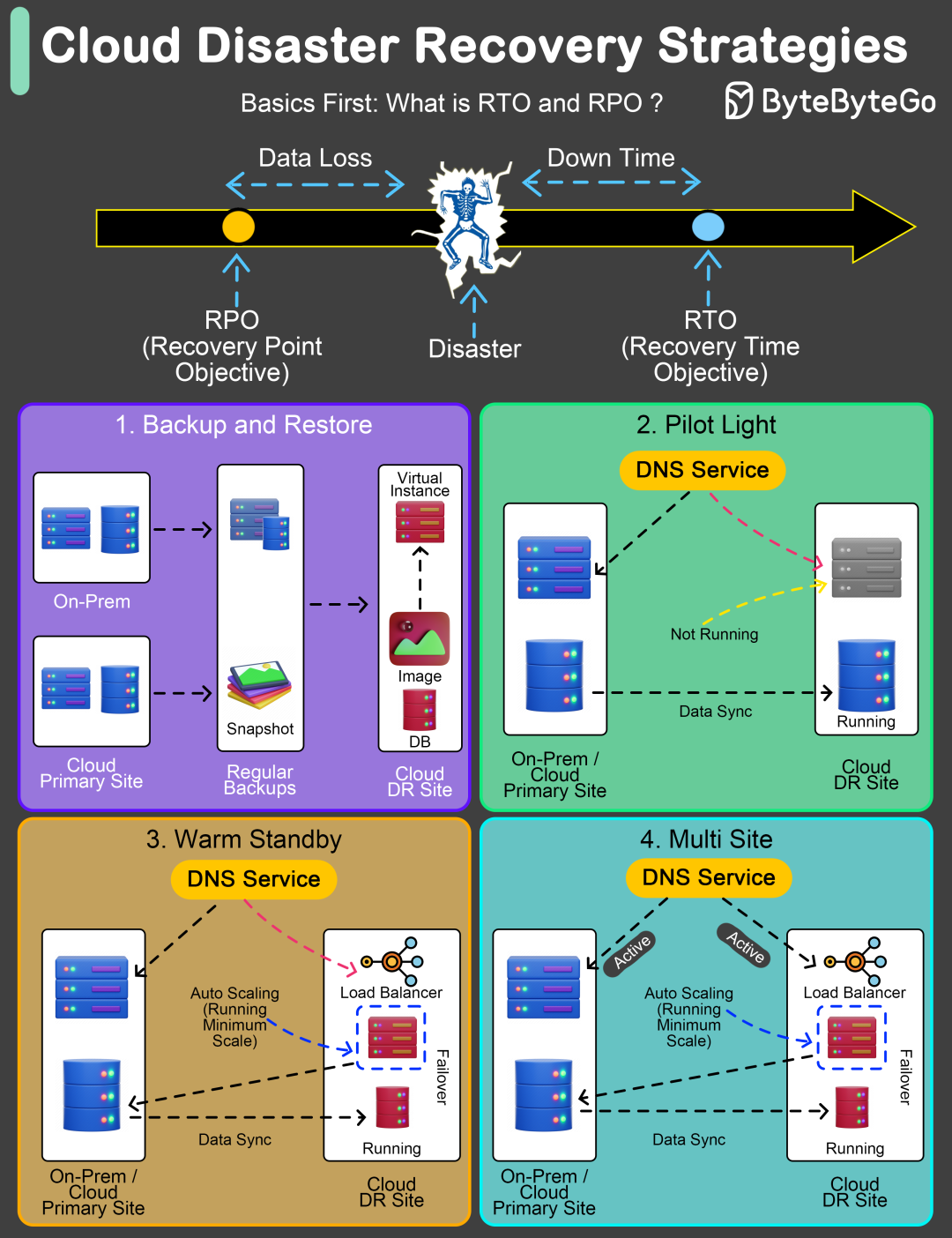
两个核心指标:RTO与RPO
在制定任何容灾计划前,必须先理解两个决定性的指标,它们是评估容灾方案等级与成本的基石。
RTO - 恢复时间目标
RTO指的是在灾难发生后,系统或业务最多允许中断多长时间。它直接回答了“我们需要多快恢复服务”这个问题。
- RTO = 1小时:意味着从故障发生到业务完全恢复,必须在1小时内完成,对恢复速度要求极高。
- RTO = 24小时:则表示业务可以容忍长达一天的停机时间,次日恢复也在可接受范围内。
RPO - 恢复点目标
RPO定义了你能承受的最大数据丢失量。它回答的是“我们能丢失多少数据”。
- RPO = 0:这是最严格的要求,意味着不能丢失任何数据,通常需要实时或准实时的数据同步。
- RPO = 1小时:表示可以接受丢失最近1小时内产生的数据,恢复时数据将回退到1小时前的状态。
核心关系:RTO和RPO的值越小,对技术架构和资源投入的要求就越高,相应的实现成本也呈指数级上升。明确业务对这两个指标的具体要求,是选择容灾策略的第一步。
四种主流的云容灾策略
理解了RTO/RPO,我们来看四种常见的云容灾实现模式,它们的恢复能力与成本由低到高排列。
1. 备份与恢复
这是最基础、成本最低的策略。其核心是定期将数据和系统状态备份到异地(如云存储),灾难发生时再从中恢复。
- 典型RTO:数小时至数天(恢复速度较慢)。
- 典型RPO:数小时(取决于备份周期,如每日一备则最多丢失一天数据)。
- 成本:最低,主要为存储和偶尔的恢复计算资源费用。
- 适用场景:非核心的内部工具、测试环境、可长时间停机的应用。
- 常用工具:AWS Backup, Azure Backup, 各类云厂商的快照服务。
2. 指示灯模式
这种模式得名于飞机驾驶舱的指示灯——平时不亮但随时准备亮起。在容灾语境下,指在灾备站点预先配置好核心基础设施(如数据库、网络),并保持数据同步,但应用服务不运行,灾难时再快速启动整个环境。
- 关键做法:
- 数据库:通过主从复制,在灾备站点维护一个处于待机状态的从库。
- 应用服务器:镜像、配置已就绪,但实例处于关机状态。
- 数据:接近实时同步。
- 典型RTO:分钟级到小时级(启动实例和服务需要时间)。
- 典型RPO:分钟级(取决于数据同步频率)。
- 成本:中等,需为待机的基础设施(如数据库实例)付费。
- 适用场景:中等重要性的业务,可以接受短时间中断。
3. 温备
温备是“指示灯”模式的升级版。在灾备站点,一个完整且与生产环境兼容的应用堆栈始终以最小规模运行。所有服务(应用、数据库)都处于活动状态,只是资源配置较低。
- 关键做法:
- 灾备站点所有服务持续运行。
- 资源按最小规模配置(如使用小规格实例)。
- 数据实时或准实时同步。
- 典型RTO:分钟级(只需扩容资源即可承接流量)。
- 典型RPO:分钟级(数据同步延迟小)。
- 成本:中高,需要为持续运行的小规模环境付费。
- 适用场景:对恢复时间有明确要求的关键业务。
4. 热备/多活
这是最高级别的容灾架构,也称为多活。业务流量同时分布在两个或多个地理位置的数据中心,它们都处于活跃状态并共同处理请求。
- 关键做法:
- 多地域部署完整、对等的应用环境。
- 通过全局负载均衡器智能分发用户流量。
- 任何一个地域故障,流量会被无缝切换到其他健康地域。
- 数据双向或多向同步,保证一致性。
- 典型RTO:接近零(分钟级内完成切换,用户几乎无感知)。
- 典型RPO:秒级甚至为零(数据近乎实时同步)。
- 成本:最高,需要为多套完整且满载运行的基础设施付费。
- 适用场景:金融交易、核心电商平台等对连续性和数据一致性要求极高的业务。
四种容灾策略对比
为了更直观地对比,我们可以通过下表来快速决策:
| 策略 |
典型 RTO |
典型 RPO |
成本 |
适用场景 |
| 备份恢复 |
小时 - 天 |
小时 |
低 |
非核心应用、内部系统 |
| 指示灯 |
分钟 - 小时 |
分钟 |
中 |
中等重要性业务 |
| 温备 |
分钟级 |
分钟级 |
中高 |
关键业务 |
| 热备/多活 |
分钟级内 |
秒级 |
高 |
金融、核心电商等 |
实施建议与最佳实践
制定策略后,有效的执行同样重要。
1. 采用分层策略
不必对所有业务“一刀切”。根据业务重要性,混合使用不同策略以优化成本:
- 核心业务:采用热备/多活。
- 重要业务:采用温备。
- 普通业务:采用指示灯模式。
- 内部工具:采用定期备份与恢复。
2. 定期演练
容灾计划绝不能只停留在文档上。必须定期(如每季度)执行真实的容灾演练,测试切换流程、验证RTO/RPO是否达标、并让运维团队熟悉应急操作。只有经过演练验证的计划才是可信的。
3. 建立完善的监控与自动化
- 监控:持续监控跨区域的数据复制延迟、网络健康状况和灾备站点资源状态。
- 告警:设置关键指标的告警阈值,确保故障能被第一时间发现。
- 自动化:尽可能将故障切换流程自动化,减少人工干预带来的延迟和错误。利用云原生的编排工具可以很好地实现这一点。
容灾的本质是为业务连续性购买“保险”。在云栈社区的许多讨论中,大家普遍认为,明智的做法是根据业务价值精确评估所需的“保额”(RTO/RPO),然后选择性价比最高的“保险方案”(容灾策略),并记得定期“续保”和“验证保单”(演练与优化)。 |  发表于 2026-4-13 06:41:09
|
查看: 147|
回复: 0
发表于 2026-4-13 06:41:09
|
查看: 147|
回复: 0
