
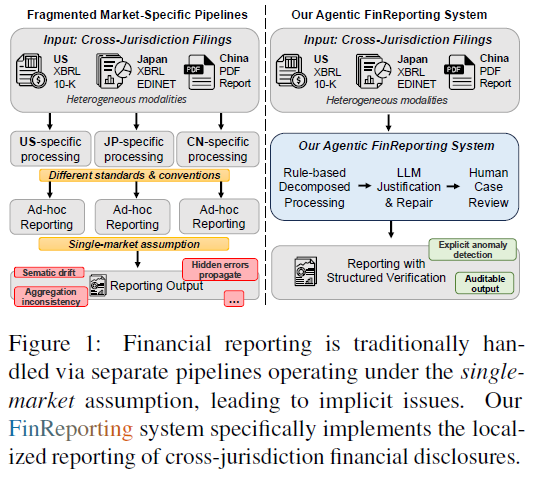
当前许多金融报告系统会利用大语言模型(LLM)来提取和总结企业披露信息,但这类系统大多是针对单一市场设计的,并未充分考虑不同司法管辖区(如美国、日本、中国)在报告结构、会计准则上的巨大差异。当需要处理跨司法管辖区的报告时,就会面临语义对齐困难、结果难以验证等棘手问题。
为此,来自多个顶尖研究机构的研究者们提出了一套名为 FinReporting 的系统。这是一种用于跨司法管辖区财务披露统一与本地化报告的 智能体工作流。它的核心是构建一个基于通用报告标准的规范金融本体,并在美、日、中三大市场进行实施和验证。
摘要
财务报表是投资者评估公司状况和业绩的基础。如今,LLM(大语言模型)的出现推动了财务报告自动化,能够减轻阅读负担,辅助投资决策。然而,现有的自动化系统大多基于“单一市场”的假设,对于需要进行全球投资的用户并不友好。
投资者在理解外国公司财报时会遇到双重摩擦:一方面,各国金融基础设施差异巨大,投资者很难正确解读;另一方面,传统金融数据供应商依靠人工提取和验证,成本高、难扩展,导致小投资者难以获取数据。
真正的跨司法管辖区报告本地化,不仅仅是翻译或格式转换。不同地区的会计分类和汇总惯例差异,可能导致语义漂移和汇总结果不一致。因此,一个可靠的本地化系统,必须支持结构化验证和问题修复。
FinReporting 正是为了解决这一问题而生。它通过构建统一的规范金融本体,将端到端的本地化过程分解为多个可审计的步骤,包括文件获取、报表识别、信息提取、规范映射等,并在步骤之间嵌入结构化的验证机制。这套工作流不仅提供了可审计的基础设施,还展示了一个交互式平台,方便用户加载特定市场文件、查看提取的报表、并导出本地化的财务报告。
相关工作
在金融自然语言处理(NLP)领域,长期研究集中于从企业披露文本中挖掘信号,用于市场预测和风险评估。近年来,研究范围扩展至财务报告的数值推理与问答,并出现了 FinQA 等基准数据集。同时,为了加强领域适配,业界也提出了 BloombergGPT 等金融导向的基础模型与评估套件。
现代金融披露系统多采用 XBRL(可扩展商业报告语言)来实现机器可读的报告,例如美国 SEC 就提供了相关的结构化数据集。近期的研究也提出了用于提取和结构化金融事实的自动化管道,以及基于大语言模型的查询接口。
然而,不同市场的披露实践和标准千差万别。现有管道大多基于单一市场假设,难以通用。FinReporting 则明确地对跨司法管辖区的异质性进行了建模,并将结构化验证直接嵌入报告生成流程,从而实现在不同申报制度下的、可审计的本地化报告。
FinReporting 系统详解
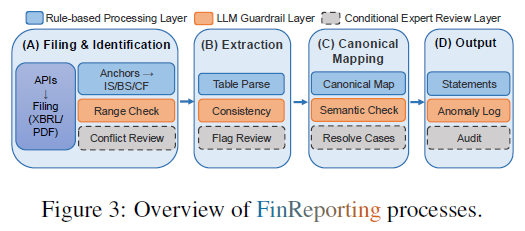
FinReporting 的核心思想是将复杂的财务报告生成过程,划分为一系列可审计的步骤(文件获取、报表识别、提取、规范映射及输出),并在每个步骤之间插入结构化的验证机制(例如 LLM 论证和条件化的人工专家评审),以此来保证中间输出的质量。
系统采用三层处理设计:
- 基于规则的确定性处理层:生成可重现的初始结果。
- 带严格护栏的 LLM 验证/修复层:利用大语言模型进行有约束的验证和修复。
- 针对高影响案例的轻量级人工评审层:处理系统无法自动解决的疑难案例。
基于规则的处理层
- 文件获取和报表识别:根据不同管辖权,系统采取不同策略。对于 XBRL-native 市场(如美国、日本),直接从官方数据源加载标记好的结构化事实;对于 PDF-centric 市场(如中国),则需要先定位年报文件,并检测核心报表(如利润表、资产负债表)所在的页码范围,从而确定报表级的上下文包。
- 提取:在 XBRL-native 市场,系统根据报告上下文选择正确的事实并导出;在 PDF-centric 市场,则需要进行文档分解、表格解析等复杂操作,并为每个提取项添加状态标签(如正常、缺失、解析错误等)。
- 规范映射:借助一个全局金融本体,将不同市场提取出的项目映射到统一的规范模式中,实现跨市场的语义对齐。
- 输出:最终输出在统一规范模式下的本地化财务报表,并附带记录了所有异常情况和系统决策的日志与审计跟踪文件。
LLM 护栏层
FinReporting 创新性地将大语言模型定位为 “有界验证器” ,而非传统的自由形式提取器。这种设计可以有效防止未被检测的错误在流程中传播。
在系统的各个阶段,都会结合预定义的业务规则约束与 LLM 的推理能力,对中间输出进行验证。当 LLM 拥有足够证据时,它可以提出修复方案并给出可追溯的解释。验证器的决策空间被限制在三种:KEEP(保持)、REPAIR(修复)、NEED_REVIEW(需要人工审核)。只有在满足所有预设护栏条件时,系统才会自动应用修复;否则,案例将被标记为 NEED_REVIEW 并移交下一层处理。所有的决策及其证据、失败原因都会被详细记录,确保最终的每一项声明在逻辑上连贯,并且在语义上忠实于源文件。
条件专家评审层
系统支持对标记为 NEED_REVIEW 的特殊情况,或检测到重大差异时,启动针对性的人工审核。审核人员可以高效地检查系统提供的审计跟踪和证据片段,以解决冲突。此外,系统还提供了结构化的评估模板和对比视图,帮助量化验证和修复步骤对信息提取完整性和一致性带来的影响。
实验与评估
实验设置
- 评估协议:评估主要针对 FinReporting 对年度报告中核心财务报表字段的处理能力。系统为 18 个核心项目生成报告,并提供完整的审计追踪。当证据不足时,系统会明确标记,提示需要人工审核。
- 评估数据:数据来自美国 SEC EDGAR、日本 EDINET 和中国公开的 PDF 年报。每个市场选择 20 家公司用于规则开发和标注,另外 10 家“挑战性”公司用于最终评估,共计 90 家公司。所有标注均经过金融专家验证。
- 评估指标:
- 报告填充率(FR):非空输出字段的比例。
- 冲突率(CR):需要提交人工审核的字段比例。
- 准确率(Acc):经审核的字段与人工标注对比的正确率。
实证分析
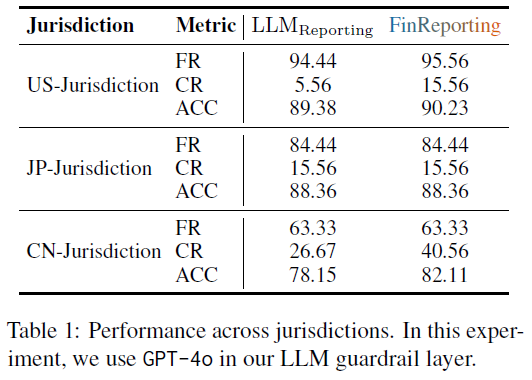
- 与传统 LLM 报告流程对比:如下表所示,在美国、日本、中国三个市场,FinReporting 的表现均优于或等同于普通的 LLM 报告流程。性能差异主要源于源数据的结构和标准化程度:美国数据机器可读性高、模式一致;日本数据的标签和报告实践存在一定差异;而中国数据需要从 PDF 报告中提取和重构信息,噪声更多,误差也更大。
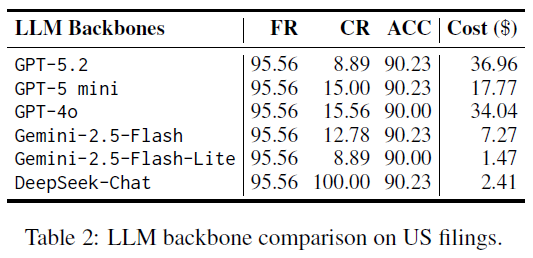
- 骨干 LLM 模型选择:在美国市场下的测试表明,不同的大语言模型在整体填充率(FR)上表现一致,这说明覆盖率主要由任务流程设计决定,而非模型本身。一个有趣的发现是,一些更小、更高效的模型(如 Gemini-2.5-Flash-Lite)在精度上与更强的模型相当,但成本显著降低,这对于生产部署非常有吸引力。
示例应用:交互式演示系统
团队开发了一个轻量级的网页版演示系统,供金融分析师、跨市场投资者和研究人员交互式地探索 FinReporting 提取的财务报表。
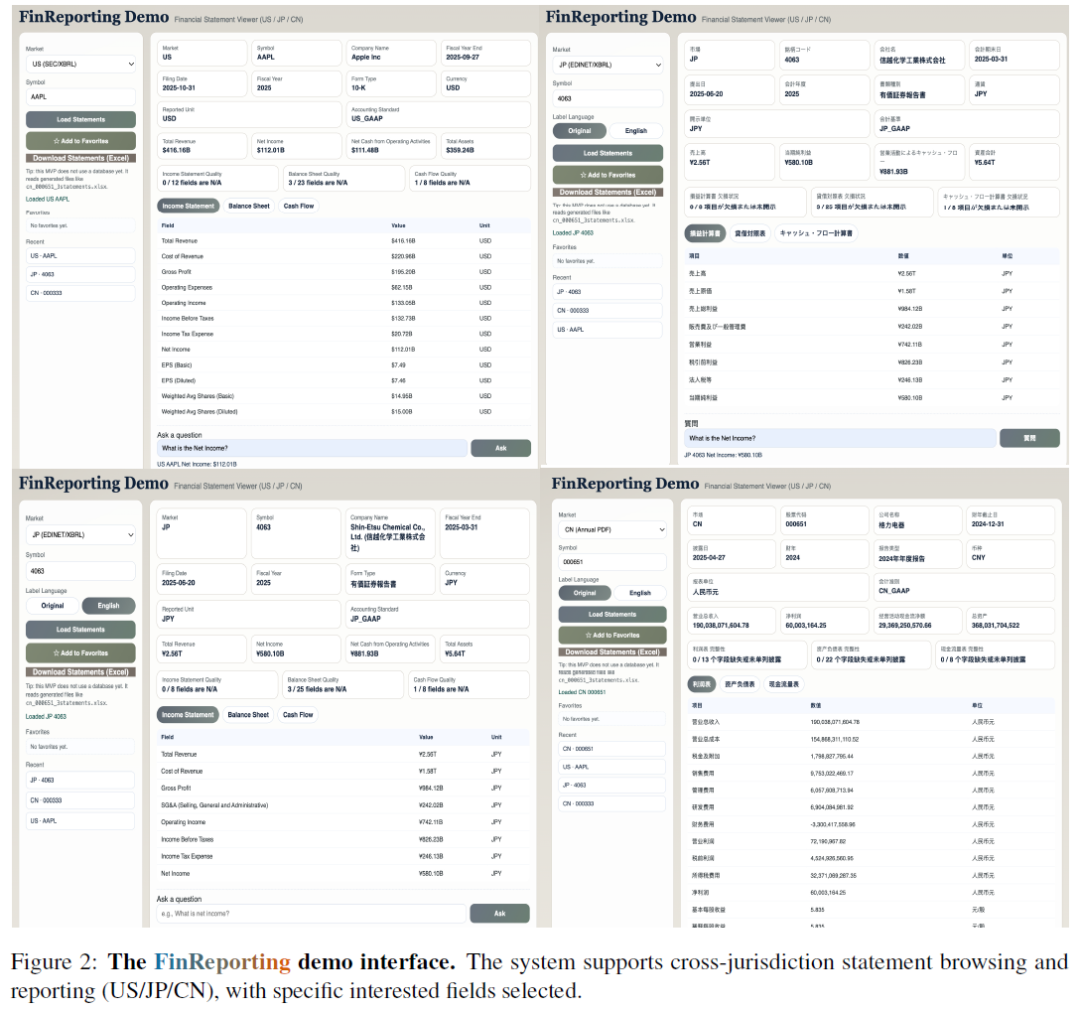
- 概览:用户可以选择市场(美、日、中)和公司。界面以标签页形式清晰展示损益表、资产负债表和现金流量表,并突出显示总收入、净利润等关键指标。
- 统一模式和 QA:提取的输出会按照统一模式进行归一化,同时保留市场特定的标签和货币单位。演示系统还提供了一个简单的问答(QA)模块,可以从归一化的数据中直接回答关于高频指标的问题,无需手动扫描原始工作表。
- 质量和审计信号:审计性是主要设计目标。系统定义了统一的状态本体(OK、MISSING、PARSE_ERROR、NOT_APPLICABLE),并在界面中直观地报告缺失字段的数量。用户还可以下载结构化的 Excel 工作簿,用于离线验证和进一步分析。
- 实现:原型是一个无数据库的 Web 服务,后端用 Python 实现,直接读取批处理管道生成的结构化 Excel 结果文件,确保与实验结论一致。前端是轻量级静态页面,支持一键本地启动或远程访问。
总结
FinReporting 提出了一种新颖的、基于智能体工作流的跨司法管辖区财务报告解决方案。它通过引入规范化的文件处理流程、将复杂任务分解为可审计的阶段,有效解决了全球财务分析中的一个实际难题。
与自由形式的 LLM 提取管道不同,FinReporting 将 LLM 作为受严格约束的验证器来使用,在证据不足时果断交由人工审查。这种设计实现了透明、可审计的跨市场报告,能够主动发现异常,并提供了一套可扩展的基础设施,减少了对人工数据整理的依赖,同时降低了因隐藏的结构性错误给下游模型带来的风险。
未来,这项工作可以朝多个方向拓展:扩大司法管辖区的覆盖范围、丰富规范本体的内容、扩展验证机制的应用场景,以及增强系统在处理格式不佳的 PDF 文件时的鲁棒性。对于希望深入理解其技术实现细节的开发者,相关的论文和代码是宝贵的学习资源。对这类结合人工智能与大数据处理的实际应用感兴趣的读者,也可以在 云栈社区 找到更多相关的讨论与分享。
 发表于 2026-4-13 06:43:51
|
查看: 107|
回复: 0
发表于 2026-4-13 06:43:51
|
查看: 107|
回复: 0
