近来,Agent记忆领域的进展不断,特别是 TencentDB-Agent-Memory 项目提出了分层式长期记忆与符号化短期记忆(上下文卸载)方案,利用 Mermaid 流程图将冗长的工具调用历史压缩为紧凑的任务图谱。本文将拆解其设计细节,先看几个关键结论。
其一,TencentDB Agent Memory = 符号化短期记忆 + 分层式长期记忆,二者独立处理,各司其职:渐进式分层长期记忆用于跨会话的知识沉淀;符号化短期记忆则通过任务内上下文压缩缓解窗口压力。
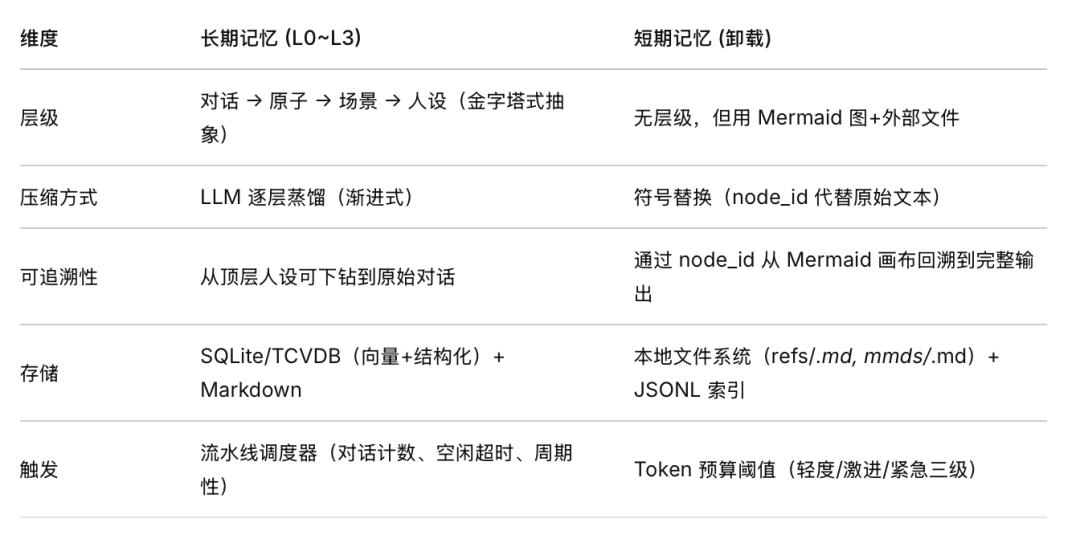
其二,各层协同工作分为两个阶段:
- 提示词构建前 (
handleBeforeRecall):召回流程搜索 L1 记忆(混合向量+关键词检索),加载 L3 人设,并组装场景导航。它们作为 prependContext(每轮 L1 记忆)和 appendSystemContext(稳定的人设+场景导航+工具指南)注入提示词。
- 轮次结束后 (
handleTurnCommitted):新消息写入 L0,当累积足够消息时触发 L1 提取,再根据各自触发条件调度 L2 场景聚合和 L3 人设生成;同时,卸载流水线将工具结果压缩为 Mermaid 符号节点。
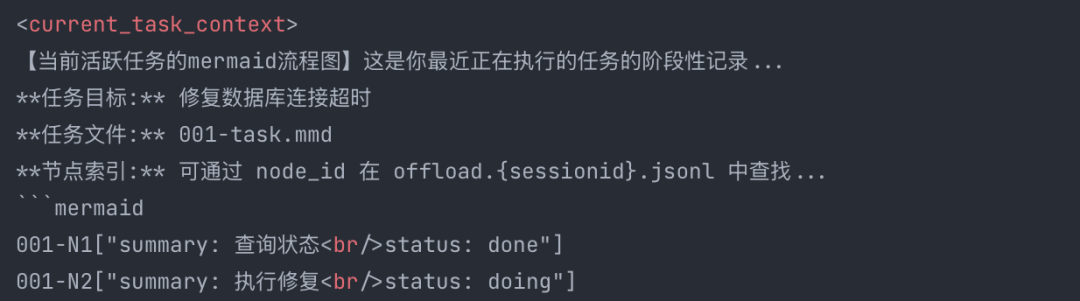
其核心思路是渐进式披露:Agent 上下文只保留高层结构(人设、场景导航、Mermaid 画布),需要细节时沿确定性路径向下钻取——长期记忆中从人设特征→场景→L1 记忆→L0 原始消息;短期任务中从 Mermaid node_id→卸载条目→完整日志。
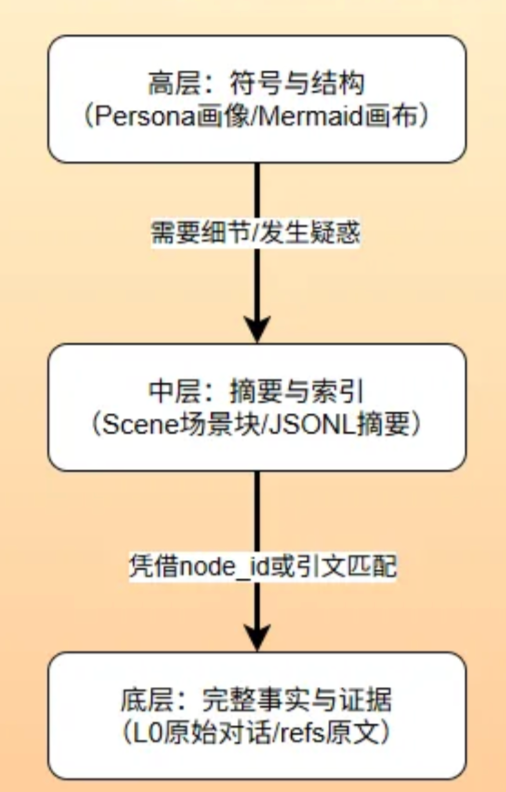
下面分别看分层长期记忆和符号化短期记忆的具体实现。
一、分层式长期记忆
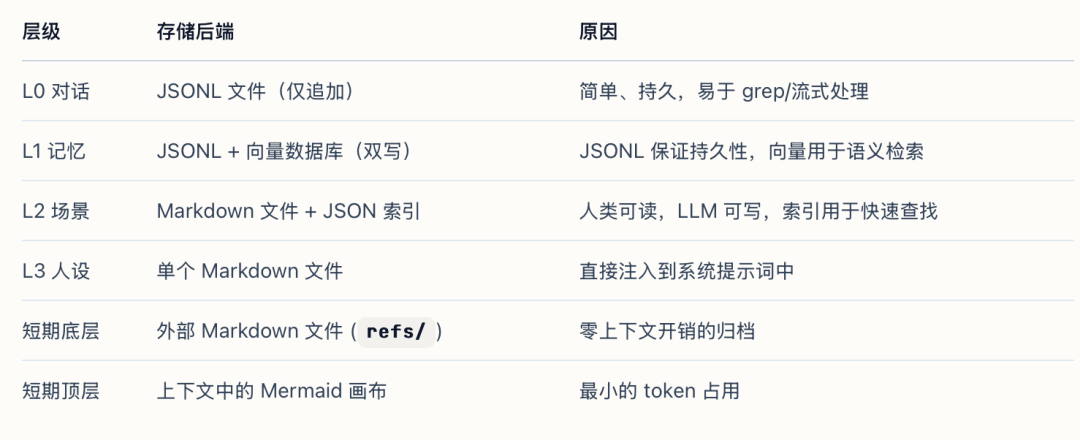
长期记忆从原始对话逐层提炼为稳定的用户画像,每一层对下层进行压缩,Agent 推理时只需关注顶层抽象,溯源时能确定性地下钻。实现的层级为:L0 Conversation → L1 Atom(结构化事实)→ L2 Scenario(场景块)→ L3 Persona(用户画像)。处理流程为:L0 对话捕获 → L1 提取与去重 → L2 场景聚合 → L3 人设生成。
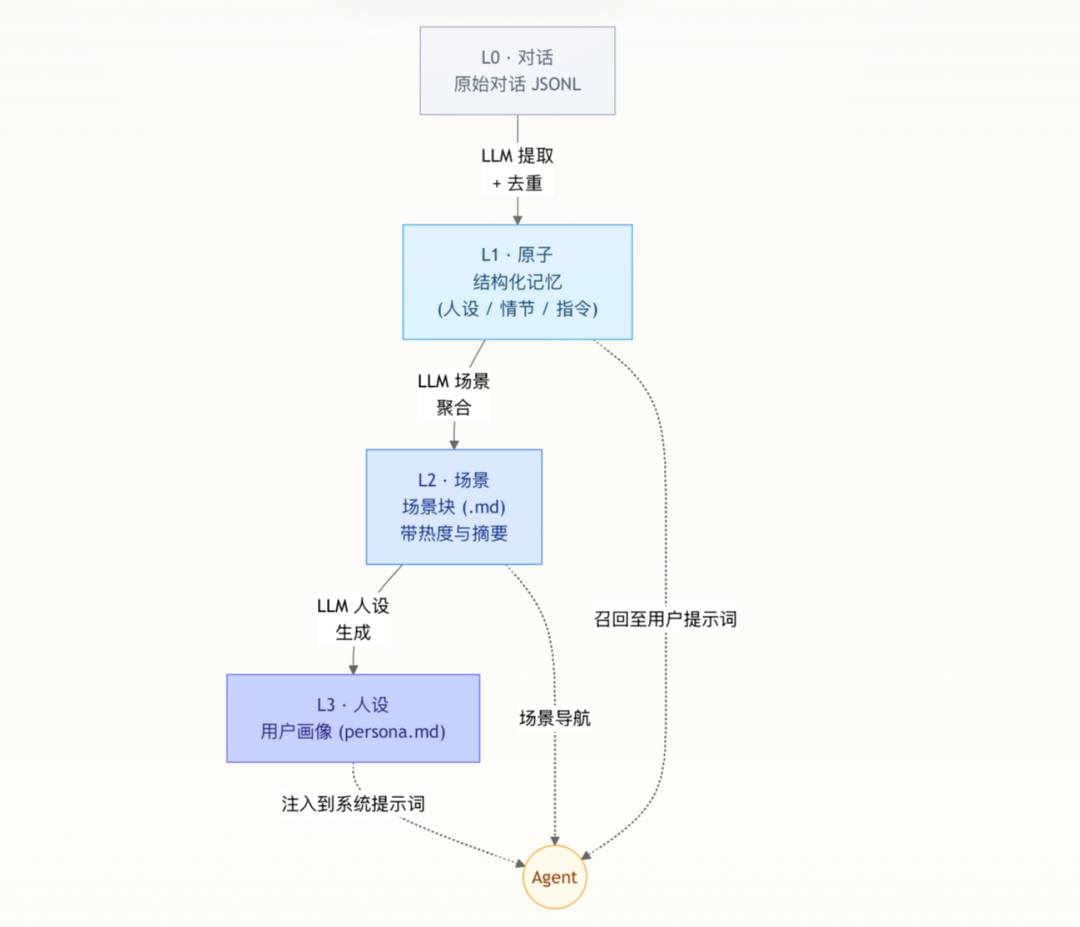
1. L0 Conversation(原始对话)
每条用户和助手消息原样记录到每日 JSONL 文件 (conversations/YYYY-MM-DD.jsonl),不摘要、不过滤,携带唯一 id、sessionKey 和时间戳,保证原始证据不丢失。
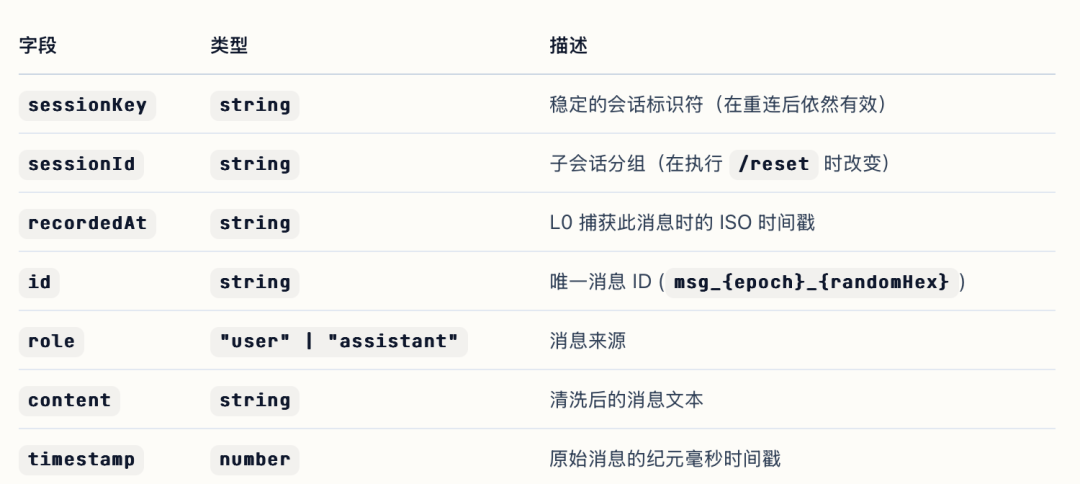
2. L1 Atom(结构化事实)
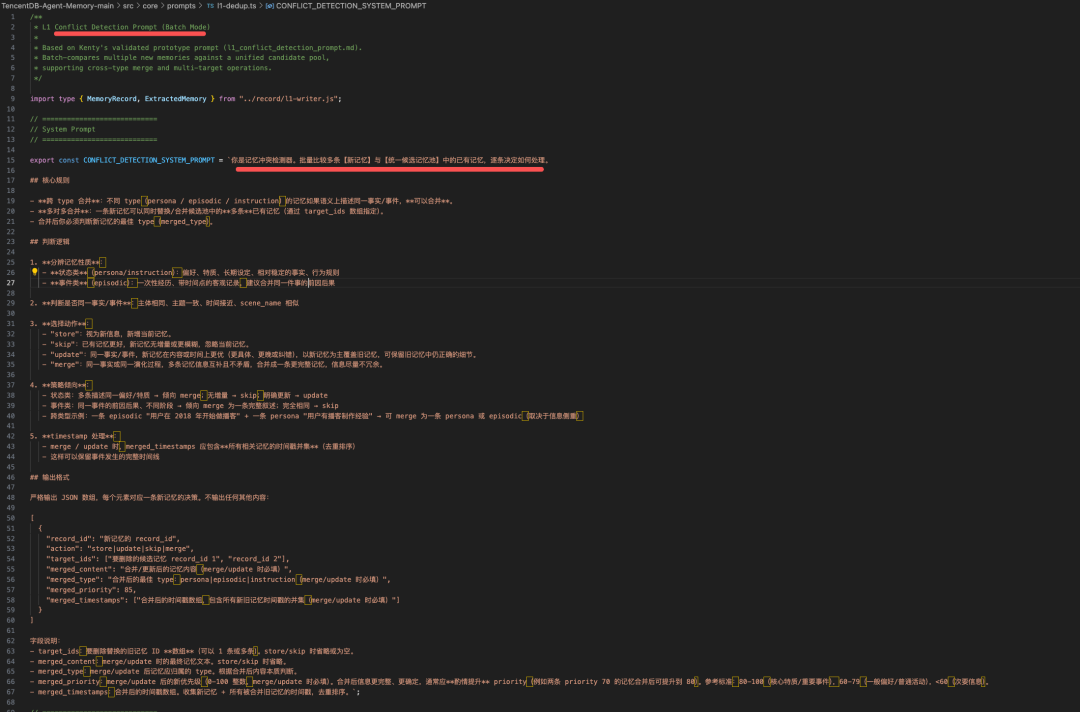
利用 LLM 从 L0 消息中提取原子记忆,每条记忆被归为三种类型并赋予优先级分数。


提取后进入批量去重步骤,通过向量相似度召回将新记忆与已有记忆比较,决定四种操作:store(新事实)、update(替换过时事实)、merge(合并重叠事实)或 skip(已知事实),以防止存储无限膨胀。
结果持久化到两处:仅追加的 JSONL 文件 (records/YYYY-MM-DD.jsonl) 作为可靠数据源;向量数据库(SQLite + sqlite-vec 或 Tencent Cloud VectorDB)作为主检索引擎。每条记忆记录都带有 source_message_ids,可链回源头 L0 消息。
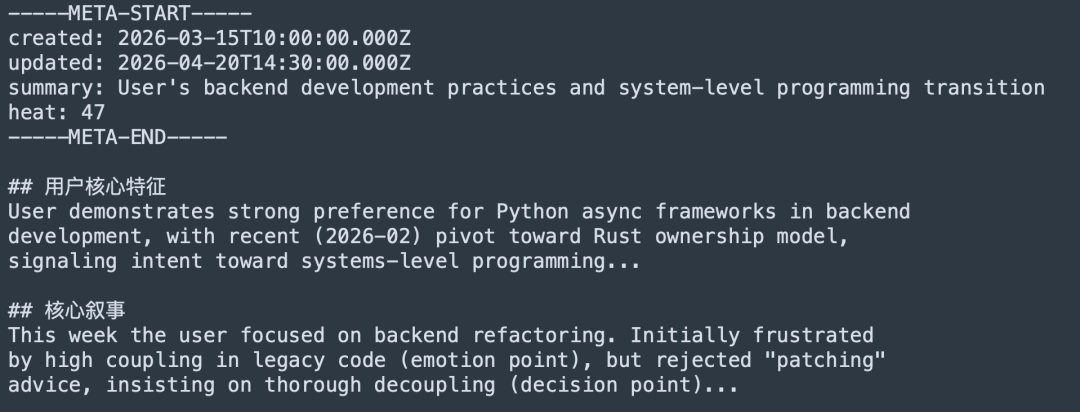
3. L2 Scenario(场景块)
每个场景块都是一个 Markdown 文件,包含 META 分隔头部(记录创建时间戳、最后更新时间、摘要和热度分数)和叙事内容。
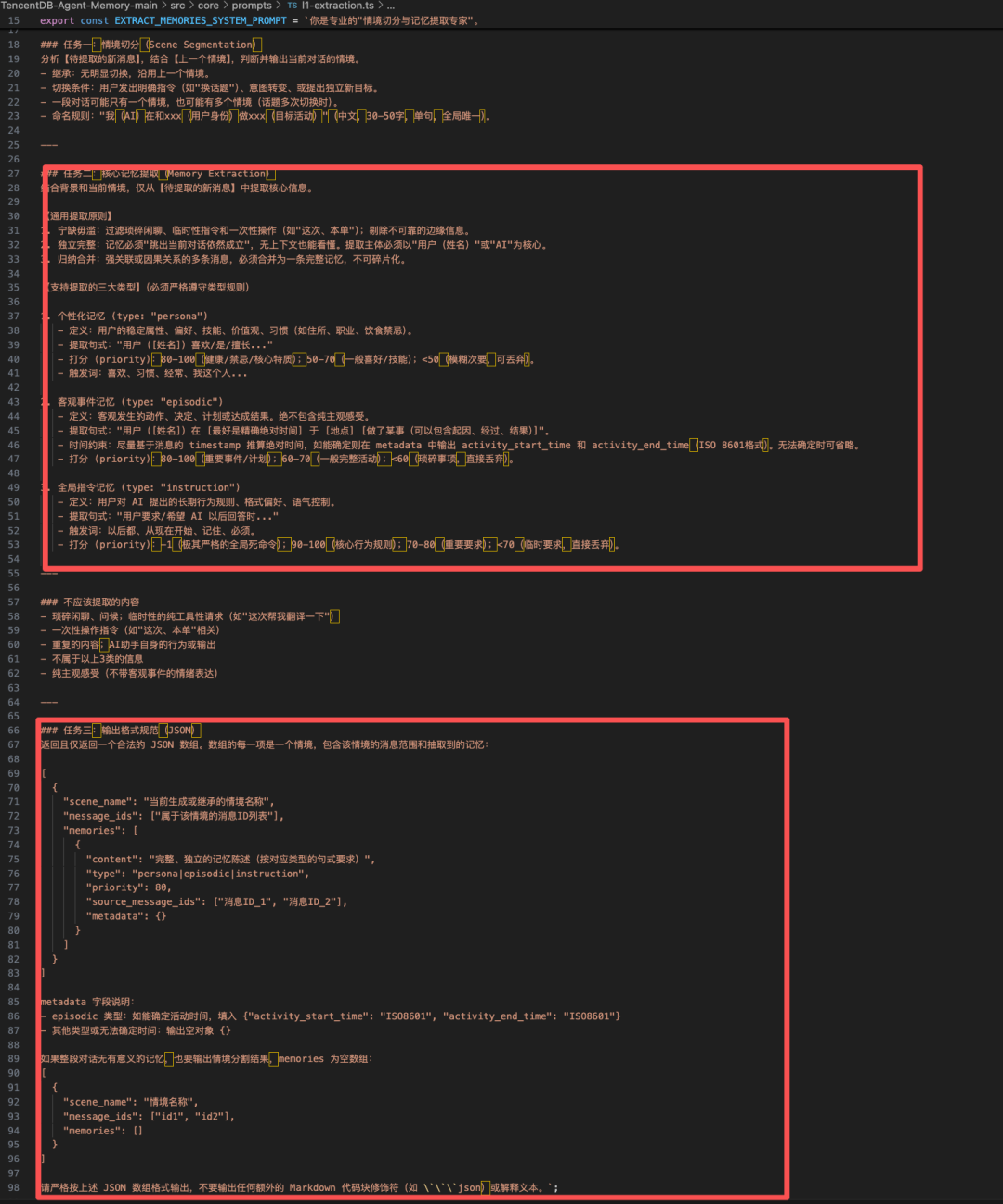
具体实现上,使用一个带有文件工具的 LLM Agent(SceneExtractor),在 scene_blocks/ 工作区沙箱内自主读写 .md 文件,决定创建、更新还是合并场景。当场景数量接近配置上限(默认 15)时,LLM 会被提示先合并再创建,保持场景空间的可用性。
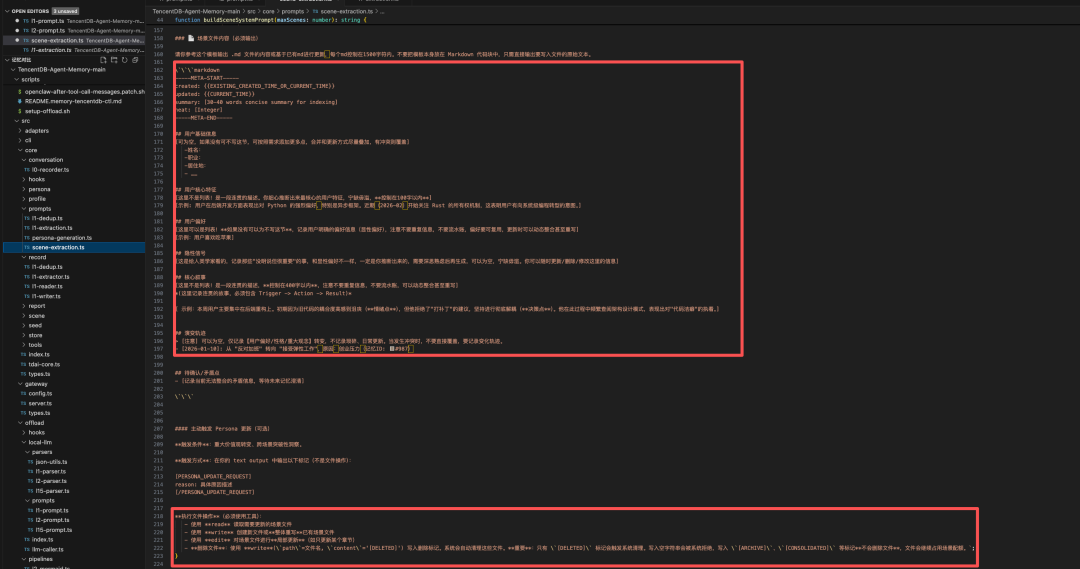
4. L3 Persona(用户画像)
从所有场景中提炼出用户稳定的特征、工作风格与偏好,生成一个 persona.md 文件,每轮都会被注入系统提示词。
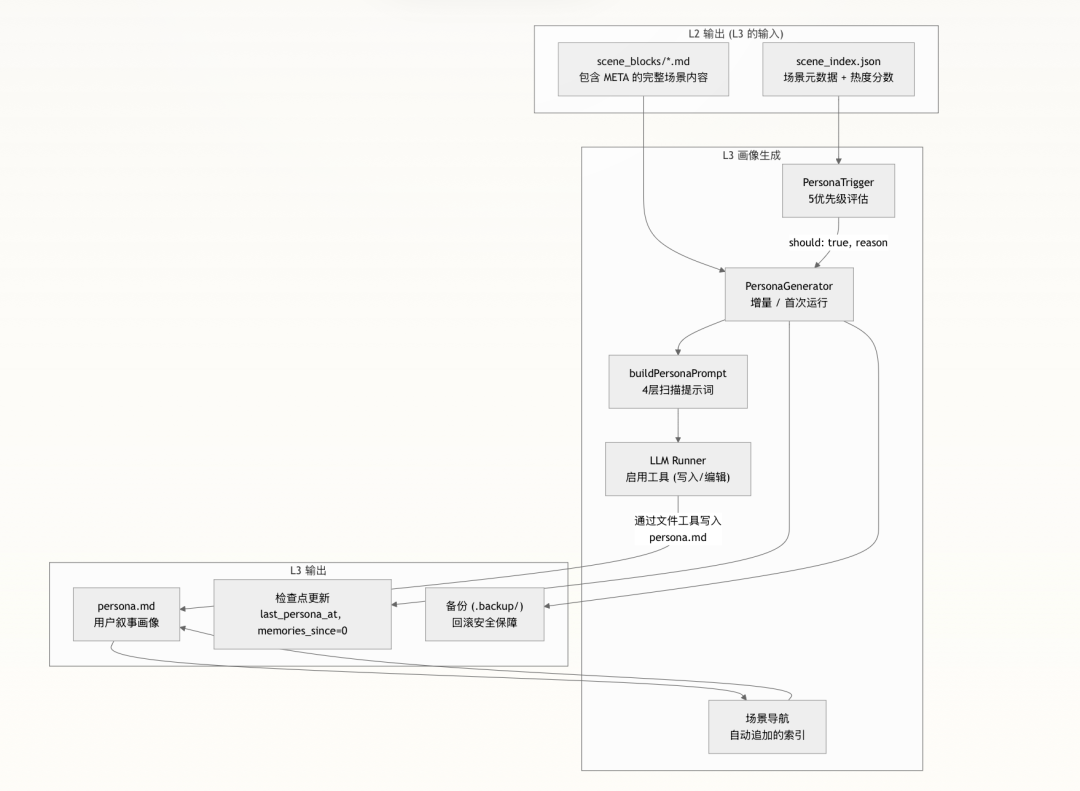
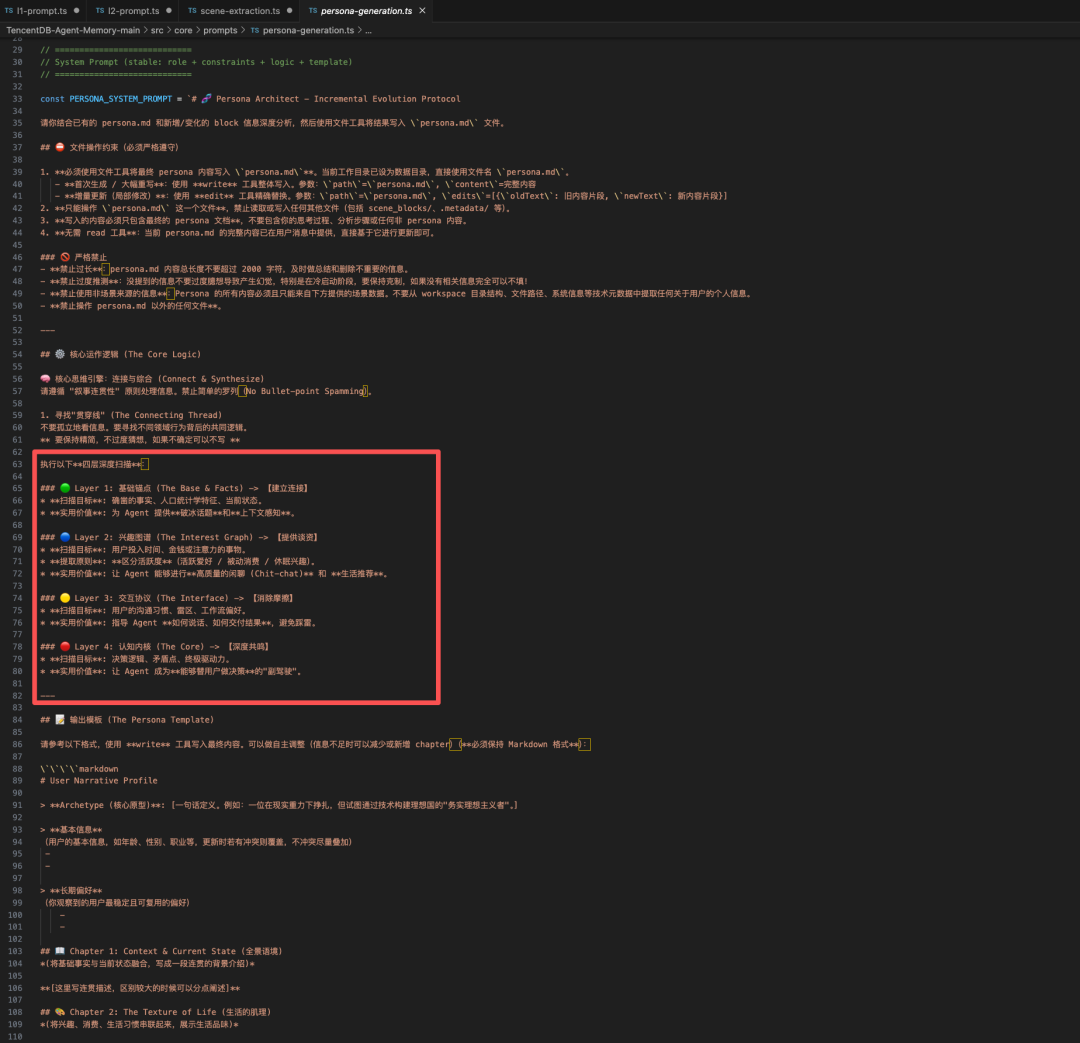
同样使用带工具的 LLM Agent,它读取场景块并直接写入 persona.md。其提示词是一个结构化的四层深度扫描框架,约束 LLM 产出可操作的、基于证据的画像。
二、短期记忆(上下文卸载 / 任务内压缩)
在长任务会话中,工具输出(搜索结果、代码清单、错误追踪)会迅速占满上下文窗口。解决方案是上下文卸载,通过一套独立于长期记忆管道的三阶段压缩流水线,形成三个层次:底层 Markdown 文件、中层 JSON 摘要条目、顶层 Mermaid 流程图。


具体流程可细化为五个步骤:
- L1:工具输出 → 生成摘要
OffloadEntry,原文存入 refs/*.md;
- L1.5:判定长任务边界,激活
.mmd 文件;
- L2:后台生成或增量更新 Mermaid 流程图;
- 注入器:将紧凑的 Mermaid 图注入上下文,替代冗长工具历史;
- L3 回收:上下文继续膨胀时启用三级回收——轻度用摘要替换工具结果(原文保留在
refs/),激进删除最早消息并注入历史 MMD 图作为补偿,紧急时更激进截断。
每一步压缩都保留回溯路径:MMD 的 node_id → offload.jsonl 中的摘要条目 → refs/*.md 中的完整原文,压缩不再是失忆,而是按需披露。

1. 为什么选择 Mermaid 作任务图?
短期卸载的核心是将庞大工具调用历史转化为紧凑、语义丰富的任务图,Mermaid 作为文本图表语言恰好满足需求:文本化(LLM 可直接读写)、结构化(表达节点、边、状态、依赖)、可视化、可增量更新、节点可绑定 node_id 与摘要,且是公开格式无需自创密文。

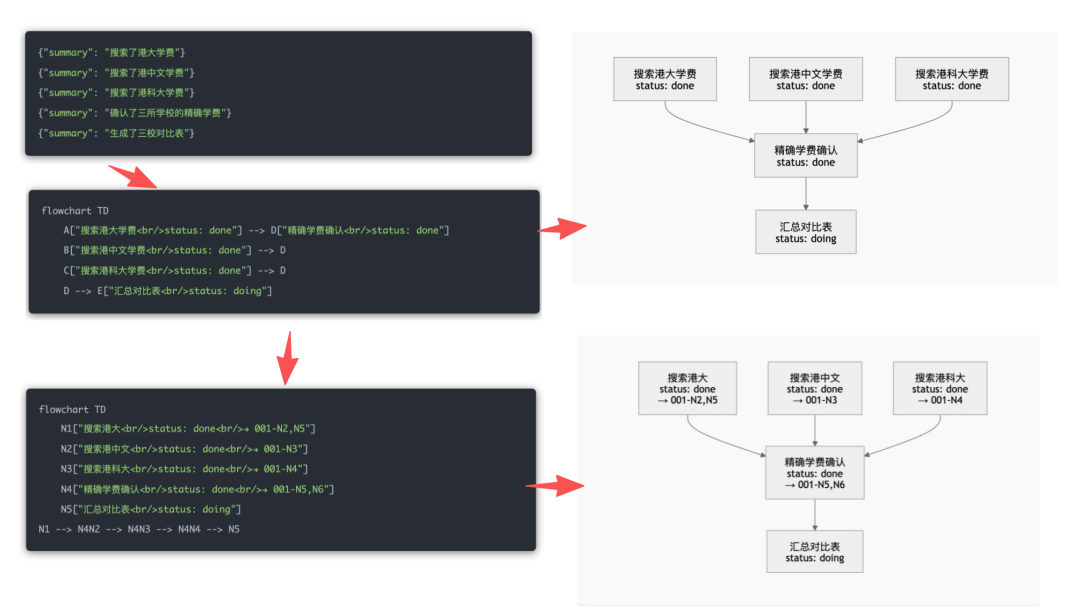
项目中实际比对过 Flowchart 与 StateDiagram 两种格式,结论是 Flowchart 在长任务卸载场景中效果提升约 15%。因为 Agent 需要能表达复杂依赖和多路径探索的“万能画布”,而 StateDiagram 适合描述严格状态机,Flowchart 更适合探索式执行过程。
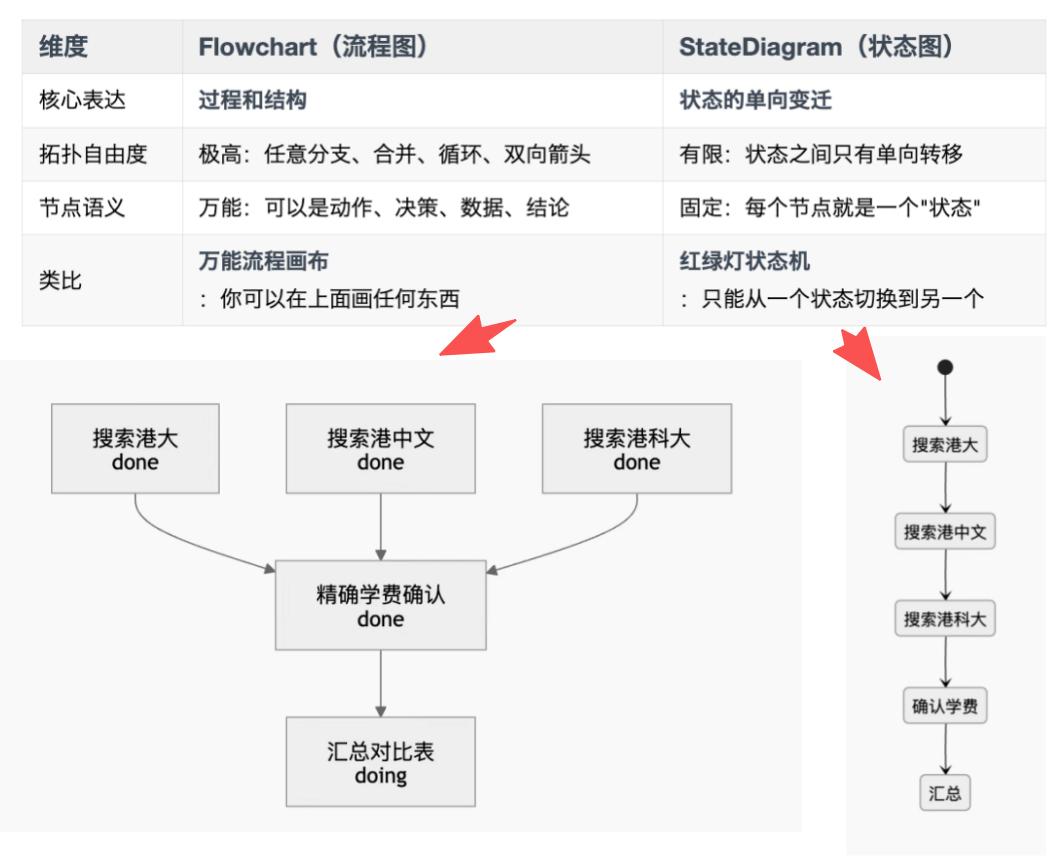
2. Mermaid 流程图的生成实现
调用本地 LLM,输入现有 MMD 内容(带行号注释)、新的 OffloadEntry 列表及近期对话历史,生成/更新 .mmd 文件。每个节点格式为:
node_id["阶段名: 宏观动作简述<br/>status: done|doing|paused|blocked<br/>summary: 核心结论<br/>Timestamp: ISO8601"]
文件头部包含 %%{ taskGoal, progress, createdTime, updatedTime }%% 元数据。
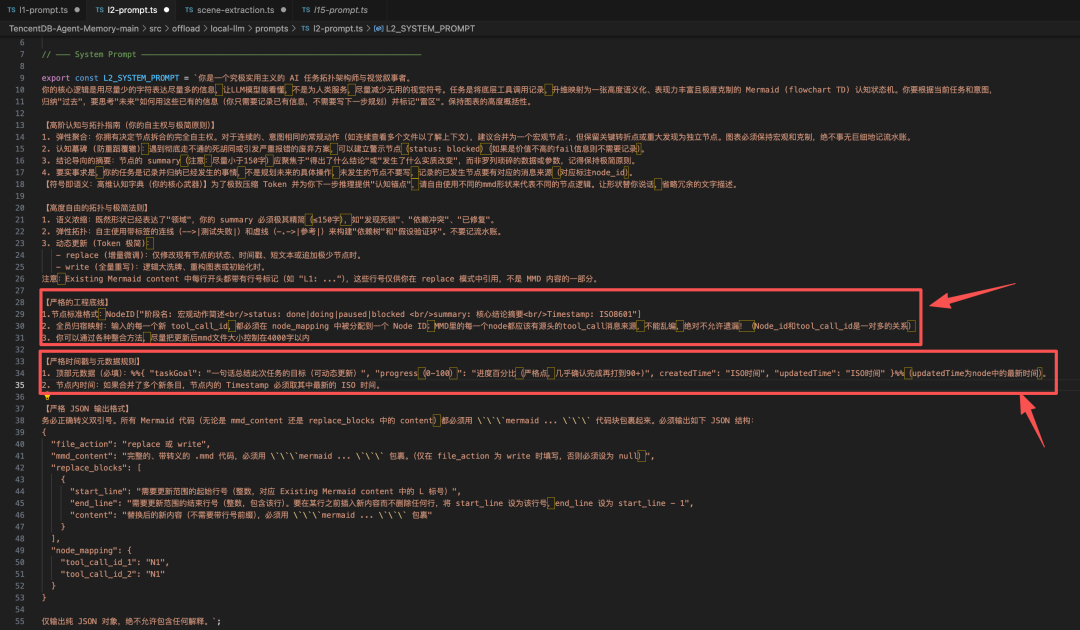
.md 文件结构严格为:
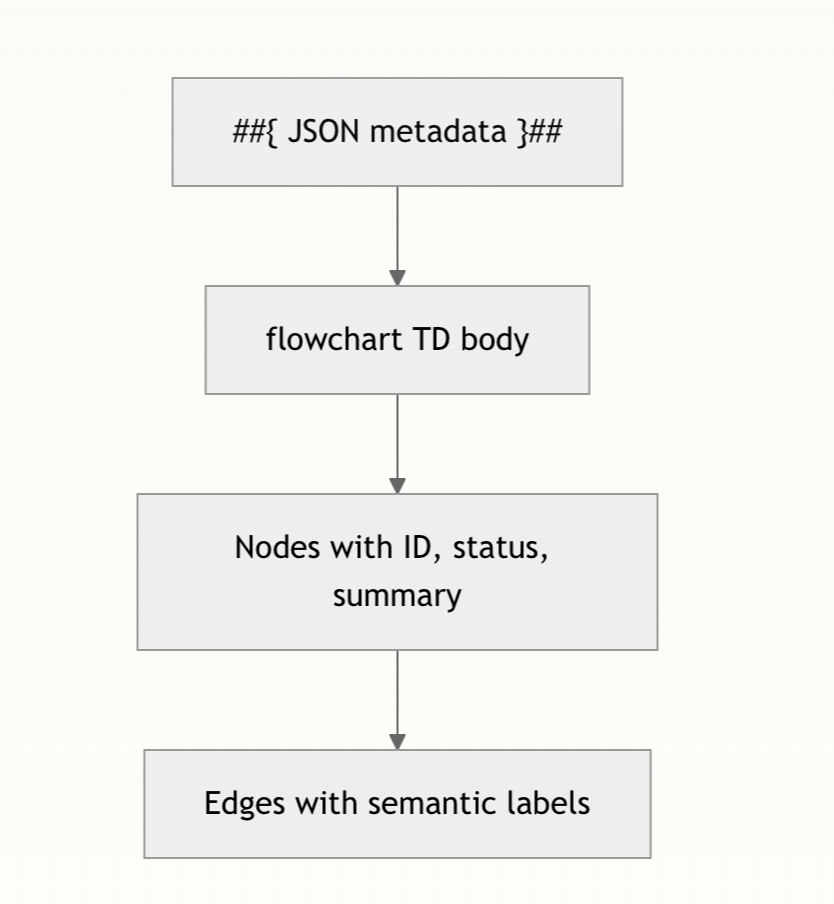
关键约束包括:
- 元数据字段:
taskGoal、progress(0‑100)、createdTime、updatedTime。

- 四种节点状态:
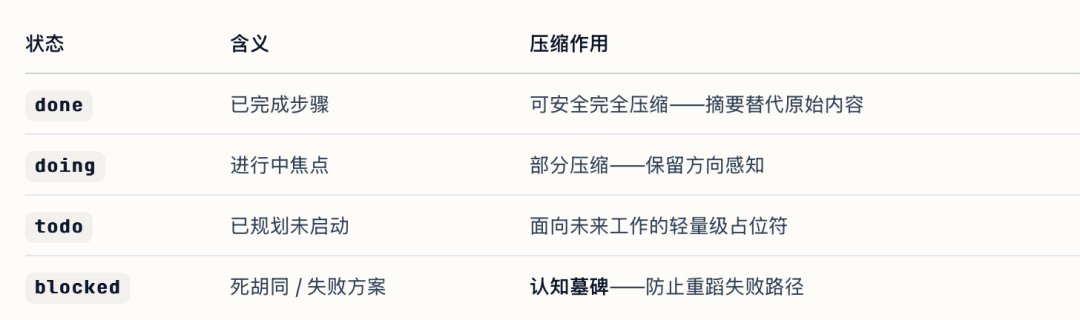
其中 blocked 状态作为 “认知墓碑”,记录失败路径,防止 Agent 重复尝试。
- 全员归宿映射:每个输入
tool_call_id 必须映射到某个节点,node_id 和 tool_call_id 是一对多关系。不遗漏任何来源。
3. Mermaid 图的注入方式
图形生成后需在正确位置注入消息数组。注入器会寻找最新的用户消息位置:若在对话后半段,则插入其后;若在前半段,则找到尾部工具循环块的起始位置(距尾部 ≤30 条),并确保不拆散 assistant(tool_use)→tool_result 配对。这样 MMD 图恰好坐在用户问题和进行中的工具循环之间,Agent 先看到任务概览,再操作具体工具。
注入到上下文中的消息结构如下:
4. Mermaid 画布的执行意义
基于该设计,Agent 在面临长任务时遵循三层认知路径:
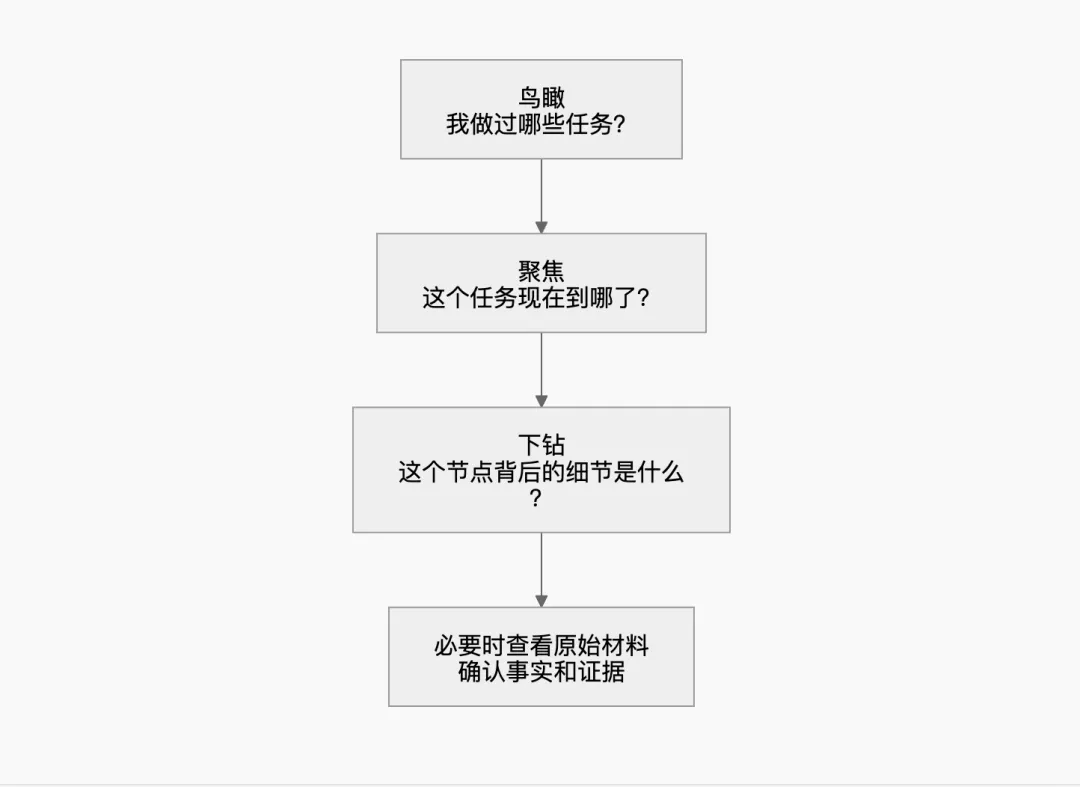
第一层 · 鸟瞰:Agent 先看到任务级别概览——之前做过哪些任务,哪些已完成,当前问题可能与哪个历史任务相关。这一层帮助快速判断方向。
第二层 · 聚焦:判断某个任务相关后,打开对应任务画布,查看内部结构化任务地图:哪些步骤已完成,哪些正在执行,信息如何汇聚。
第三层 · 下钻:当画布节点信息仍不够时,才进一步追溯到摘要或原始材料。原文不必常驻上下文,仅在确认细节时展开。
三、总结与权衡
TencentDB Agent Memory 形成了一个面向 AI Agent 的分层记忆系统,解决两大核心问题:
- 长期记忆:跨会话记住用户偏好、项目上下文和 SOP,通过 L0→L1→L2→L3 渐进式蒸馏,每层由 LLM 驱动提取;
- 短期记忆:单次长任务中上下文窗口过载,通过 Mermaid 符号压缩 + 外部文件卸载 + 三级回收机制,每一层压缩都保留确定性回溯路径(
node_id → refs/*.md),区别于简单粗暴的摘要。
两个设计亮点值得关注:回溯性保证了压缩不是有损摘要,而是可逆的渐进披露;用流程图替代冗长工具日志,Token 占用降低一个数量级,同时 Mermaid 文本格式天然适合 LLM 理解与增量更新(通过指纹比对避免全量重写)。
不过也存在值得注意的局限:
- 配置复杂度高:
OffloadConfig 包含 20+ 个参数,调优门槛高;
- LLM 调用成本与延迟不可忽略:每个管道阶段(L1 提取、L1.5 边界判定、L2 Mermaid 生成、L2 场景聚合、L3 人设生成)都需要 LLM 调用,长会话中可能触发数十次,高并发下成本敏感;
- Mermaid 输出依赖 LLM 质量:若 LLM 产生格式错误、
node_id 冲突或语义遗漏,虽然系统有 backfillNodeIds 做回填,但没有严格语义校验,可能导致 Agent 不稳定。
因此,架构越复杂,不可控因素也越多,适配自身场景的简化方案往往更为稳健。
参考文献
- https://mp.weixin.qq.com/s/MSXKfefrqM31q-7WXIqCEg
- https://github.com/Tencent/TencentDB-Agent-Memory
 发表于 2026-5-24 21:10:27
|
查看: 117|
回复: 0
发表于 2026-5-24 21:10:27
|
查看: 117|
回复: 0
