我们都知道,在一个分布式系统中,最多只能在一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)中三者满足其二,无法同时实现三者兼备。
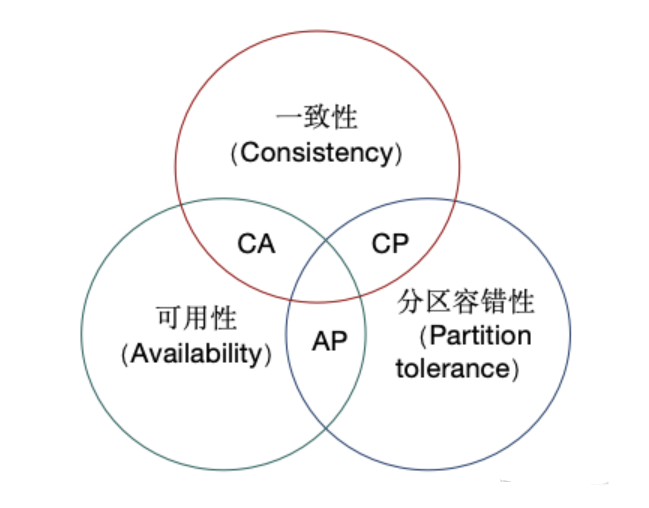
一致性(Consistency)
其英文描述为 “all nodes see the same data at the same time”,直译过来是:在同一时刻,分布式系统中所有节点中的数据必须完全一致。我们也可以将它理解为“分布式系统的业务逻辑一致性”。
举个例子就明白了:假设用户 A 给用户 B 转账 100 元,那么在任何时刻查询,我们都必须能同时看到用户 A 的账户减少了 100 元,用户 B 的账户增加了 100 元,这就是一致性。
一致性根据其强度可以分为以下几种:
- 强一致性:业务结果中的每个步骤,在“任何时刻”都同时生效。CAP 定理中所指的一致性就是强一致性,上面转账的例子也是强一致性的体现。
- 弱一致性:无法保证业务结果中的每个步骤在“任何时刻”都立即同时生效。
- 最终一致性:经过一段时间后,业务结果中的每个步骤最终都会生效,系统达到一致状态。
可用性(Availability)
其英文描述为 “reads and writes always succeed”,意指:在任何时候,分布式系统的读写操作都必须成功。也就是说,在规定的时间内,系统对接收到的每个用户请求,都应该返回正常的业务结果。
分区容错性(Partition tolerance)
英文描述稍显复杂:“the system continues to operate despite arbitrary message loss or failure of part of the system”。我们可以这样简单理解:当分布式系统遭遇网络分区故障时,它仍然能够对外提供满足一致性或可用性的服务。这里的“网络分区故障”,指的是集群中各节点之间的网络连接断开,被分割成几个无法通信的孤立区域。
BASE 定理:对 AP 方案的延伸
BASE 定理可以看作是 CAP 定理中 AP(可用性+分区容错性)方案的进一步延伸,其核心思想是用最终一致性来替代强一致性。BASE 由三部分组成:
- 基本可用 (Basically Available):当系统出现不可预知的故障时,允许损失部分非核心功能的可用性,但要保证核心功能依然可用。
- 软状态 (Soft state):允许系统中的数据存在中间状态,并且这种中间状态的存在不会影响系统的整体可用性。
- 最终一致性 (Eventual consistency):系统保证经过一段时间后,所有数据副本最终能够达到一致的状态。
在分布式事务的语境下,刚性事务(如2PC、3PC)通常满足 CAP 中的 CP 要求。而柔性事务(如 TCC、SAGA、本地消息表等)则更符合 BASE 定理的思想。
接下来,我们重点分析几种常用中间件集群在 CAP 定理中的归属,为实际工作中的技术选型提供参考。
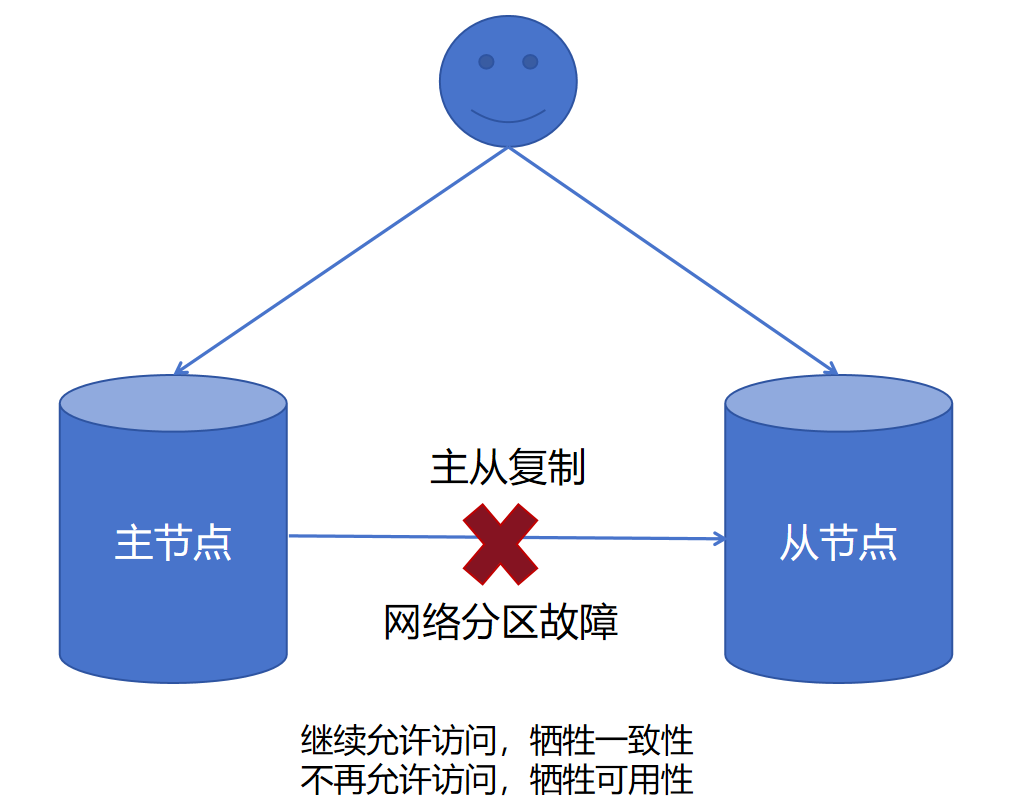
MySQL 主从架构属于 AP 还是 CP?
MySQL 主从复制是 AP 还是 CP 模型并不能一概而论,因为它支持三种复制模式:异步复制(默认)、半同步复制和全同步复制。
异步复制 (AP 模型)
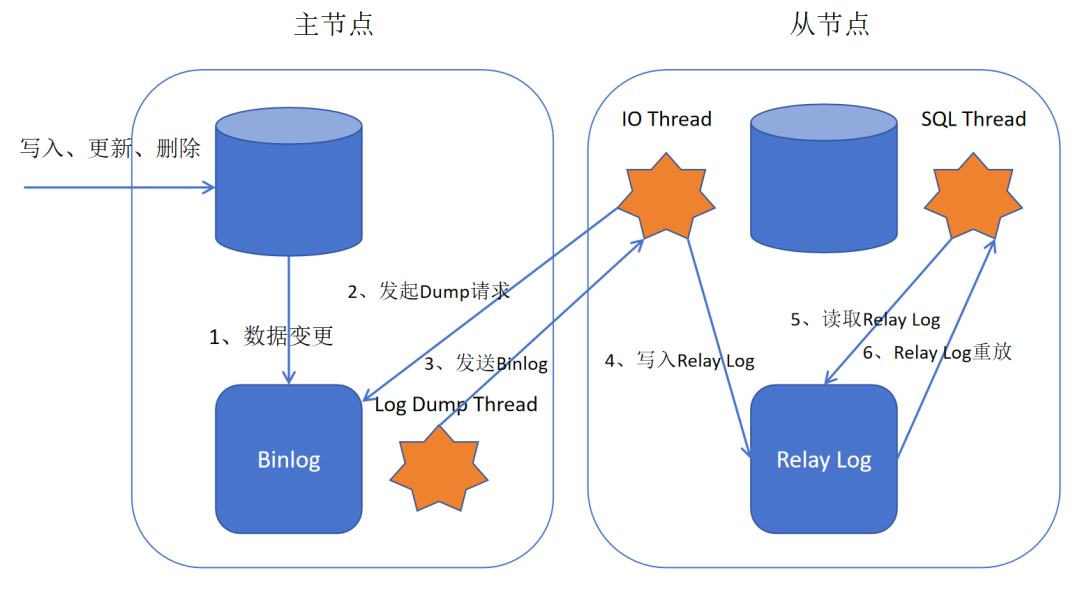
这是 MySQL 默认的复制方式。主库执行写操作并将变更记录到 Binlog 后,会立即给客户端返回成功响应,而无需等待从库确认已接收到并应用这些日志。
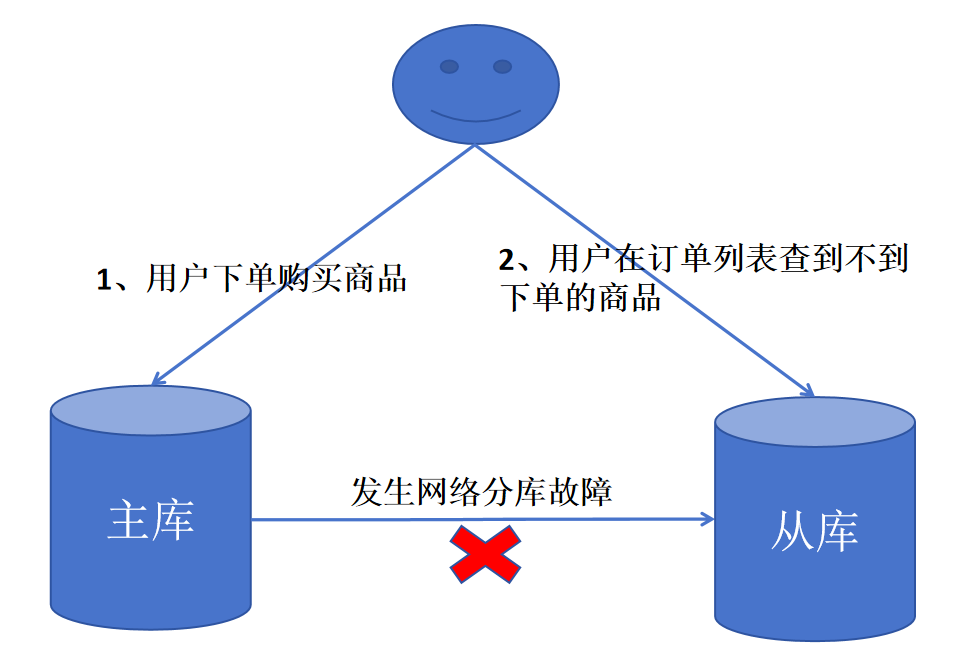
当发生网络分区故障时,主库无法将数据变更同步到从库,但主库自身依然可以继续提供写服务。这就会导致主从库之间的数据出现不一致,即牺牲了一致性(C)来保证可用性(A)。一个典型的电商场景问题如下图所示:
全同步复制 (CP 模型)
在全同步复制模式下,主库执行写操作后,必须等待所有从库都将该事务事件写入本地 Relay Log 并确认后,才会向客户端返回成功。
当发生网络分区故障时,只要有一个从库无法确认,主库为了保证数据一致性,就会阻塞或拒绝新的写操作,直到故障恢复。此时,系统牺牲了可用性(A)来保证一致性(C)。
半同步复制 (AP 模型,但更偏向一致性)
半同步复制是前两者的折中方案。主库需要等待至少一个从库(数量可配置)确认收到事务事件后,才会响应客户端。
它不需要保证所有从库的强一致性,因此在出现部分节点网络分区时,只要有一个从库可用,主库依然能提供写服务(保证了A),但集群内存在数据不一致的风险。所以它本质上仍属于 AP 模型,只是通过配置增强了数据可靠性。
Redis Cluster 的 CAP 归属
Redis Cluster 默认采用异步复制,其主从复制过程简述如下:
主节点每执行一个写命令,除了执行操作本身,还会将该命令写入一个称为“复制积压缓冲区”的环形队列中,并更新自己的复制偏移量。随后,主节点通过 TCP 连接异步地将该命令发送给其从节点。从节点执行相同的命令后,也会更新自己的偏移量,以求与主节点保持一致。
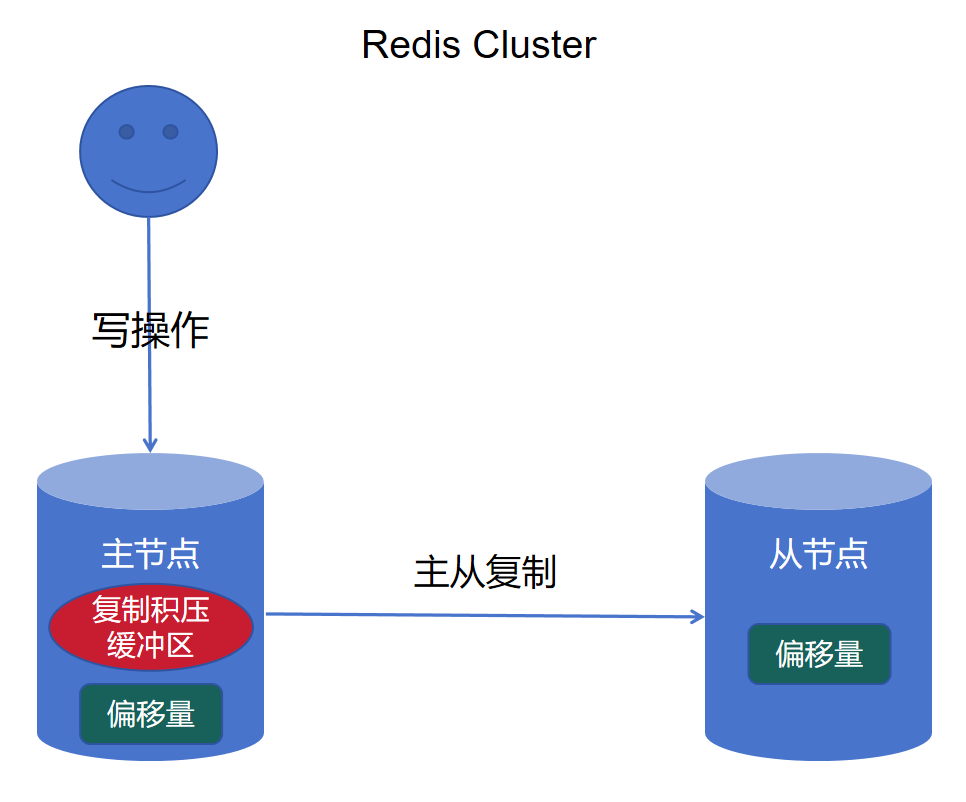
这里的关键点在于“异步”:主节点发送命令后不会等待从节点的确认回复,就会继续处理后续的客户端请求。这种机制带来了高性能,但也引入了数据丢失的风险——如果主节点在命令尚未同步到从节点时发生宕机,这部分数据就会丢失。
为了优化断线重连后的数据同步效率,Redis 引入了两个核心机制:
- 复制偏移量:主从节点各自维护一个偏移量,用于记录已发送或已接收的字节数。对比两者偏移量即可判断数据同步状态。
- 复制积压缓冲区:主节点内部维护一个固定大小的环形缓冲区(默认1MB),缓存最近发出的写命令。从节点重连后,只需根据偏移量从缓冲区拉取缺失的命令即可进行增量同步,无需全量同步。
由此可见,Redis Cluster 默认的异步复制机制使其属于 AP 模型。它通过最终一致性(利用偏移量和缓冲区在故障恢复后追赶数据)来保证高可用性。
ElasticSearch 集群的 CAP 归属
ElasticSearch 集群的 CAP 属性并非固定不变,而是可以由使用者根据一致性参数 consistency 进行配置。
其写操作的基本原理是:客户端请求经协调节点路由到数据的主分片,主分片处理完成后,再将数据同步到其副本分片。
写操作的一致性级别通过 consistency 参数控制,主要有三种选项:
one:仅主分片确认成功即可返回。all:要求主分片和所有副本分片都确认成功才返回。quorum:要求大多数分片确认成功才返回(默认值)。
quorum 的计算公式为:int((primary_shards + number_of_replicas) / 2) + 1。例如,一个索引有 3 个主分片和 1 个副本,那么总共有 6 个分片,quorum 值就是 int((3 + 1) / 2) + 1 = 3,即至少需要 3 个分片(可以是任何主分片或副本分片)可用才能执行写入。
因此,ElasticSearch 集群的 CAP 模型取决于你的配置:
- 如果设置
consistency 为 all,它就是一个 CP 系统,在发生网络分区导致部分分片不可用时,为了保证强一致性,写操作会失败,牺牲了可用性。
- 如果设置
consistency 为 one 或默认的 quorum,它更偏向于一个 AP 系统,在部分节点故障时,只要满足最低可用分片数,仍然可以提供服务,但可能牺牲跨分区的一致性(最终一致)。
理解这些中间件在 CAP 中的不同倾向,能帮助我们在设计系统时做出更合理的技术选型与配置决策。如果你想与更多开发者交流分布式系统相关的实践经验,欢迎访问云栈社区。
 发表于 2026-3-3 12:23:15
|
查看: 118|
回复: 0
发表于 2026-3-3 12:23:15
|
查看: 118|
回复: 0
