运营团队需要一个实时大屏来展示订单量、GMV和退款额,并且要求数据延迟不能超过5秒。
面对这个需求,我们通常会考虑两种方案。方案一是直接查询业务数据库MySQL,但在流量高峰期,大屏的频繁刷新很可能导致业务库CPU负载飙升。方案二是部署一套完整的湖仓一体架构,引入CDC、Kafka、Flink、Paimon、StarRocks等一系列组件,但这对于一个人手有限的团队来说,后续的运维成本将难以承受。
我们需要找到第三条路:一种比直连MySQL更可靠,又比全套湖仓架构更轻量的方案。Flink 加 StarRocks 的组合,恰好能填补这个空白。今天,我们就来详细拆解这条仅由两个核心组件构成的轻量级实时数据链路。
一、架构全景:数据从何而来,去往何处?
我们先来看一条数据从MySQL产生到最终在实时大屏上展示的完整旅程。
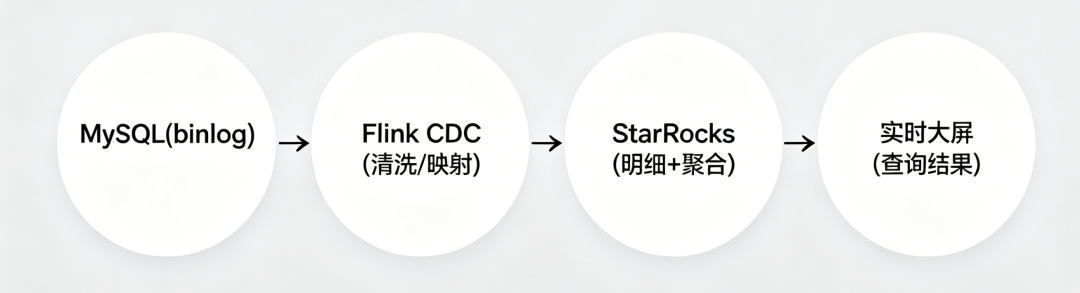
如上图所示,当MySQL中产生一条订单变更记录时,其binlog会被Flink CDC实时捕获。捕获到的数据经过Flink SQL进行简单的字段映射和过滤后,直接写入StarRocks的明细表中。当大屏发起查询请求时,StarRocks可以通过预计算的物化视图快速返回聚合结果,整个过程的端到端延迟可以控制在秒级。
这条链路的核心新增组件只有两个:Flink和StarRocks。
Flink是数据的搬运工兼清洗工:
- 它伪装成MySQL的从库,实时订阅
binlog日志流。
- 解析其中的INSERT、UPDATE、DELETE等数据变更事件。
- 通过
Flink SQL进行轻量级加工,例如过滤测试数据、统一时间格式、重命名字段。
- 最终将处理好的数据写入
StarRocks。
StarRocks则身兼存储与服务两层角色:
- 作为存储层,它存储明细数据,相当于传统数仓中的ODS和DWD层。
- 作为服务层,它直接承接大屏和报表的查询请求,替代了传统架构中的ADS层。
- 凭借其列式存储和MPP并行计算引擎,它既能高效存储海量明细,又能快速响应复杂查询。
这条链路没有引入Kafka作为消息队列,也没有引入独立的湖表格式或计算服务层。仅靠两个组件就实现了从变更捕获到实时查询的闭环,这正是“轻量”二字的体现。对于希望快速构建实时数据能力,又担心复杂度和成本的团队,这是一个值得在云栈社区这类技术论坛深入探讨的实用架构。
二、数据摄入:Flink CDC 如何工作?
Flink CDC是如何实时抓取MySQL数据的?它比传统的定时拉取(如SELECT *)方式强在哪里?
CDC的全称是Change Data Capture(变更数据捕获)。它的核心原理不是间歇性地去询问数据库是否有新数据,而是让数据库主动推送变更。这个能力的基石是MySQL的binlog(二进制日志)。binlog记录了数据库所有的数据修改操作,是MySQL主从复制的核心。Flink CDC正是通过伪装成一个MySQL从库,来订阅这份连续的binlog流。
这种工作模式带来了三个显著优势:
- 对源库压力小:定时拉取通常需要扫描全表,而订阅
binlog只是读取增量日志文件,对源库的额外负载几乎可以忽略。
- 延迟极低:数据一旦写入MySQL并产生
binlog,Flink CDC就能立刻捕获,端到端延迟可达秒级甚至亚秒级。
- 能完整捕获变更历史:定时拉取只能得到某个时间点的数据快照,无法感知中间的UPDATE或DELETE操作。而
binlog完整记录了每一行数据的变更历史。
Flink CDC获取到binlog后,会先将其解析为结构化的数据记录,然后通过Flink SQL进行轻量清洗。例如,源表中可能存在状态为‘TEST’的测试订单,只需在SQL中添加WHERE status != 'TEST'即可过滤。再比如,将MySQL的DATETIME类型字段统一转换为StarRocks的TIMESTAMP类型。
假设MySQL中执行了如下插入操作:
INSERT INTO orders VALUES (1001, 1, 99.9, 'PAID', '2024-01-01 10:00:00');
Flink CDC会捕获这条binlog,将其解析为一条数据记录,经过SQL清洗后,写入StarRocks的ods_orders表。从数据产生到落库,整个过程通常不超过3秒。
三、数据存储与计算:StarRocks 的双重角色
数据进入StarRocks后,如何同时胜任存储和查询服务?关键在于其数据模型和预计算能力。
3.1 第一重角色:明细存储层
StarRocks的第一个身份是存储层,用于存放来自Flink CDC的原始明细数据。这里推荐使用主键模型(Primary Key Model)。为表定义一个主键(例如order_id),当有新数据写入时,会自动根据主键覆盖旧数据。
这个设计完美匹配了Flink CDC同步过来的更新和删除语义:
- UPDATE操作对应新记录覆盖同主键的旧记录。
- DELETE操作对应删除该主键的记录。
因此,Flink CDC同步过来的变更数据可以直接通过INSERT语句写入,由StarRocks自动完成数据的更新与删除,无需额外的合并逻辑。
3.2 第二重角色:聚合服务层
实时大屏需要的通常是聚合结果,例如“每小时的销售额总和”。如果每次查询都去扫描数亿条的明细表并进行实时聚合,即使引擎再快,响应时间也可能达到分钟级,无法满足实时性要求。
StarRocks的解决方案是物化视图(Materialized View)。物化视图可以提前根据预定义的聚合逻辑(如SUM、GROUP BY)将结果计算好并存储起来。当查询命中物化视图时,引擎会直接返回预计算的结果,查询速度得到数量级的提升。
例如,大屏需要查询昨日每小时的销售额:
SELECT
DATE_TRUNC('hour', update_time) AS hour,
SUM(amount) AS total_amount,
COUNT(*) AS order_cnt
FROM order_summary
WHERE dt = '2024-01-01'
GROUP BY hour;
如果这个查询的模式已经通过物化视图实现,StarRocks会直接从物化视图中获取结果,响应时间可能在几十毫秒内。相比之下,没有物化视图则需要全表扫描和实时聚合,不仅消耗大量CPU资源,还会导致前端页面长时间加载。
“主键模型 + 物化视图”这套组合拳,是StarRocks能够一肩挑两担的核心。主键模型高效承接来自CDC的增量变更,物化视图则提前消化复杂的聚合计算,让写入和查询互不干扰,各司其职。
四、架构的边界与演进
没有任何架构是银弹。Flink加StarRocks这套轻量链路在哪些场景下会遇到瓶颈?又该如何演进?
边界一:数据量与存储成本
StarRocks的设计目标是高性能查询,而非低成本存储。其数据通常存储在本地SSD并通过多副本保证可靠性,存储成本远高于对象存储(如S3)。因此,它适合存储最近几天的热数据。若需存储全年全量数据,成本会急剧上升。此时,可能需要引入数据湖表格式进行冷热数据分层,但这已超出轻量架构的范畴。
边界二:历史数据回溯
该架构默认StarRocks只保留近期热数据。如果需要频繁查询或回溯数月前的历史数据,此架构无法直接满足,需依赖离线数仓或归档系统。
边界三:下游消费者增多
在基础架构中,Flink CDC直写StarRocks,下游(如大屏)直接查询。当只有单一消费者时,运行顺畅。但如果实时风控、推荐系统、运营报表等多个下游都需要消费同一份实时数据,它们对StarRocks明细表的并发分析查询会产生资源争抢,导致查询延迟抖动。
此时,引入Kafka作为数据总线是自然的演进方向:
MySQL → Flink CDC → Kafka → 多个下游(大屏/风控/推荐)
Flink CDC清洗后的数据先写入Kafka,各下游业务独立消费。例如,实时大屏消费一份写入StarRocks,风控消费一份写入规则引擎,推荐系统消费一份更新用户画像。Kafka实现了数据的一产多销,解耦了生产与消费。同时,Kafka默认的数据保留策略也能支持短期的数据回溯需求。这个演进只是从两个组件变为三个,是可控的复杂度增长。探索这类大数据架构的演进路径,是技术团队持续成长的必修课。
边界四:ETL逻辑复杂化
基础版架构中的Flink SQL仅处理简单的单表映射和过滤。如果业务需求升级,需要进行多流关联(如订单流关联物流流),计算复杂的实时宽表,那么Flink作业的状态会急剧膨胀,导致检查点时间变长,运维复杂度飙升。
这说明数据清洗逻辑已进入“重量级”领域,需要引入更清晰的分层架构(如DWD、DWS层)来承载复杂的流计算。这同样是架构根据业务发展进行的必要演进,而非初始设计的缺陷。
写在最后
回顾整个方案,Flink加StarRocks的轻量级实时数仓架构,就好比一个精致的“两居室”。对于初创阶段或需求明确的场景,它空间紧凑、功能齐全,居住体验“刚刚好”。
当业务发展,数据消费者增多、计算逻辑变复杂时,就如同家庭人口增加,我们需要的是“加一个房间”(引入Kafka)或者“换一套更大的房子”(构建分层数仓)。关键在于识别“搬家”的信号,而不是在项目伊始就背负一座难以维护的“技术别墅”。希望这个关于实时数据处理方案的探讨,能为你带来启发。
 发表于 2026-4-19 04:33:34
|
查看: 215|
回复: 0
发表于 2026-4-19 04:33:34
|
查看: 215|
回复: 0
