电商场景中,购物车是连接商品浏览与订单转化的核心节点,也是高并发读写最集中的区域之一。千万级用户体量下,购物车系统的架构设计直接影响用户体验、交易转化率和系统稳定性。很多团队在用户规模增长后才发现,初期简单的数据库读写方案根本扛不住大促流量的冲击,不得不进行重构。
一、场景与价值
购物车不是一个简单的增删改查功能,背后承载着复杂的业务逻辑和技术挑战。从用户行为来看,购物车的访问频次远高于订单提交频次,多数用户会反复添加、删除、修改商品数量,对比不同商品组合,最后才会进入结算环节。
千万级用户体量下,这个特征会被放大。日常情况下,购物车的QPS可能在数千级别,但在大促秒杀场景下,瞬间流量可以达到数万甚至数十万。如果架构设计不合理,很容易出现数据库连接耗尽、响应超时、甚至服务雪崩的情况。
购物车的数据特征也很特殊。每个用户的购物车数据量不大,通常就是几个到几十个商品,但用户总量巨大,整体数据量会达到数亿条。读写比例大概在3:1到5:1之间,读操作远多于写操作,但写操作的并发同样不能忽视——大促期间大量用户同时添加商品到购物车,会产生集中的写入压力。
从业务价值来看,购物车是用户购买决策的最后一公里。购物车加载速度每慢100毫秒,就可能导致转化率下降0.5%到1%。如果购物车服务出现不可用,整个交易链路都会中断,损失直接体现在GMV上。这也是为什么大厂都把购物车作为核心链路中的重点优化对象。
多数中小团队在初期会选择用数据库直接支撑购物车读写,这种方案在十万级用户规模下基本可用,但到了百万级就会出现明显的性能瓶颈,到了千万级则完全不可行。架构升级不是可选项,而是必选项。
二、设计与实现
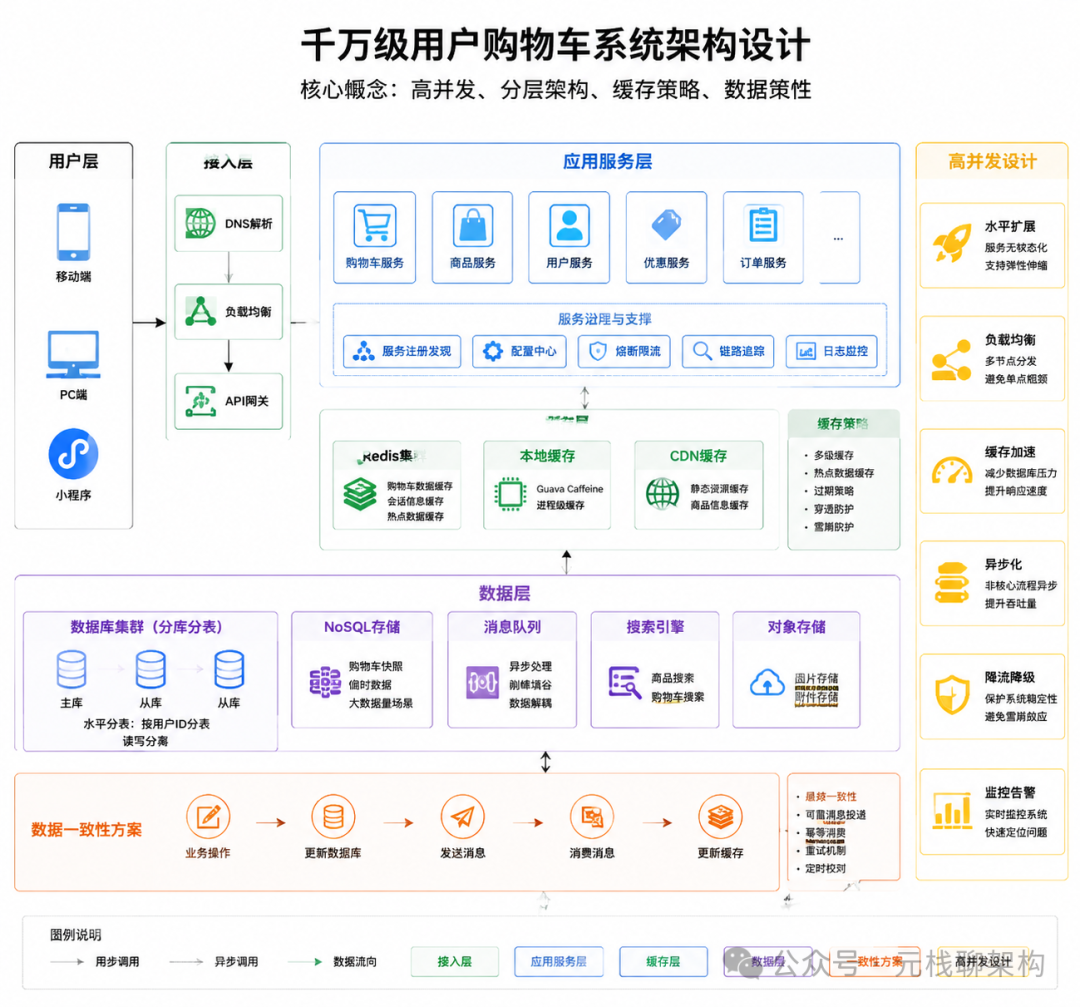
购物车系统的架构设计通常遵循分层原则,从接入层到存储层逐步优化。最经典的方案是三级缓存加上数据库兜底,配合异步更新和数据一致性策略。
接入层一般会做第一层防护。Nginx或者API网关层面,可以针对单个用户的请求频率做限流,防止恶意爬虫或者脚本产生的异常流量。同时接入层会做简单的请求校验,过滤掉参数不合法的请求,避免无效请求打到下游服务。
服务层是业务逻辑的核心。这里会实现购物车的增删改查操作,以及商品库存校验、促销计算等关联逻辑。服务层通常采用无状态设计,可以水平扩展,通过增加机器来应对更高的并发。服务内部会使用本地缓存作为二级缓存,缓存热点用户的购物车数据,减少对分布式缓存的访问压力。
分布式缓存是第三层,也是承载绝大多数读写请求的地方。 Redis 是最常用的选择,String、Hash、List三种数据结构都可以用来存储购物车数据,各有优缺点。String结构最简单,每个用户一个key,value是序列化后的购物车数据,读写都是一次操作,但修改单个商品需要读出整个购物车再写回。Hash结构更灵活,每个商品是一个field,可以单独修改某个商品的数量,但读写次数会更多。List结构适合商品顺序敏感的场景,但修改操作相对麻烦。
压测数据显示,三级缓存架构可以承载99%以上的读请求,只有不到1%的请求会穿透到数据库。写操作也可以通过缓存先写成功,再异步更新到数据库,降低用户等待时间。这种设计下,千万级用户的日常购物车访问基本不会有性能问题。
数据库层作为最终的数据存储,主要承担兜底作用。即使缓存全部失效,数据库也要能扛住基础的访问压力,不能直接挂掉。通常会对购物车表做分库分表,按照用户ID哈希分片,把数据分散到多个数据库实例上,分摊读写压力。索引设计也很重要,用户ID是最常用的查询条件,必须建立主键或者唯一索引。
数据一致性是设计中最容易出问题的环节。缓存和数据库之间的同步策略有很多种,先更数据库再删缓存、先删缓存再更数据库、异步双写等等,每种方案都有各自的适用场景和问题。多数团队会选择先更新数据库,再删除缓存的方案,这种方案在并发不高的场景下基本够用,但在极端情况下还是会出现短暂的数据不一致。
更严谨的方案是引入 消息队列 做异步保证。数据库更新后发送一条消息到MQ,消费者收到消息后再去删除或者更新缓存,同时增加重试机制,确保最终一致性。对于购物车这种场景,短暂的不一致通常是可以接受的,只要最终一致就行,用户基本感知不到秒级别的数据延迟。
三、痛点击破
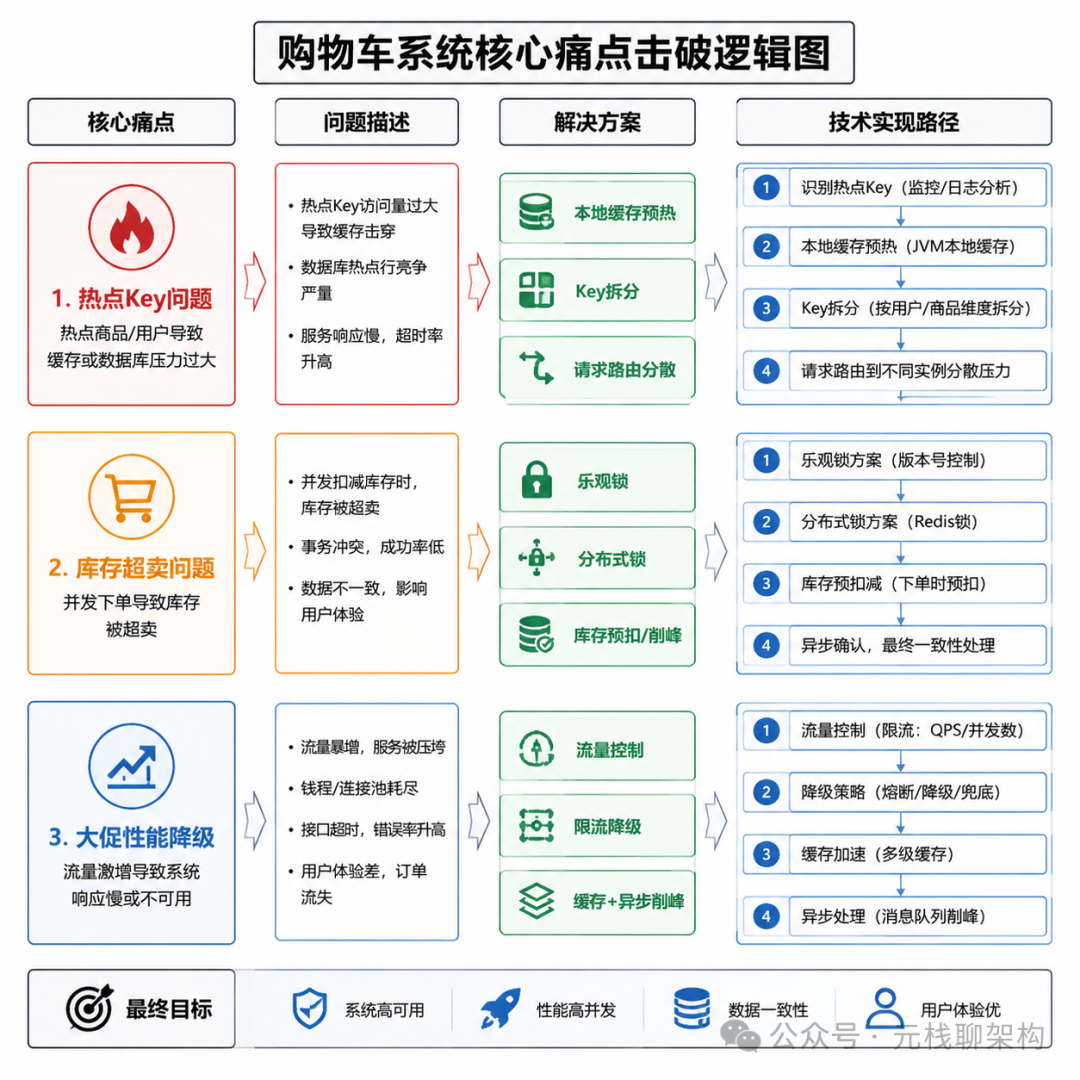
即使有了分层架构,实际运行中还是会遇到很多具体问题。热点key问题就是其中最典型的一个。大促期间,某个爆款商品会被几十万甚至上百万用户同时添加到购物车,如果缓存设计不合理,很容易出现缓存击穿或者雪崩。
解决热点key问题通常有几个思路。首先是本地缓存预热,在服务层提前把热点商品的相关信息加载到本地缓存,减少对分布式缓存的访问。其次是key拆分,把同一个热点key拆分成多个子key,分散到不同的Redis节点上,避免单个节点压力过大。最后是流量控制,在接入层或者服务层对热点商品的写操作做限流,防止瞬间写请求冲垮缓存。
库存超卖是另一个常见痛点。购物车添加商品时需要校验库存,如果多个用户同时购买同一个商品,很容易出现库存计算错误。解决这个问题通常采用乐观锁或者分布式锁。乐观锁通过版本号控制,只有版本号匹配时才更新库存,性能更好但失败率稍高。分布式锁更可靠,但会增加系统复杂度,锁的粒度和超时时间设置需要特别小心。
多数情况下,购物车的库存校验只做预扣减,真正的库存扣减在订单提交时才执行。这样可以降低购物车场景的锁冲突,提升并发能力。但需要配合定期的库存对账机制,防止预扣减产生的数据偏差累积。
大促期间的性能降级也是必须考虑的。当系统负载超过阈值时,应该主动关闭一些非核心功能,比如购物车的推荐商品展示、促销价格实时计算等,优先保证核心的增删改查功能可用。降级策略需要提前设计好,通过配置中心动态开关,不能等到出问题了再临时改代码。
数据过期策略同样重要。很多用户添加商品到购物车后就再也不回来,这些过期数据如果不清理,会占用大量的存储空间。通常的做法是设置购物车数据的过期时间,超过一定期限没有访问就自动删除。同时可以设置LRU淘汰策略,优先淘汰长时间不访问的冷数据,保留活跃用户的热数据。
四、选型对比
购物车架构没有标准答案,不同的用户规模和业务特点需要不同的方案。这里对比几种常见的实现方式,帮助团队根据自身情况做选择。
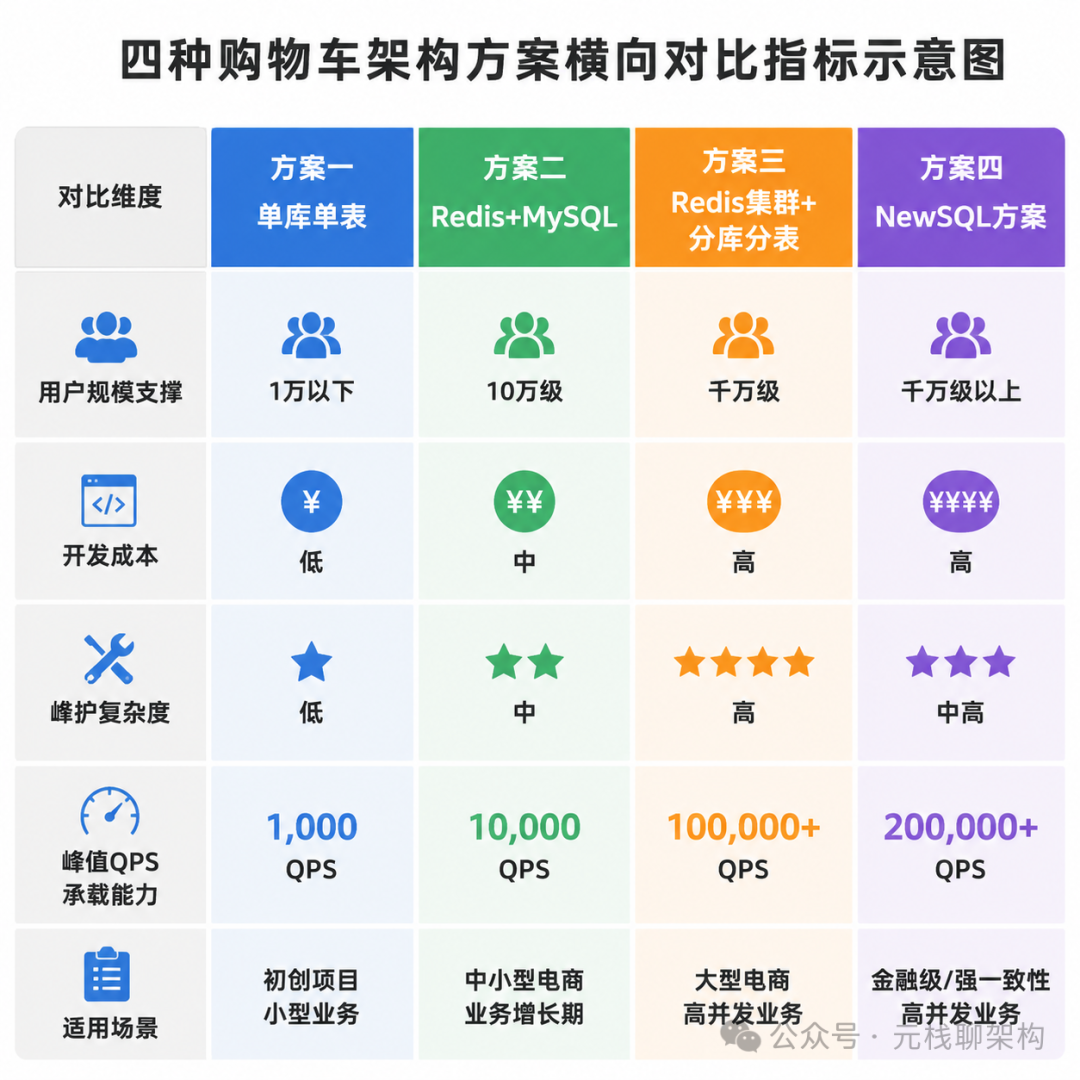
单库单表方案最直接,开发成本最低,不需要额外的缓存或者中间件。所有读写都直接走数据库,通过索引优化和简单的读写分离就能支撑。这种方案的上限大概在十万到百万级用户,日常QPS在几百以内的团队都可以用。优点是简单、维护成本低,缺点是抗不住突发流量,大促期间很容易出现慢查询。
Redis+MySQL方案是最主流的选择,百万到千万级用户的团队基本都用这个。Redis承载绝大多数读写请求,MySQL做持久化存储。这种方案开发成本中等,需要处理缓存和数据库的一致性问题,但技术成熟,社区资料丰富,大部分团队都能hold住。压测表现也不错,单Redis集群可以支撑几万到几十万的QPS,基本能满足多数电商的需求。
Redis集群+分库分表方案是大厂的标配,适合千万级以上用户,峰值QPS超过十万的场景。Redis做集群分片,分散热点压力,数据库也按照用户ID做分库分表,单库数据量控制在千万级别以内。这种方案开发和维护成本都很高,需要专业的DBA和中间件团队支撑,数据路由、事务处理、扩容迁移都很复杂。不是所有团队都需要走到这一步,过早过度设计反而会增加不必要的负担。
还有一些新兴的方案,比如用NewSQL数据库直接支撑,TiDB或者CockroachDB这类分布式数据库天然支持水平扩展,不用手动分库分表,对业务层更友好。但这类产品的学习成本高,团队需要有相应的技术积累,而且成本也比传统MySQL高不少。
从成本收益角度看,大多数团队停留在Redis+MySQL方案就足够了。千万级用户不是一个容易达到的规模,很多公司发展几年都到不了这个量级,过早做复杂的分库分表和集群架构,投入的人力成本和带来的收益根本不成正比。架构演进应该跟着业务发展走,而不是反过来提前做过度设计。
五、整体回顾
购物车系统的架构设计,核心是平衡性能、成本和一致性三个维度。没有完美的方案,只有最适合当前业务阶段的选择。
性能方面,分层缓存是经过验证的有效手段。接入层限流、服务层本地缓存、分布式缓存承载主流量、数据库做兜底,四层防护层层递进,基本能应对绝大多数场景。关键是要做好压测,知道每一层的瓶颈在哪里,什么流量量级下会出问题。
成本方面,要避免过度设计。很多团队一开始就上最复杂的架构,用最好的硬件,但实际流量根本用不上,造成资源浪费。架构应该逐步演进,用户量到了十万考虑加缓存,到了百万考虑读写分离,到了千万考虑分库分表,每一步都有明确的业务驱动。
一致性是最容易被忽略的点。缓存和数据库的同步策略,不是选一个方案就行,还要考虑异常情况的处理。网络抖动、服务重启、消息丢失这些情况在生产环境中经常发生,必须有相应的重试和补偿机制。最终一致性是购物车场景的合理选择,不要强求强一致,付出的性能代价太高。
很多团队在重构购物车时犯的错误,是把所有功能都堆在一起。其实购物车的核心功能很简单,就是增删改查,其他的推荐、促销、库存校验都应该拆成独立的服务,通过RPC或者消息队列解耦。核心链路越简单,出问题的概率就越低,排查问题也更容易。
监控也同样重要。购物车的响应时间、错误率、缓存命中率、数据库慢查询,这些指标都要有实时监控和告警。大促期间还要有实时的流量大盘,能看到各个层级的负载情况,出现问题时可以快速定位和处理。很多故障不是没有解决方案,而是发现得太晚,等用户反馈了才知道系统出了问题。
千万级用户体量下,没有什么架构是一成不变的。业务在发展,用户在增长,技术方案也要跟着迭代。今天看起来完美的架构,过两年可能就跟不上业务发展了。保持架构的可扩展性,预留出未来演进的空间,比追求当下的完美更重要。想了解更多一线架构实践,欢迎访问 云栈社区 一起交流。
 发表于 2026-5-17 03:12:08
|
查看: 123|
回复: 0
发表于 2026-5-17 03:12:08
|
查看: 123|
回复: 0
