有时候翻翻以前的复盘记录,除了品味其中的甘苦,也能从中获得新的启发。

事故发生
云上的 MySQL 数据库资源监控突然发出负载告警。数据库一出问题,十有八九会牵连到数据层面,这意味着一个大麻烦正扑面而来。
本想赶紧登录服务器看看连接情况,结果发现连接数已经打满,完全无法登录。我们立马同步 DBA 介入,通过排查满日志和活跃 SQL,最终定位到了具体的语句:
INSERT INTO user_pull_account_amount (user_id, total_amount, now_amount) VALUE (745874414, 6, 6)
ON DUPLICATE KEY UPDATE
now_amount = now_amount + 6,
total_amount = total_amount + 6
对齐后发现,这属于红包业务的逻辑。登录到服务上看,服务日志量异常庞大。通过下面的命令查看 MySQL 连接数,返回的条目非常多。
netstat -an | grep 3306 | grep ESTABLISHED | wc -l
事故排查和处理
初步定位到具体服务后,第一件事就是优先切断该服务的流量。通过内部守护命令 guard 将服务下线,避免对 MySQL 的持续冲击造成请求堆积。
对于这类活动业务,遇险时的原则就是:要么停服止血,要么通过降级手段减少外部流量。最关键的一步,是先确认活动数据是否完好。
下线核心业务服务后,我们展开了更深层的事故链路排查。
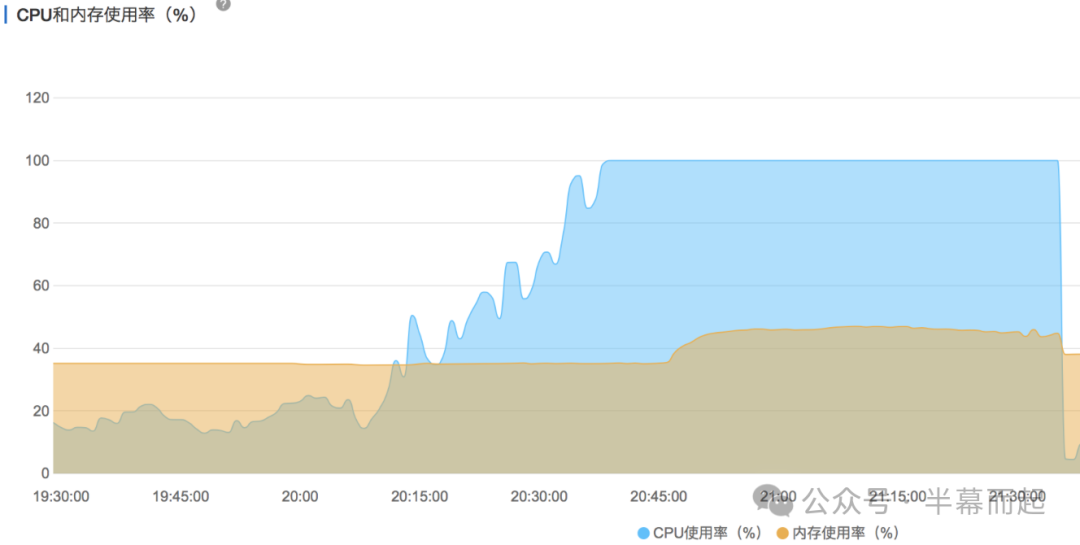
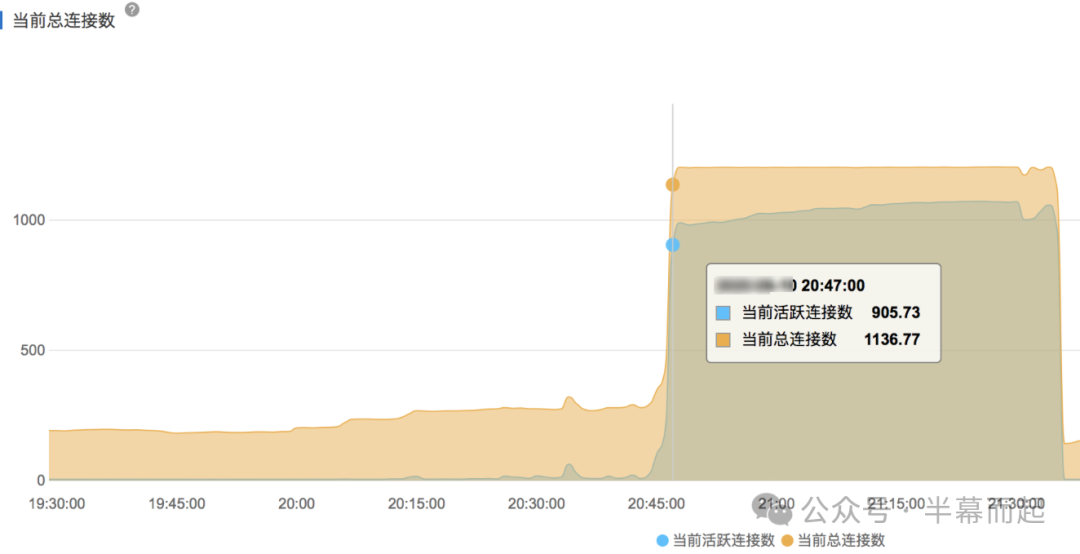
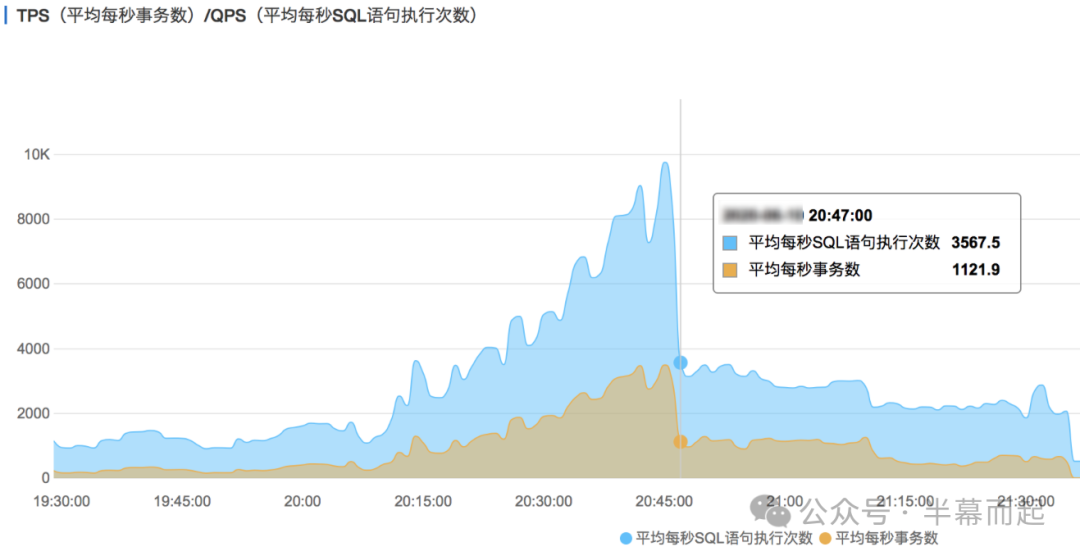
从监控图上看,CPU 负载直接飙升至接近 100%,数据库连接数被瞬间打满,随之而来的 QPS 和 TPS 突增也就解释了告警的诱因。
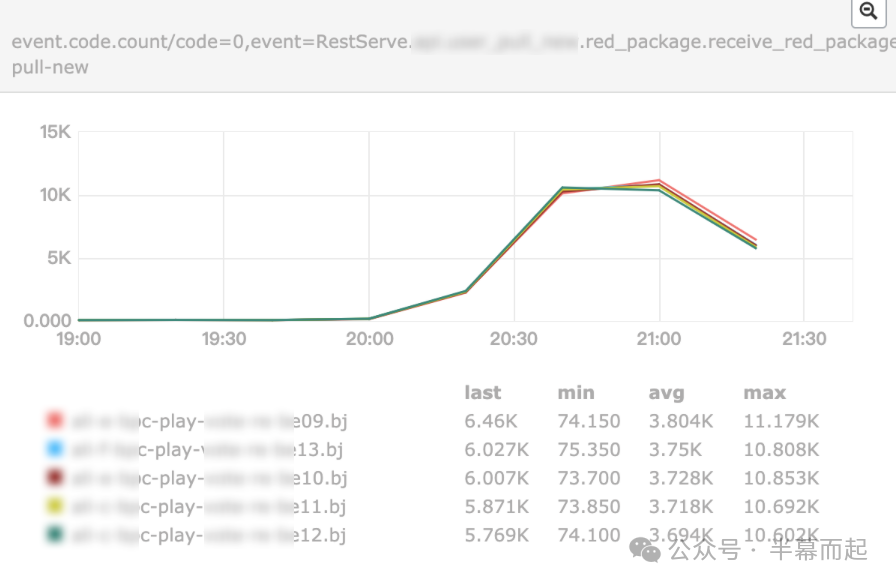
事故当天的接口流量出现了非正常的暴涨。正是这股“异常流量”通过业务入口涌入,最终将 MySQL 的连接数打满并导致服务卡死。那么,下一步要做的就是深入业务的代码实现和架构设计,定位最根本的原因。
事故原因
回溯代码与逻辑,我们发现了三个核心缺陷:
- 核心的领取红包接口没有接入平台风控体系。
- 红包领取次数的上限限制逻辑不够严谨。
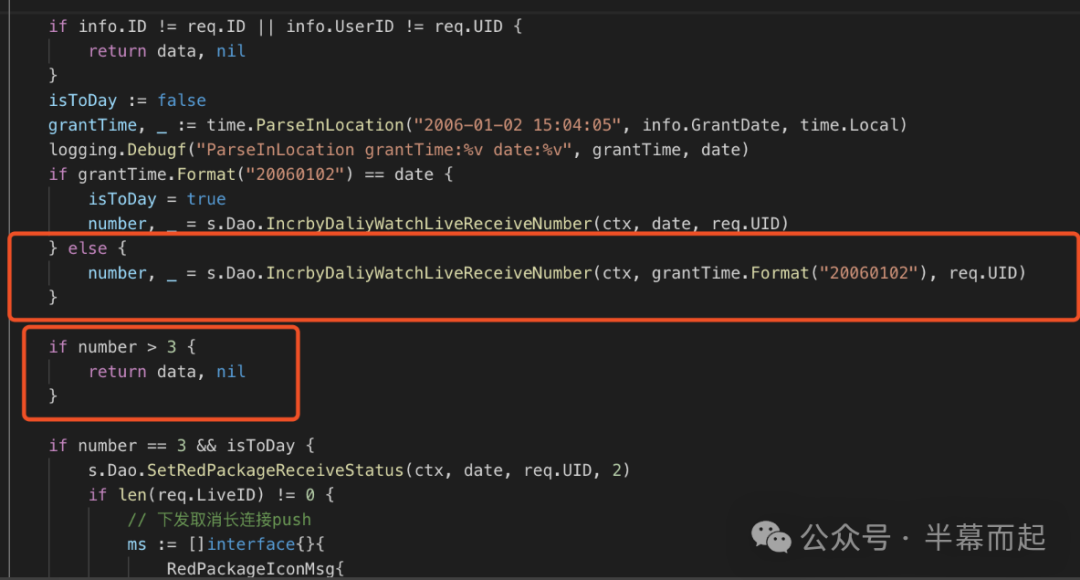
- 红包领取的核心数据库更新操作中,对影响行数的处理存在 Bug。

这些业务逻辑上的漏洞,导致请求直接击穿了本应存在的验证机制,攻击者可以直接对账户余额进行更新操作。海量请求被直接透传到了数据库层,直到数据库资源被打满触发告警,我们才发现问题。
结合数据库流量数据和接口日志分析,我们判定这是一次针对活动账户的异常请求,可以定性为黑产攻击。随即立刻关闭了服务的金融出金入口,下线了整个服务,开始进行数据核对和修复。

在复盘虚拟币红包这类活动时,我们深刻体会到:搞活动的关键在于防刷。
然而,防刷的本质并不一定是筑起高墙把“羊毛党”全挡在外面。从后端架构的视角看,更务实的做法是,用一套风控体系让“刷子们”无利可图。
大致的设计思路取决于具体业务的权衡与取舍:
- 奖励不要“即时到账”。这会直接降低套利的效率,增加攻击者的资金时间成本。
- 必须设立“资金冻结期”。通过增加时间限制来抬高作恶成本。
- 构建设备指纹、IP画像与用户行为分析的“三位一体”识别体系。
以下是一份在复盘过程中沉淀的活动风控策略笔记,涵盖了事前、事中、事后的不同维度:

 发表于 2026-5-13 15:37:58
|
查看: 139|
回复: 0
发表于 2026-5-13 15:37:58
|
查看: 139|
回复: 0
