一条看似人畜无害的 IN 子查询,在商家门店从几十家涨到 3000 家时,把主库 CPU 打到 100%。为什么子查询容易翻车?什么时候改成 JOIN 才救得回来?本文拆解六类子查询的改写策略,以及在千万 QPS 规模下,JOIN 本身又为什么会被禁掉。
一条 IN 子查询,把主库 CPU 打到 100%
凌晨三点,值班群被告警刷屏。商家后台的“待处理订单”列表接口超时率 30%,主库 CPU 从 40% 直接顶到 100%,RT 从 50ms 飙到 8 秒。DBA 从慢日志里抓出来一条 SQL,是一段看起来再平常不过的子查询:
SELECT * FROM orders
WHERE shop_id IN (SELECT id FROM shops WHERE owner_id = ?)
AND status = 'PENDING';
业务代码是半年前写的,当时商家的门店数量只有几十家,子查询结果集 20 来条,执行计划没毛病。现在这个商家做了连锁,名下挂着 3000 家门店,子查询的结果集变成了几千行。MySQL 5.6 的优化器拿到 IN 子查询后走了 DEPENDENT SUBQUERY,外层每扫一行订单就重新跑一次子查询。订单表 2 亿行,这意味着子查询被执行了 2 亿次。
DBA 加了一行 hint 把 IN 子查询改写成 JOIN 之后,RT 从 8 秒降到 80ms。同一段逻辑,写法不同,性能差了两个数量级。
子查询不是语法糖,它是优化器最容易踩空的地方,也是写法风险最高的一类 SQL。
这一讲聊聊子查询为什么容易翻车,改写成 JOIN 是怎么救回性能的,什么场景该留子查询,以及在更大规模下这套改写逻辑又会被谁替代。
一、子查询到底慢在哪里
子查询读起来像自然语言,很像人类的思考方式:“先找出满足 A 的 X,再看哪些 Y 关联了它”。但数据库不是人,它的执行引擎是按关系代数运行的,子查询写法和执行效率之间有一道看不见的鸿沟。
1.1 相关子查询的 N+1 陷阱
子查询分两大类:相关子查询(correlated)和不相关子查询(non-correlated)。相关子查询的特征是内层 SQL 引用了外层的列,语义上意味着“对外层每一行都要重新计算一次内层”。
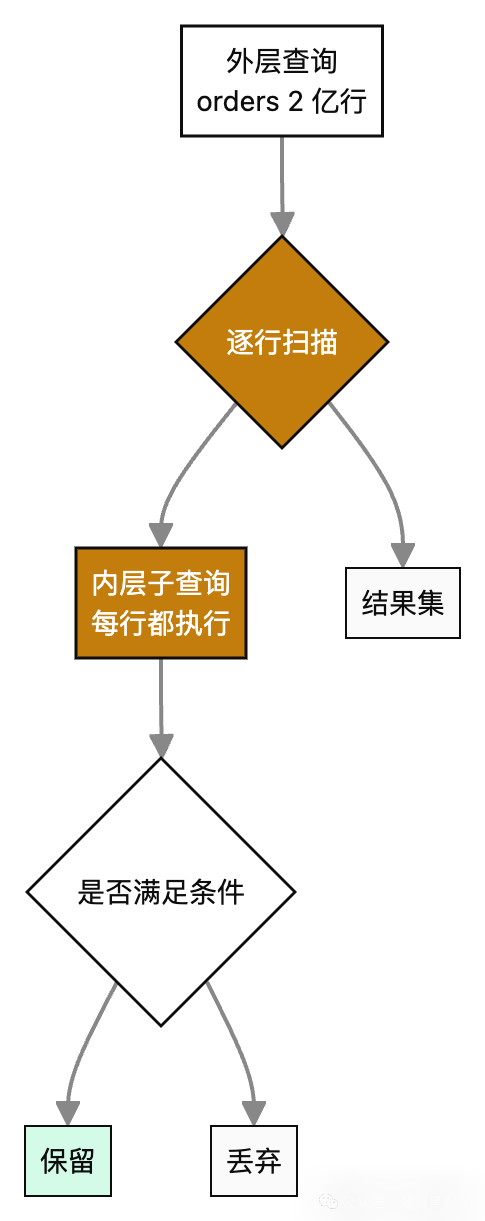
早期版本的 MySQL 在处理 WHERE EXISTS (SELECT ... WHERE s.id = o.shop_id) 这种相关子查询时,确实就是老老实实对每一行订单都跑一遍内层 SQL。2 亿行外层 × 每次内层 1ms 的查询,总耗时是 20 万秒,理论上永远跑不完。
MySQL 5.7 之后的优化器加了 semi-join、materialization 等改写能力,很多相关子查询能被自动转成 JOIN 或半连接,但转化是有条件的,一旦命中“不能物化”的规则,就会退化回 N+1 模式。
1.2 优化器对子查询的“半调子”支持
不同数据库、不同版本,对子查询的优化力度差别极大。下面这张表列一下常见场景的处理差异。

即使是同一段 SQL 语义,不同数据库引擎的执行计划完全可能天差地别。 这给跨库迁移、版本升级埋下了隐形雷,昨天跑得飞快的 SQL,换个环境可能直接打挂。
1.3 NOT IN 与 NULL 的历史包袱
NOT IN (SELECT ...) 是所有子查询里最坑的写法,原因不在性能,在语义。只要子查询结果里含有一个 NULL,整个 NOT IN 表达式就会返回 UNKNOWN,外层结果直接为空。
SELECT * FROM users
WHERE id NOT IN (SELECT user_id FROM blacklist);
这条 SQL 在 blacklist 表里没有 NULL 的时候一切正常,某天运营误录了一条 user_id 为 NULL 的黑名单,第二天所有用户都被“屏蔽”。这不是 bug,是 SQL 标准定义的 ANSI NULL 语义。
NOT IN 子查询在线上事故中占比极高,最稳妥的做法是改写成 NOT EXISTS 或 LEFT JOIN ... WHERE ... IS NULL,从根源上避开 NULL 陷阱。
二、改写成 JOIN:大多数场景的正解
既然子查询容易翻车,把它改写成 JOIN 是不是就稳了?在百万 QPS 以下的常规 OLTP 场景,答案是:大多数时候确实是正解。
2.1 IN 子查询转 INNER JOIN
最常见的改写模式。开头那条翻车的 SQL,标准改写:
SELECT o.* FROM orders o
INNER JOIN shops s ON o.shop_id = s.id
WHERE s.owner_id = ?
AND o.status = 'PENDING';
改写之后,优化器拿到的是一个明确的两表 JOIN,可以选择驱动表(通常是过滤性更强的 shops)、选择索引(owner_id 索引 + shop_id 索引)、选择连接算法(nested loop / hash join)。相比于 IN 子查询那种“先算出 3000 个值再逐个匹配”的隐式执行计划,JOIN 的执行路径清晰得多。
2.2 EXISTS 与 SEMI JOIN 的语义等价
EXISTS 是半连接语义:只要内层有一行满足,外层就保留。现代优化器识别到 EXISTS 之后,会尝试改写为 semi-join,避免对每一行外层都执行完整内层查询。
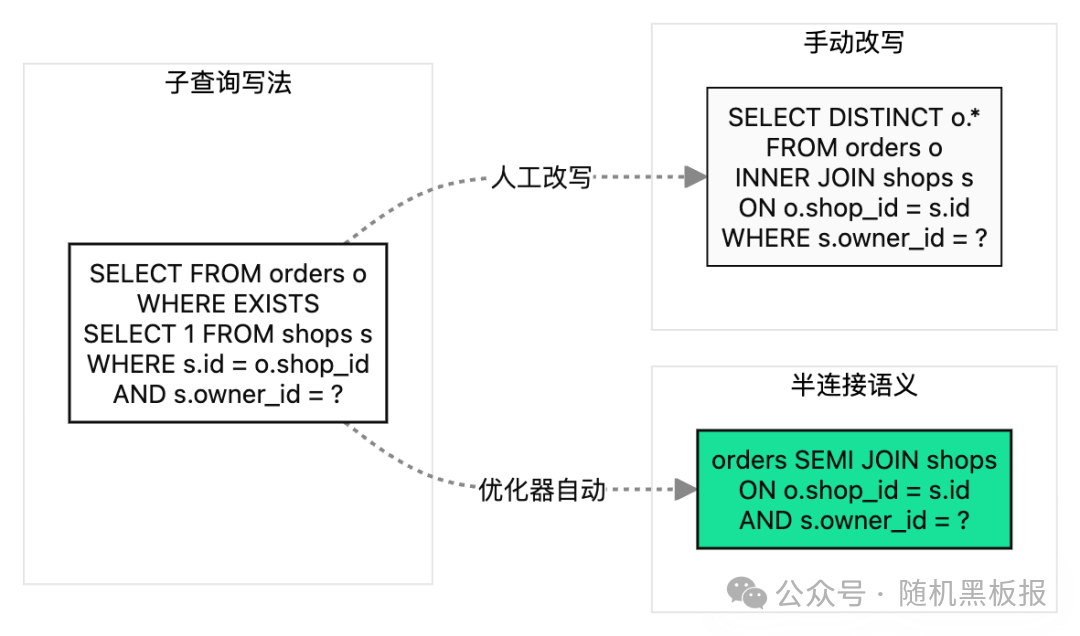
需要小心的是手动改写成 INNER JOIN 时,如果外层和内层是一对多关系,JOIN 结果会产生重复行。这时候要么加 DISTINCT 去重,要么确保 JOIN 条件能保证唯一性,否则返回行数会多出几倍。
EXISTS 改 JOIN 看似简单,实际暗藏“一对多导致结果膨胀”的坑,去重是不能省的步骤。
2.3 NOT EXISTS 转 LEFT JOIN IS NULL
反连接(anti-join)改写,是 NOT EXISTS 和 NOT IN 最推荐的等价形式。
SELECT u.* FROM users u
LEFT JOIN blacklist b ON u.id = b.user_id
WHERE b.user_id IS NULL;
这种写法的执行计划通常是索引驱动的 LEFT JOIN,性能稳定,不受 NULL 语义影响。两亿行用户表 LEFT JOIN 几万行黑名单,在 b.user_id 上有索引的前提下,优化器会生成 anti-join 执行计划,几十毫秒就能返回。
2.4 派生表(FROM 子查询)与 CTE 的取舍
FROM 子句里的子查询通常是用来做分组聚合之后再过滤的。例如:
SELECT * FROM (
SELECT shop_id, COUNT(*) AS cnt FROM orders GROUP BY shop_id
) t WHERE t.cnt > 1000;
MySQL 8.0.21 之前,派生表会被物化成临时表(可能落盘),外层的过滤条件无法下推到内层聚合中。8.0.21 引入的 derived condition pushdown 才开始把 cnt > 1000 改写为内层的 HAVING cnt > 1000,减少中间结果集。PostgreSQL 和 Oracle 多年前就支持谓词下推,改用 CTE(WITH 子句)可读性更好,但要留意 CTE 在某些引擎里是物化的,反而会阻止谓词下推,写之前最好用 EXPLAIN 确认。
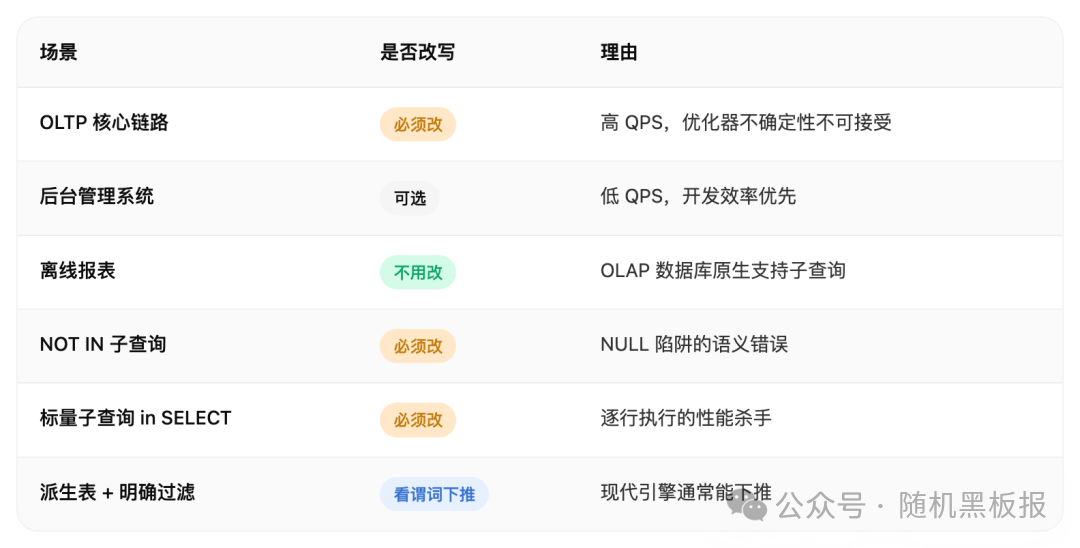
2.5 改写的决策矩阵
不同子查询类型对应的推荐改写方案可以总结成一张表。

三、为什么改写不是机械操作
子查询改 JOIN 听起来像是编译器优化该干的事。现实是,大多数优化器只能覆盖“标准型”改写,一旦 SQL 稍微复杂,就需要工程师自己来。
3.1 语义等价不等于性能等价
SQL 改写最大的陷阱,是改完“看起来跑对了”,但执行计划完全换了一条路。举个例子,IN 子查询改 JOIN 之后,MySQL 可能把 JOIN 驱动表选成了大表,因为统计信息里小表的基数被高估了。如果子查询时代正好走了一条冷门但最优的计划,改写之后反而变慢。
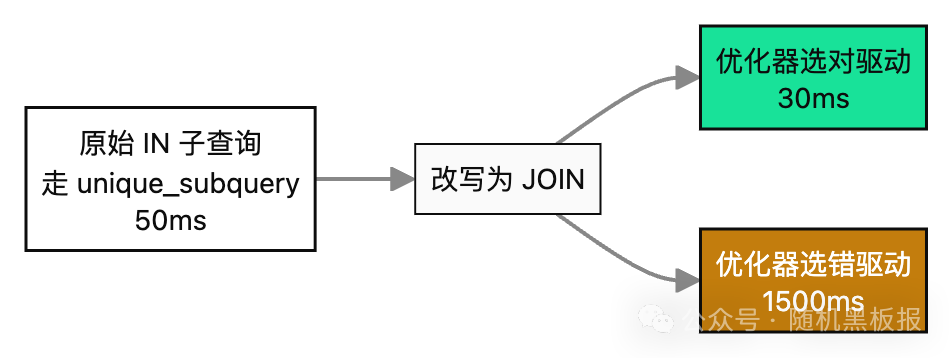
改写后必须 EXPLAIN 验证执行计划,对比改写前后的 type、rows、Extra 列,确认确实走了预期的索引和连接算法。这一步被省略,是线上事故的主要来源。
3.2 结果集等价性:NULL、重复、排序
改写的正确性判定比想象中复杂。IN 子查询和 INNER JOIN 的结果在“子查询结果有重复值”时是不一样的,前者是存在性语义(存在即匹配,不放大),后者是笛卡尔积(一对多会放大结果集)。
NULL 处理更是“重灾区”。下面这些场景都可能改出结果不等价的 SQL:
WHERE a IN (SELECT b FROM t) 里 t.b 有 NULL,改成 JOIN 不影响,因为 JOIN 天然不匹配 NULL
WHERE a NOT IN (SELECT b FROM t) 里 t.b 有 NULL,原 SQL 永远返回空,改 NOT EXISTS 才是正确语义
子查询返回空结果集,EXISTS 为 false,NOT EXISTS 为 true,IN 和 NOT IN 分别返回 false 和 true
把子查询改成 JOIN,不是纯粹的性能优化,它同时是一次语义重写,必须配合单元测试和数据比对才能上线。
3.3 组合型改写:一个 SQL 多处子查询
真实业务里,一条 SQL 里可能同时嵌套 3~5 个子查询,有的是 IN,有的是 EXISTS,有的是标量子查询。改写时不是逐个替换,而是要整体重写执行逻辑。
-- 原始 SQL:三处子查询嵌套
SELECT o.*,
(SELECT name FROM users WHERE id = o.user_id) AS user_name,
(SELECT COUNT(*) FROM order_items WHERE order_id = o.id) AS item_cnt
FROM orders o
WHERE o.shop_id IN (SELECT id FROM shops WHERE owner_id = ?)
AND EXISTS (SELECT 1 FROM payments p WHERE p.order_id = o.id AND p.status = 'PAID');
标量子查询被每一行外层触发,COUNT 子查询尤其昂贵。正确的改写思路是:user_name 走 JOIN users;item_cnt 聚合成临时表再 JOIN;shop 条件走 JOIN shops + owner_id 过滤;payment EXISTS 走 JOIN payments + status 过滤。四处子查询整合成一次 JOIN 图,执行计划从 O(N^k) 降到 O(N log N)。
这种重写往往伴随业务逻辑的重新梳理,是一件细活。
四、规模继续增长:JOIN 也不是终点
如果说百万 QPS 以下是“子查询改 JOIN”的主场,那么迈过百万 QPS 之后,JOIN 本身也会变成新的瓶颈。这时候改写的方向变了。
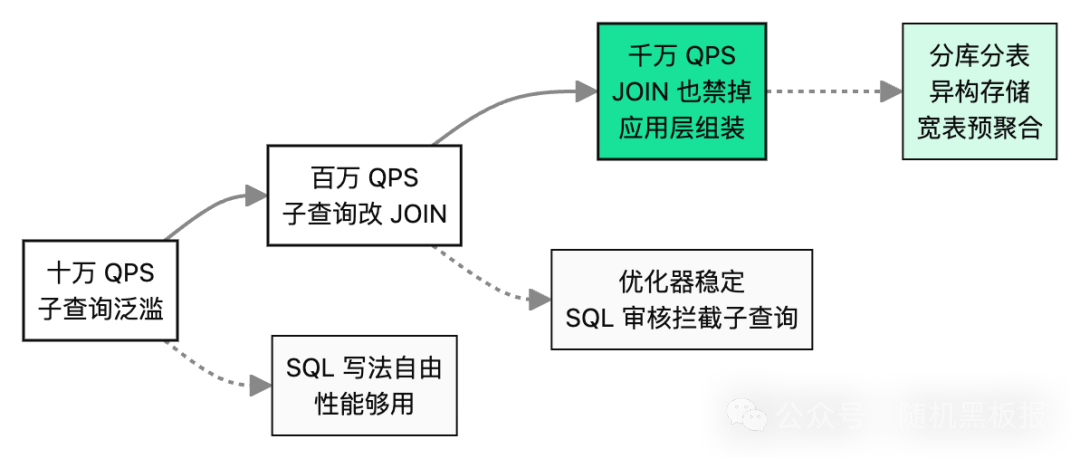
在千万 QPS 这个量级,核心表都已经水平拆分,任何 JOIN 都会跨分片,执行计划的不确定性成倍放大,继续依赖数据库做 JOIN 不现实。大厂 OLTP 的普遍做法是禁止 JOIN,数据在应用层组装。
所以子查询改写的终极答案不是“改成 JOIN 就完事”,而是:
小规模:子查询能用就用,关注正确性优先
中规模:子查询改 JOIN,加 SQL 审核拦截写法风险
大规模:连 JOIN 都不写,应用层按主键批量查询 + 内存拼装
不同规模下的 SQL 写法纪律,本质是优化器信任边界的退让。 规模越大,我们越不信任 SQL 优化器能稳定地给出最优计划,越要把执行路径从隐式变成显式。
五、治理:从人工 review 到 SQL 审核自动化
禁止问题写法、推动存量改造,光靠工程师自觉不行,必须把规则沉淀到工具链里。典型的治理体系分四层。
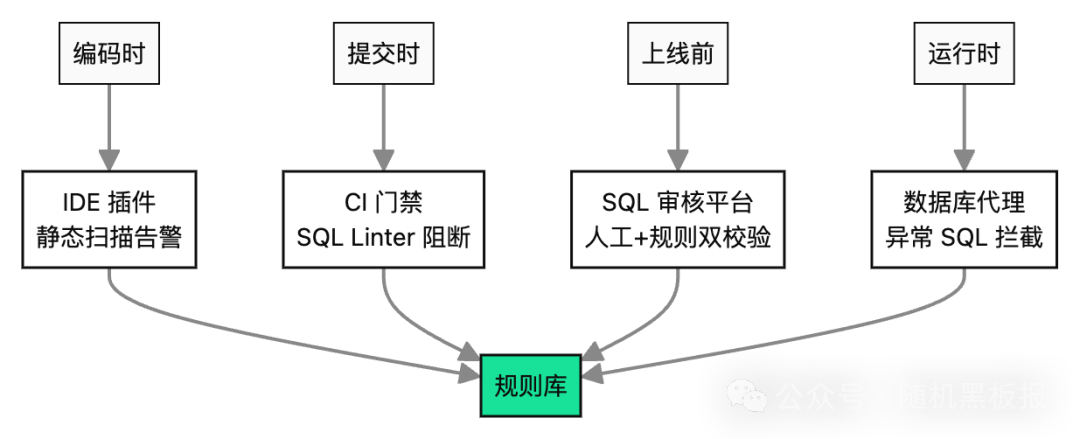
规则库是这套体系的核心,把“禁止 NOT IN 子查询”、“禁止 SELECT 子句中的标量子查询”、“派生表必须有 LIMIT”、“相关子查询必须 EXPLAIN 通过”这些知识沉淀成可执行规则。
IDE 阶段的插件基于 druid-parser 或 TiDB parser 做静态扫描,开发边写边提示。CI 阶段接入 SQL Linter(像阿里的 Yearning、美团的 NineData),扫描新增的 MyBatis Mapper 和 JPA 查询,发现违规直接阻断 merge。上线前的 SQL 审核平台做更深入的执行计划分析(EXPLAIN + 成本估算)。运行时的数据库代理(ProxySQL 扩展、私有 DAL)作为最后防线,识别到高危 SQL 直接降级或拒绝。这类实践在云栈社区的架构设计讨论中常有深入分享。
把 SQL 风险从“事后救火”变成“事前拦截”,是大规模系统稳定性的共同选择。
六、真实案例:一次全量改写的代价
某电商 2020 年做了一次跨部门的 SQL 改写专项,背景是核心交易库每周出 1~2 次慢 SQL 告警,根因集中在子查询。专项的节奏大致如下。
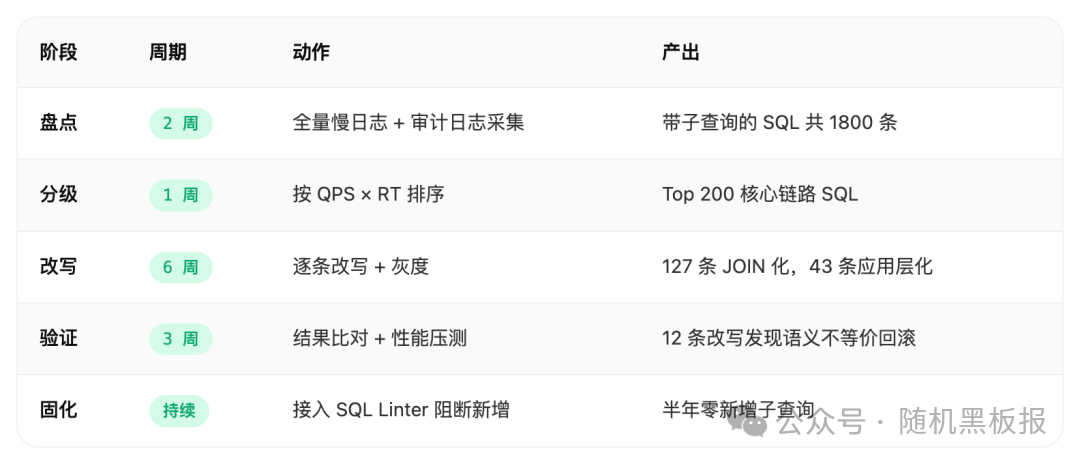
6 周专项投入了 8 位工程师的人力,改造后核心库 CPU 从 75% 峰值降到 45%,P99 RT 从 400ms 降到 120ms。真正的收益不是这一次改写带来的性能提升,而是后续半年再没有出现同类故障,因为每一条新增 SQL 都会被流水线自动拦截。
专项中最大的教训是语义不等价的隐蔽性。有 12 条 SQL 改写后跑通、压测通过、灰度三天没问题,直到遇到了特定的 NULL 数据或重复数据才暴露错误。所有改写都必须配对写数据比对脚本,用真实流量做结果集对比,这是唯一可靠的正确性保障。
七、什么时候可以不改写
一刀切的规则工程上不成立,总有场景适合保留子查询的写法。
偶发查询和后台管理。报表系统、运营后台、客服工具的 SQL,QPS 低、RT 要求宽松、开发效率优先,子查询随便写,优化器也能应付。
确实更清晰的表达。某些聚合场景用派生表比多层 JOIN 可读性更好,比如“先按 shop 分组统计销量,再筛选 Top 10”,用 CTE 比改成多层 JOIN 更自然。可读性本身也是工程价值。
小数据量子查询。内层子查询结果集稳定在几十行以内,优化器能物化成临时表,相关子查询也能被改写为 semi-join,这种场景改不改 JOIN 差异很小,按团队习惯即可。
八、从写法自由到工程纪律
回到开头那条把数据库打挂的 IN 子查询。在几十家门店的时候,它是合格的业务代码;在 3000 家门店的时候,它是一个定时炸弹。同一段 SQL,不同规模下的行为完全不同,这正是大规模系统最棘手的地方。
子查询改写的本质,是把优化器决策替换为工程师显式决策,把隐式的执行路径替换为明确的 JOIN 图,把语义正确但性能不确定替换为语义正确且性能可预测。这三层递进,是从十万 QPS 走向百万 QPS 的共同课题。
继续往上走到千万 QPS,连 JOIN 也会被彻底禁掉,数据库退化成“按主键查询”的 KV 存储,所有关联在应用层组装。那时候再看 SQL 写法的约束,就会理解为什么大厂的 SQL 规范里禁子查询、禁 JOIN、禁 UNION 不是吹毛求疵,而是被规模逼出来的工程纪律。关于这方面的深度实践,可以参考系统设计与高并发架构中的相关讨论。
好的 SQL 写法不是“优雅的语法糖”,而是“优化器能稳定执行的显式计划”,这两件事在小规模时看不出差别,在大规模时天差地别。
你的代码仓库里,最后一条需要被改写的子查询,会藏在哪个角落?
 发表于 2026-5-13 16:17:48
|
查看: 112|
回复: 0
发表于 2026-5-13 16:17:48
|
查看: 112|
回复: 0
