你有没有过这样的遭遇:凌晨1点,DBA在群里@你说「order_status 字段的索引现在加上来一下」。你们的订单库分了 16 个库 × 8 张表。理论上加索引就是 ALTER TABLE,按理几分钟就完。
实际跑起来呢?128 张表挨个加,每加一张就可能锁几十秒到几分钟。中间有张表恰好被一条长事务卡住,直接锁了 5 分钟。下游的订单详情、退款查询、对账作业全部跟着抖——告警群从凌晨1点响到天亮。
我就是在那一夜重新意识到一件事:我们花了大半年设计的这套分库分表方案,给业务带来的不再是性能红利,而是每次变更都要熬一个通宵的成本。
这篇文章想聊聊:分库分表为什么正在从「标配」变成「历史遗留」,以及现在做技术选型该往哪走。当然,这并非一家之言,在云栈社区的技术讨论中,越来越多一线开发者也在分享类似的迁移实践。
倒回 2010 年:那时候没有更好的选择
时间拉回到 2010 年前后。那时候 MySQL 是绝大多数互联网公司的标配,单表数据扛过几千万行就开始明显吃力。电商、社交、支付这些业务,数据量涨得飞快,服务器配置堆到头也扛不住。
解法只有一个——拆。按某个维度把数据打散,分到多张表、多个库里。
那个年代 还没有成熟的分布式数据库:MySQL 分区表有局限、Oracle 太贵,剩下能选的也就是这一套。淘宝、美团、微博这些大厂都在用,社区里整天讨论怎么选分片键、怎么做数据迁移,热度高得很。
它确实解决了问题——至少当时解决了。单库扛不住的写入量拆成 16 库 16 表,扛住了流量、留住了用户。这是它的历史功劳,不能否认。
5 个真坑 · 大坑 vs 小坑
但凡真正在项目里维护过分库分表的,这几个坑基本都踩过。按破坏力排,大坑致命,小坑磨人。

🔴 大坑 1:分片键选错,几乎不可逆(最致命)
分片键是整个方案的基础。你用 user_id 分片,查单个用户是挺快。可业务一提出「按商家查所有订单」「按手机号反查用户」这种需求——中间件只能去所有库里捞数据、再合并结果,慢得离谱。
想换分片键?那得停服、重新导数据、重新验证。亿级别表光迁移就要 2-3 天——这时间窗你赔得起吗?
🔴 大坑 2:跨库 JOIN 几乎不能用(高频踩到)
「用户 + 订单 + 商品」三张表,原来一条 SQL 就搞定了。分库分表之后它们可能散落在不同库里,中间件并不支持真正的跨库 JOIN——只能在应用层手拼。
先查用户、再批量查订单、再批量查商品、最后在 Java 代码里组装。这类胶水代码写起来繁琐、出错率高——一个简单的列表页,可能要写 50 行手工拼装逻辑。
🔴 大坑 3:分布式事务,吃力不讨好(破坏力大)
下单得同时写订单库和库存库,两个写操作要么全成功要么全失败。但写在不同 MySQL 实例上,本地事务根本管不到——你只能引入 XA 或 Seata。
- XA:性能损耗大,并发一上来就明显抖;
- Seata:配置复杂、出问题难排查,线上事故"从找根因到能复现"动辄几个小时;
- 最终一致性 + 补偿:很多团队最终放弃强一致性,靠补偿逻辑兜底——可补偿逻辑本身就是新的复杂度来源。
🟡 小坑 1:扩容不是弹性扩容
业务数据涨了,原来 8 库不够,想扩到 16 库。理论上可行,实际操作得凌晨手动跑一晚上:停写 → 重新哈希迁移 → 改分片配置 → 验证 → 恢复写入。
整个过程 要人盯着、要写脚本、要做演练、要预留回滚通道——「弹性」这两个字,跟分库分表基本不沾边。618 或双十一这种突发流量场景,几乎只能预先扩容,没法临时加机器。
🟡 小坑 2:SQL 限制不少(写代码时一直得绕)
聚合函数、ORDER BY、GROUP BY 在分库分表环境下都有坑:
ORDER BY 要在中间件层做二次排序,数据量一大容易 OOM;LIMIT 100000, 10 这种深翻页——中间件要从每个库各取 100010 条再合并,吃内存也吃时间;- 跨库聚合(
COUNT DISTINCT / 多维 GROUP BY)几乎做不了——逼着你绕到 ES 或者离线计算上去。
这些限制真不是中间件的问题,是架构本身带来的。它意味着写每一条复杂 SQL 之前,你都得先想想:"这条会不会触发跨库扫描"。
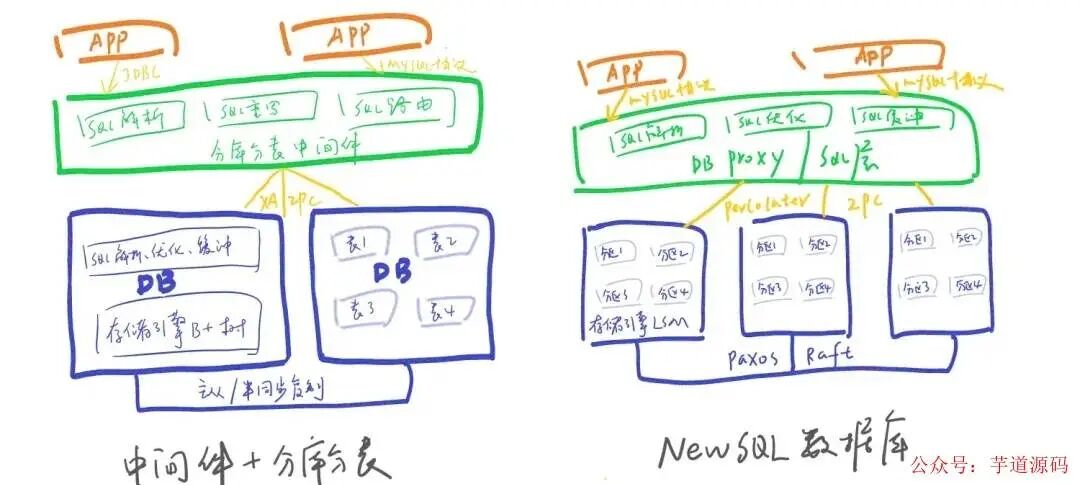
NewSQL 这十年悄悄起来了
就在大家还在纠结「分 8 库好还是分 16 库好」的时候,一批新数据库已经悄悄冒了出来。
2012 年 Google 发了一篇关于 Spanner 的论文,讲了一套全球分布式关系型数据库的实现。这篇论文后来被业内奉为经典,核心思想是:存储和计算分离,数据自动分片,事务保证全局一致性,用户面对的还是标准 SQL。
这些年间国内外涌现出一批 NewSQL:TiDB、OceanBase、CockroachDB、YugabyteDB、PolarDB-X。这类数据库 结合了传统 RDBMS 的 SQL 能力与分布式系统的扩展能力。
跟分库分表一比,NewSQL 一次性把三件事全做对了:
- 🚀 对应用透明——你不必关心数据在哪个节点,不用选分片键,不用写跨库逻辑,SQL 该怎么写就怎么用;
- ♾️ 计算 + 存储双向无限扩容——计算节点(TiDB Server / CN)撑不住就加,存储节点(TiKV / DN)撑不住也加,两个维度独立伸缩、互不绑死;
- ✨ 用起来简单——不再有「分片键怎么选」「16 库还是 32 库」「明年要不要再扩一倍」这种需要提前拍板的决策——今天先用着,业务起来了再加节点。
一句话:分库分表是一次性预算 + 永久维护成本;NewSQL 是按需付费 + 几乎零运维决策。
主流 3 个产品:我自己用 / 朋友在用 / 候选
下面按我自己和身边圈子的真实使用情况来聊——不是广告,只讲谁实际在用什么。当然,大家的业务场景千差万别,在云栈社区的架构讨论区里,关于这几款产品的优劣势也一直有持续的交流。
TiDB(PingCAP)—— 我自己项目在用
开源 + 兼容 MySQL 协议 + HTAP(事务和分析同一套系统)。截至 2025 年初已超过 4000 家企业在用——越南支付平台 ZaloPay、杭州银行等金融场景都在跑。
| 维度 |
评价 |
| 适合 |
数据量大、有实时分析需求、有自运维能力的团队 |
| 致命短板 |
资源消耗不小——最小生产集群要 3 个 TiKV + 3 个 PD,机器成本不低 |
| 云托管 |
TiDB Cloud / 国内 TiDB Serverless |
我自己:业务库就在用 TiDB——HTAP 实时分析体验确实好,日常跑 OLTP 的同时顺手做几个核心报表的 OLAP 查询,直接省了一套 ClickHouse 的部署。
PolarDB-X(阿里云)—— 朋友团队在用
阿里系产品。从早期的 DRDS(云上分库分表产品)一路演进而来,后来重构成了真正的分布式数据库。双十一是它的压力测试——2025 年 2 月 TPC-C 跑出每分钟 20.55 亿笔,刷新了世界纪录。
飞鹤集团用 PolarDB 分布式版替换了原有分库分表方案,迁移后业务处理量提升 200%、慢 SQL 减少 90%、运营成本降低 40%。
| 维度 |
评价 |
| 适合 |
已在阿里云上的团队、希望有完整商业支持 |
| 致命短板 |
深度绑定阿里云,私有化部署相对复杂 |
我身边有朋友团队在用 PolarDB-X——他们已经全栈跑在阿里云上,用 PolarDB-X 的弹性扩缩容体验比自建 TiDB 省心,618 临时加节点就是控制台上点一下。
OceanBase(蚂蚁)—— 也有朋友团队在用
从阿里内部交易系统里长出来的,稳定性和事务能力是核心优势。南方航空、厦门地铁这些对一致性要求极高的场景都在用。
我有几个金融行业的朋友团队在用——他们核心系统不能丢一笔数据,OceanBase 的强一致加自动容灾特别对路。
| 维度 |
评价 |
| 适合 |
金融 / 政务,对高可用要求严格、不容许数据丢失 |
| 致命短板 |
运维复杂、社区文档比 TiDB 少、国际化弱 |
还没死透:3 类场景里它仍然合理
有人会问:那分库分表彻底没用了?不是这样的。
| 场景 |
为什么仍然合理 |
| 老系统跑得稳 |
迁移风险和成本远大于好处,老项目稳定运行就是价值 |
| 小团队 / 数据量不大 |
上一套 NewSQL 集群,机器成本、学习成本、运维成本全上来了,划不来 |
| 对厂商有顾虑 |
中间件底层还是 MySQL,读写行为和锁行为都是你熟悉的 |
所以「淘汰」这个词其实不够准确。更准确的描述是:分库分表正在从「首选方案」变成「备选方案」。
数据量没到大盘?先用「分区表」过渡
很多人一碰到「单表过亿」就立刻往分库分表上冲——先别急。
MySQL 8.0 / PostgreSQL 都原生支持分区表:单实例、单数据库内部按时间或 hash 把一张大表切成多个物理分区,对业务 SQL 完全透明。
| 数据量 |
推荐方案 |
| < 1 亿 |
优化 SQL + 索引——大概率不需要拆 |
| 1 - 10 亿 |
数据库分区表(按时间分区最常见,比如订单按月分区) |
| 10 - 50 亿 + 写入热点 |
NewSQL 或分库分表 |
| > 50 亿 / 多维度查询 |
NewSQL + ES |
分区表的优势很直观:
- 不引入中间件,没有跨库 JOIN 和跨库事务的烦恼;
- DDL / 备份按分区做,不用锁全表;
- 历史数据归档容易——直接把老分区 detach 然后落冷存。
分区表能扛的数据量比你想象的大得多——MySQL 8.0 单库十亿级数据,配合合理分区和索引完全跑得动。我见过不少项目硬上了分库分表,结果发现单库分区表加读写分离就能解决 90% 的问题。

分库分表里的复杂查询,建议引入 ES
如果你已经身处分库分表的体系里——千万别硬刚多维查询。
「按用户查订单」可以走分片键,但「按商家 ID 查」「按手机号反查」「按状态 + 时间区间统计」这类查询,分库分表中间件是做不来的。硬刚的结果就是开头那个故事:广播全库、内存合并、然后 OOM。
正确的做法:把查询需求拆出来,扔到 Elasticsearch。
MySQL(分库分表) ──binlog──► Canal / 阿里云 DTS
│
▼
Elasticsearch
│
▼
多维查询 / 全文检索 / 聚合统计
为什么 ES 适合干这个:
- 倒排索引让多维度过滤在毫秒级返回;
- 聚合统计比中间件做内存合并快 10-100 倍;
- 全文检索 + 模糊匹配是传统 SQL 永远做不到的能力;
- 数据冗余成本低——几 TB 的 ES 集群成本,远低于多扩一倍的 NewSQL 集群。
实际落地路径很清晰:MySQL 负责写订单(保证事务)→ 通过 binlog 同步到 ES → 所有复杂查询全走 ES。这种「分库分表 + ES 双写」的组合,已经扛住了国内不少头部电商的搜索、运营后台和报表查询场景。
决策矩阵:你属于哪一象限?
动手选型前,先问自己 3 个问题:
- 数据量到底在哪个量级?——很多「数据量大」的烦恼,优化 SQL 往往就解决了。真要看到「单表 > 1TB / 日增 > 10GB / DDL 失败 / 备份超时 / 写入瓶颈 / 多维查询无解」这些信号里的任意一条,才该动手拆。
- 团队有没有人能维护?——TiDB / OceanBase / PolarDB-X 出问题时,不像 MySQL 那么容易排查。得有人能看 slow query log、理解 Region 热点、处理 MVCC 写入放大。既缺人又没预算买商业支持,选型就得格外慎重。
- 业务对 SQL 兼容性多敏感?——新系统问题不大;老系统迁移得认真测,尤其是用了 MySQL 特有语法、存储过程、触发器的地方。迁移前,务必跑一遍全量 SQL 回放。
我的判断
分库分表确实解决过真实的问题,帮很多团队扛过了那个没有更好选择的年代。但它是为了填补 10 年前的技术空缺——那时候我们没得选。
现在有了。
就像你不会再用软盘备份数据——不是软盘有问题,是有更好的东西出现了。
3 条建议:
- 新项目:认真看看 TiDB / OceanBase / PolarDB-X;如果数据量还没到那个份上,优先上分区表 + ES;
- 老项目:评估迁移成本,别为了换而换——能跑稳就先稳稳跑着;
- 正在维护分库分表的同学:也不必焦虑——把它跑稳就行,等真正需要升级的时候再动不迟;如果眼下就有复杂查询的痛点,先引入 ES,这是性价比最高的选择。
技术选型没有标准答案,合适的才是好的。
 发表于 2026-5-22 03:21:37
|
查看: 93|
回复: 0
发表于 2026-5-22 03:21:37
|
查看: 93|
回复: 0
