导读:OLTP 与 OLAP 长年“分居”,ETL 管道撑不住实时分析。HTAP 把数仓的一层拆回数据库内部,用行列双存、Raft Learner 同步、MPP 执行器和资源隔离,让一张表既能扛事务又能跑分析。走到千万 QPS,物理隔离几乎是唯一选项。
凌晨三点的那个“简单报表”
凌晨三点,运营同学在群里艾特你:“帮忙跑个数据,最近 24 小时各城市订单金额 TopN,老板等着看。”
你心里一紧。这要是白天倒还好,偏偏是凌晨,订单库刚好在批量处理结算。你凭经验知道,这条 SQL 拉下去,大概率会把主库 CPU 打满,接着就是下单接口超时、监控告警轮着响,最后被拉群复盘。
于是你只能回一句:“等同步库出数据,大概 15 分钟。”运营同学不情愿地等着,老板比运营更不情愿。
这就是 OLTP 和 OLAP 长期分家带来的尴尬:一边是在线交易系统对延迟极度敏感,一边是分析系统对扫描范围极度贪婪,两者共享一张表,等于在马路上搭了个临时舞台。 而当业务规模从百万 QPS 推到千万 QPS,这种尴尬不再是凌晨偶尔的剧情,而是每分钟都在上演的日常。
HTAP 架构的意义,就是想把这场戏彻底从马路上挪走。
一张表为什么“分居”了这么多年
要理解 HTAP,得先理解 OLTP 和 OLAP 为什么会“分居”。
两个世界,两种口味
OLTP 和 OLAP 从诞生开始,追求的就是完全不同的东西。OLTP 要的是点写点读:一笔订单下单、一次余额扣减、一条消息插入,毫秒级响应,短事务,高并发。OLAP 要的是大范围扫描:最近一个月的销售漏斗、全国用户的行为分布、多维度交叉分析,秒级甚至分钟级都能接受,但一次请求可能要读几亿行。
这两种负载放到一个引擎里会打架。行存对点查友好,列存对聚合友好;B+Tree 适合高选择度的范围查询,LSM 适合写密集,而分析型负载常常需要列式压缩加向量化执行。同一份数据放在行存里跑分析,就像让短跑运动员去跑马拉松,结构性吃亏。
于是早期的做法很朴素:做两套。OLTP 放一套 MySQL 或 Oracle,OLAP 放 Teradata、Greenplum,中间用一条 ETL 管道搬数据。夜里低峰期把当天交易抽过去,白天分析师在数仓里随便查,互不打扰。
ETL 管道的裂痕
这条路走了二十年,后来开始裂开,原因有三个。
第一,数据越来越新鲜才有价值。以前的报表看昨天就够了,现在做实时风控、实时推荐、实时大屏,业务方要看的是“最近 5 分钟”甚至“最近 30 秒”。T+1 的 ETL 显然不够;换成 CDC 加流式 ETL,延迟能压到分钟级,但复杂度陡增。
第二,数据规模涨得太快。千万 QPS 的系统,一天可以产生几十亿条变更日志,ETL 管道成了新的故障源。你常常会发现:线上 OLTP 没问题,数仓却因为一个上游的 schema 变更停了一整天。
第三,两套系统的一致性很难讲。主库转账成功了,数仓还没同步到,风控基于旧数据放过了一个可疑账号,这种口径错位在高并发场景下会被放大。数据分家的代价,不只是多一条管道,而是多一套需要运维的“真相”。
下面这张图,大致勾勒出从分家到融合的演进脉络。
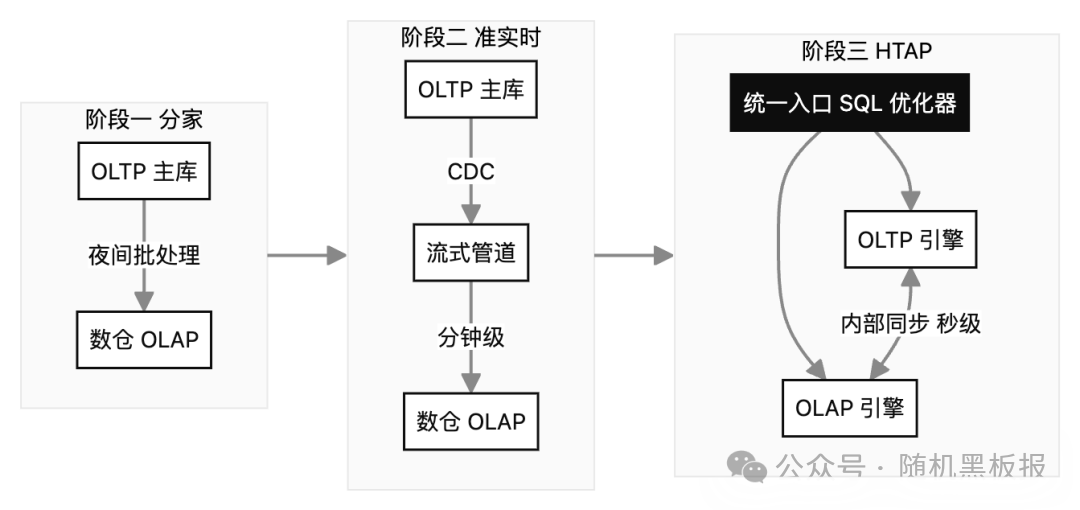
HTAP 不是凭空造出来的新物种,而是数据架构被业务逼着演进的结果。
HTAP 到底在融合什么
讲 HTAP,容易陷入一种误区:以为只要同一个数据库既支持事务又支持分析就叫 HTAP。其实细看下去,不同产品的“融合”含义差别很大。
融合的三个层次
第一层是存储融合。同一份数据既能被 OLTP 按行访问,也能被 OLAP 按列扫描。典型做法是同时维护行存副本和列存副本,通过 Raft 或类似协议保持一致。
第二层是计算融合。同一个查询引擎能根据代价模型自动选择走行存或列存,甚至在一个查询计划里混合使用。做得好的系统,用户完全感知不到底层的存储格式。
第三层是资源融合。点查和大查询跑在同一个集群里,但互不影响。这需要细粒度的资源隔离:CPU 分组、IO 带宽限制、内存配额、优先级调度,缺一不可。
下面这张表是业内几家代表产品在这三层上的取舍。

没有一家是三层都做到极致,差异决定了它们适合的场景。
不是所有“混合”都叫 HTAP
有两种常见的“伪 HTAP”值得警惕。
一种是主从扩展型:主库跑 OLTP,从库开一个列存插件跑 OLAP。看起来融合了,但本质还是两套引擎加一条复制链路,延迟、一致性、故障切换都和传统方案差别不大。
另一种是导出联邦型:OLTP 的数据通过物化视图或外部表暴露给分析引擎,查询时联邦执行。这种方案灵活,但对复杂查询性能很差,更像一个临时过渡方案。
真正的 HTAP,起码应该满足一条:同一份数据的写入和分析,都由数据库内部闭环承担,对用户呈现为单一系统。 这条标准之下,行列双存加内部同步算是主流路线。
行列双存,怎么不打架
讲到这里,很多人会问一个直观的问题:行和列同时存一份,存储不就翻倍了?同步不就又多了一条链路?还不如回去用 ETL。
这个问题很合理,HTAP 引擎之所以能跑得动,靠的是几个关键设计。
列存副本:从 ETL 到 Raft Learner
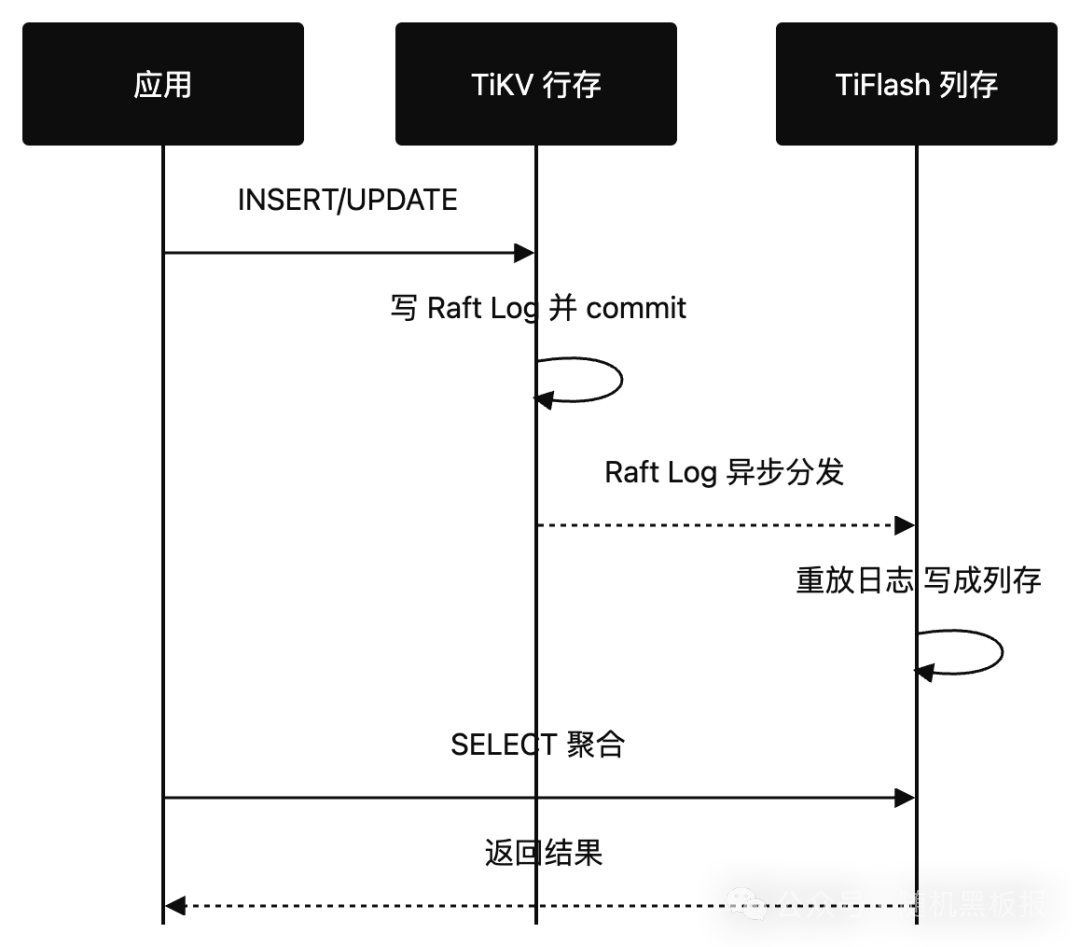
早期的行列同步是通过日志订阅:OLTP 引擎把 binlog 或 redo log 抛出来,列存侧消费、解析、重组、落盘。链路长,延迟高,而且中间任何一环挂掉都会导致数据不一致。
主流 HTAP 引擎换了思路:把列存副本直接嵌进一致性协议。以 TiDB 为例,它给 TiFlash 副本挂上 Raft Learner 角色:只接收日志、不参与投票、不影响 OLTP 写入延迟。从主副本拉日志,本地重放时直接写成列存格式,跳过了中间 ETL。
这样做有三个好处:同步延迟低到秒级甚至亚秒级;故障时副本会自动被 Raft 感知并补齐;写入路径不需要用户做任何改动,对应用透明。
下面是一个简化的写入路径。
列存的写入放大问题
列存天然不擅长随机写:每次更新都要重写一整列,哪怕只改一个字段。HTAP 引擎在这里普遍用两段式设计:最新写入的数据放在一个小的 Delta 结构里(通常还是行存或者行列混合),达到阈值后整体 flush 成列存段。
这带来两个新问题。一是读请求要同时扫 Delta 和列存段,合并结果;二是 Delta 段多了会拖慢查询,需要后台 Compaction。这套“行存接写、列存接读”的内部结构,是 HTAP 存储层最大的工程复杂度所在。
一致性:快照读是救星
OLAP 查询常常跨越几分钟甚至几十分钟,这期间 OLTP 侧可能发生上千万条变更。如果每条变更都要反映到分析结果里,查询根本收敛不了。
HTAP 引擎普遍用 MVCC 快照读解决:分析查询开始时拿到一个全局时间戳(TSO),后续所有读取都基于这个时间戳之前的版本。这样一次查询看到的数据是一致的,哪怕它跑半小时。快照读让分析查询拿到“凝固的现场”,而 OLTP 侧依然可以自由写入。
查询怎么自动选引擎
存储融合解决了“数据在哪”的问题,查询融合解决的是“怎么算最快”的问题。
代价模型的升级
传统 OLTP 数据库的优化器只需要考虑索引选择和连接顺序,数据结构就一种。到了 HTAP,优化器必须多判断一件事:这个查询该走行存还是列存?是不是还能拆成两部分,一部分走行存、一部分走列存?
代价模型会综合几个因素:查询的选择度、扫描的数据量、是否有聚合或分组、是否命中行存索引、列存副本是否已经同步到最新。一个典型的规则是:点查和小范围查询走行存;全表扫描、大聚合、窗口函数、多表关联走列存。
MPP 执行器
OLAP 查询动辄扫描几亿行,单节点算不过来。HTAP 引擎普遍内置 MPP(Massively Parallel Processing)执行器:查询计划会被拆成多个 fragment,分发到不同列存节点并行执行,中间结果通过 Shuffle 汇聚。
这套东西本来是 Greenplum、ClickHouse 这类专用分析引擎的标配,现在被 HTAP 引擎吸收进来。从架构图上看,它通常长这样。
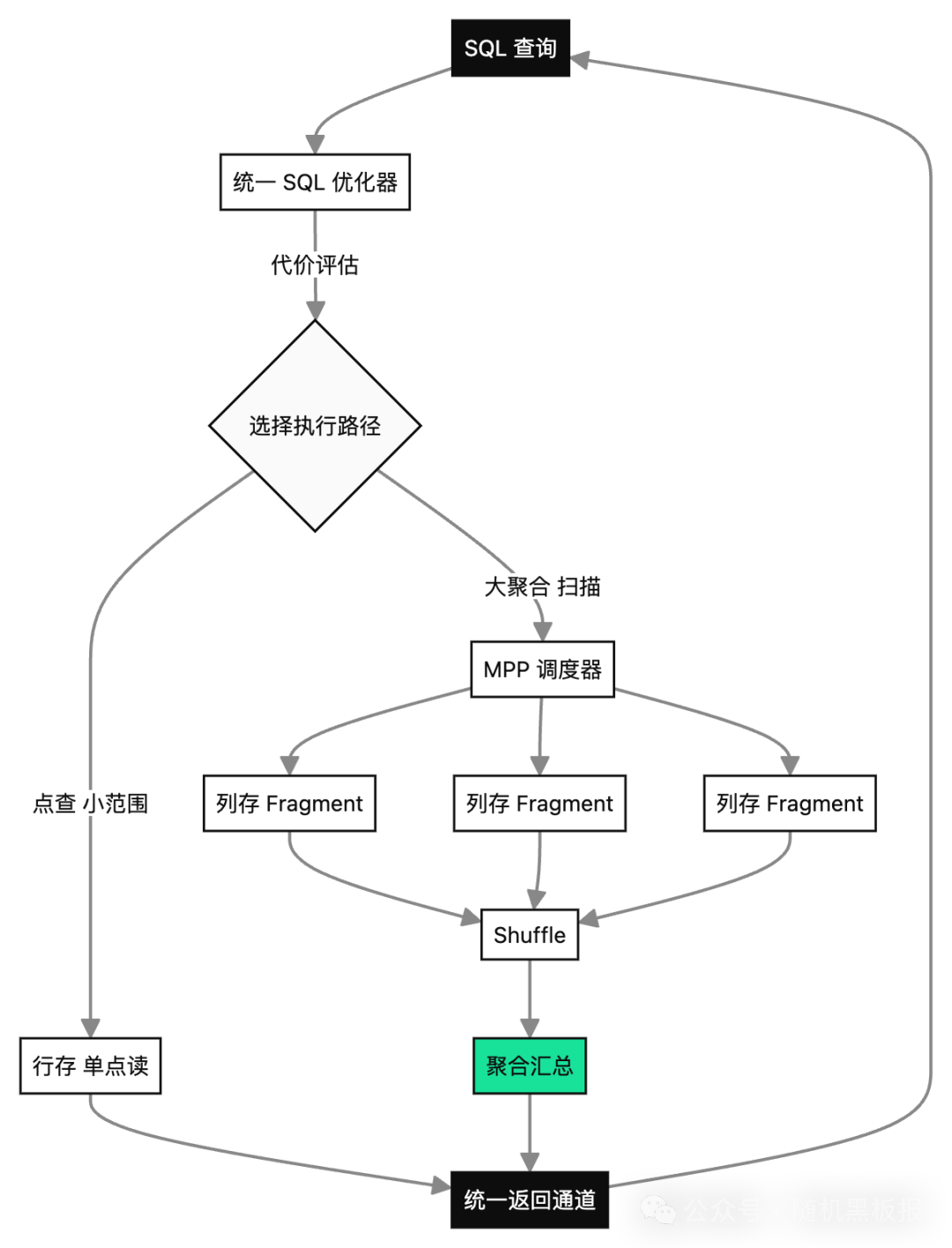
HTAP 的“融合”在查询层的真正体现,是用户写一条 SQL,系统自动决定哪段走行存、哪段走列存、哪段起多少个并行度。
自动路由的代价
这种自动化不是没有代价。代价模型的准确度严重依赖统计信息;列存副本的延迟会影响选择决策;MPP 节点数一多,调度和 Shuffle 本身就会成为瓶颈。真正上了千万 QPS 规模之后,DBA 依然要手动干预一些关键查询的执行计划,比如用 hint 强制走列存,或者把某张小表改成广播。
这一点值得提醒:HTAP 的“透明”是相对的,极端场景下还是需要人为介入,把默认策略校准到贴合业务形状。
资源怎么不打架
行列双存和智能路由解决了“能跑”,资源隔离才决定“能不能稳定跑”。
物理隔离:最朴素也最有效
最直接的办法是把行存节点和列存节点分开部署。OLTP 的 TPS 再高,分析查询再慢,两者跑在不同的 CPU 和磁盘上,天然不会互相干扰。
TiDB 就是典型的物理隔离:TiKV 节点负责行存和 OLTP,TiFlash 节点负责列存和 OLAP。故障域、扩缩容策略都可以各自独立。代价是硬件成本翻倍,部署和运维复杂度也更高。
逻辑隔离:租户和资源组
共享节点的 HTAP 引擎走的是逻辑隔离路线:在同一个进程里划分资源组,每个组有自己的 CPU 配额、内存上限和 IO 优先级。OceanBase 的“租户”、SingleStore 的“Workload Group”都是这个思路。
逻辑隔离对调度器的要求很高。内存是典型的难点:OLAP 查询一不小心就能吃掉几十 GB,而 OLTP 的瞬时写入又要尽量低延迟。解决方案通常是:给 OLAP 查询设硬内存上限,超过就落盘;给 OLTP 预留最小保证,不被 OLAP 抢走。隔离的本质不是“公平”,而是“保主干”,任何情况下 OLTP 的延迟都不能被 OLAP 拖垮。
下面这张表对比一下两条路线的差异。

当 QPS 上到千万
从十万 QPS 到百万 QPS,逻辑隔离通常够用,OLTP 的绝对压力还没到拖垮整机的程度。但从百万推到千万,情况会变:OLTP 侧已经吃掉大半资源,任何和 OLAP 共用 CPU 的设计都会暴露问题。这时候物理隔离几乎是唯一选项。
一个行业观察是:千万 QPS 规模的 HTAP 实践,几乎全部采用了物理隔离的行列双存路线。 OLAP 查询即便慢一点,运营和分析师也能接受;OLTP 抖一抖,用户立刻感知。优先保 OLTP,是这个规模下的默认选择。
一致性与延迟的边界
HTAP 号称让 OLAP 查到“实时数据”,但这里的“实时”需要被仔细定义。
延迟预算
列存副本的同步延迟取决于三件事:日志产生速率、网络带宽、重放速度。典型的数字是:单机几万 QPS 下,延迟在 100ms 以内;跑满千万 QPS 规模,延迟可能会漂到几秒甚至十几秒。对大多数分析场景,这个延迟可以接受;对强实时的风控场景,就要谨慎。
读新鲜度的权衡
应用可以选择两种读模式:一种是“读到就行”,允许拿稍旧的快照;另一种是“必须最新”,这时引擎会先等待列存副本追上,再返回结果。后者叫 stale read 的反面:fresh read。
Fresh read 的代价是 P99 延迟抖动,坏处会体现在业务敏感的大屏和仪表盘上。 所以在实践中,风控这种对新鲜度极度敏感的场景,常常不走 HTAP 列存,而是走 OLTP 行存加索引,牺牲一部分分析能力换确定性。
跨引擎事务
更极端的问题是:在一个事务里既要读行存又要读列存,怎么保证一致?HTAP 引擎的常见做法是所有读基于同一个事务时间戳,行存和列存都按这个时间戳读快照。具体实现要么靠 TSO 集中发号,要么靠逻辑时钟,工程复杂度都不低。
HTAP 适合谁,不适合谁
HTAP 不是银弹,有它的边界。
适合的场景
运营后台的实时报表:数据量大但并发不高,列存扫描性能好,行存侧事务性足够。
在线业务的风控决策:需要基于历史行为做聚合判断,延迟几百毫秒可以接受,又要和交易事务一致。
交易型大屏:要求看最近几分钟的交易趋势,实时刷新。
中小规模的数据平台:业务还没大到需要独立数仓,但已经受不了 ETL 的复杂度,用 HTAP 简化架构。
不太合适的场景
超长周期的离线分析:历史跨度几年的明细表做复杂关联,HTAP 列存扛得住但成本不低,专用数仓更合适。
机器学习特征工程:需要大量特征回溯和样本生成,批处理能力是核心,HTAP 的实时性没优势。
成本极度敏感的中小业务:双存储、双节点的硬件成本,对百万 QPS 以下的业务经常是负担大于收益。
和传统数仓的关系
HTAP 不是来替代数仓的,而是把数仓原本承担的“近实时分析”那一层拆回到 OLTP 附近。 真正的长周期分析、跨系统的主题域建模、机器学习的大规模数据处理,依然应该放在数仓和数据湖里。一个更合理的画像是:HTAP 负责“最近 7 天”,数仓负责“最近 2 年”,数据湖负责“所有历史”,三者分工协作。
在云栈社区的技术讨论中,我们常看到架构师纠结的一点是:HTAP 的上马时机。如果业务体量尚小,强行上马未必是明智之举;但当架构的实时性瓶颈已经阻碍业务创新时,拥抱它便成了必选项。
演进中的 HTAP:别急着押注,也别错过
回看数据库的发展,OLTP 和 OLAP 的关系一直在变:
十年前,两者完全分家,ETL 是唯一的桥;
五年前,流式管道让分家变成“准实时”,延迟压到分钟级;
三年前,HTAP 开始落地,把分家挪进数据库内部,延迟做到秒级;
现在,AI 和向量检索又来了,下一步可能是 HTAP + Vector 的三合一。
对一个架构师来说,值得记住的几点:
技术选型要跟着业务体量走。 百万 QPS 以下,MySQL 加一套 CDC 到 ClickHouse,架构最简单,成本最低。到了百万以上,尤其是业务需要实时分析时,HTAP 的复杂度换来的是显著的架构简化。到了千万 QPS,必须是行列物理分离的 HTAP,而且要接受 OLAP 部分可能还要额外做降级预案。
融合不等于免费。 行列双存的存储成本、MPP 执行器的调度复杂度、资源隔离的调参负担,都是需要计入的代价。评估一个 HTAP 方案时,除了看查询性能,还要看它在故障场景下表现如何:单节点挂了会不会拖垮全局,扩缩容时列存副本怎么重建,跨地域部署的延迟能不能承受。
最后抛一个开放性问题给你思考:如果你的系统现在跑在 MySQL 主从加 ClickHouse 数仓这条路上,业务规模正在朝百万 QPS 靠近,你会在什么时间点、基于什么信号决定迁到 HTAP?是 ETL 延迟顶不住了?是开发成本被重复建设拖垮了?还是纯粹因为老板在会上念了一次某家竞品的架构方案?答案没有标准,但思考这个问题本身,往往比选择哪家 HTAP 产品更值钱。
 发表于 2026-5-15 01:20:02
|
查看: 159|
回复: 0
发表于 2026-5-15 01:20:02
|
查看: 159|
回复: 0
