前一篇文章我们理解了实时数仓的核心取舍与架构演进。我们再来看看,一个落地的实时数仓到底由哪些技术组件构成,它们之间如何衔接,各自又扮演什么角色。
一套典型的实时数仓由四层构成:采集层、计算层、存储层、服务层。每层分工明确,通过标准接口衔接。
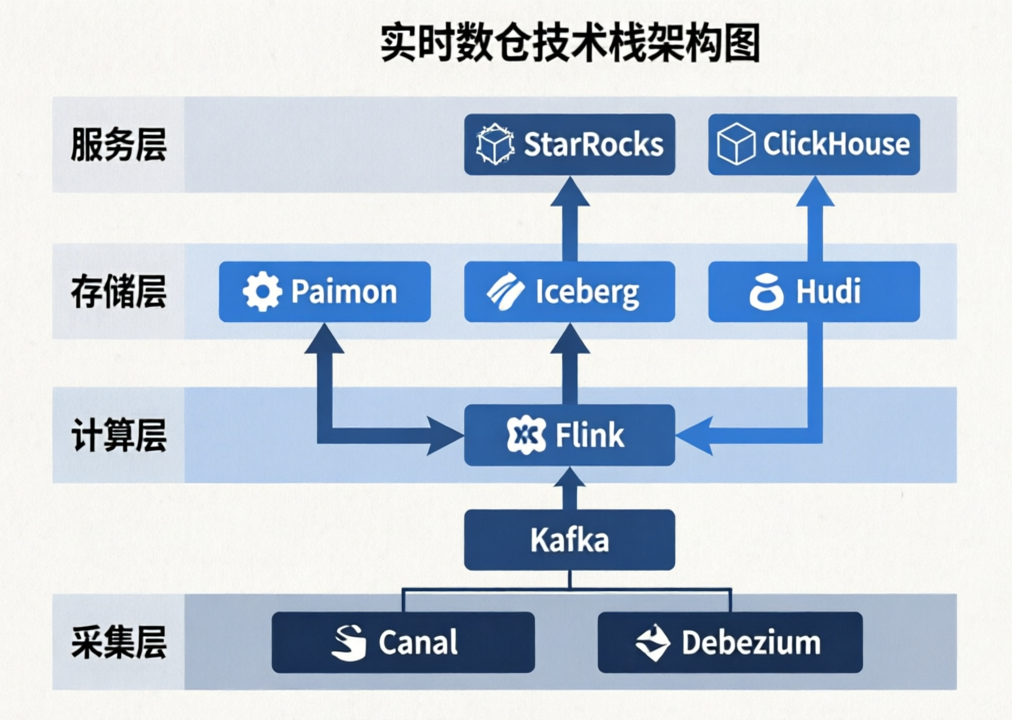
一、采集层:Canal/Debezium + Kafka
实时数仓的源头是数据变更。业务数据库的 binlog 通过 Canal 或 Debezium 实时捕获,以统一的格式(如 JSON 或 Avro)推入 Kafka。
为什么用 Canal/Debezium?
- 它们都是 CDC(Change Data Capture)工具,能够监听 MySQL、PostgreSQL 等数据库的 binlog,将数据变更实时转化为事件流。相比于轮询查询,CDC 对数据库压力小,延迟低。
- Debezium 基于 Kafka Connect,生态更广,支持更多数据库;Canal 是阿里巴巴开源,对 MySQL 支持很好,国内使用广泛。
Kafka 在这里扮演什么角色?
- 削峰填谷:业务高峰时,数据库瞬间产生大量变更,Kafka 作为缓冲区,避免下游 Flink 被冲垮。
- 解耦生产者和消费者:即使下游任务重启,Kafka 也能缓存数据,确保不丢。同时,Kafka 的多消费者机制让同一份数据可以被多个实时任务消费(比如同时用于实时大屏和实时风控)。
- 可重放的日志:Kafka 的数据可保留多天,为后续的数据回溯提供了基础。如果需要重跑历史数据,可以从 Kafka 重新消费。这也是 Kappa 架构能够成立的前提——把 Kafka 当作“可重放的日志”。
Canal/Debezium 将 binlog 解析为统一格式后,直接写入 Kafka 的指定 topic。下游的 Flink 任务通过订阅该 topic 消费数据,从而实现了采集层与计算层的解耦。
二、计算层:Flink
Flink 是实时数仓的大脑。它从 Kafka 消费数据,执行 ETL 逻辑,然后将数据写入存储层。它有四个核心能力:
1. 事件时间处理
数据到达的顺序不一定等于业务发生的顺序,如果按处理时间聚合,结果就会混乱。例如用户下单后支付成功,但支付消息可能先到,而下单消息后到。Flink 支持事件时间,可以按数据本身携带的时间戳进行窗口计算,并配合 watermark 机制处理乱序和延迟,这样便解决了实时计算中乱序的难题。
2. 状态管理
很多计算需要记住中间结果,比如过去1小时累计销售额,或者用户最近30天购买记录。这些数据存在 Flink 的状态里。状态可以有几百 GB 那么大,默认放在内存,大状态会自动溢出到 RocksDB(一种嵌入式 KV 存储)。RocksDB 将数据持久化到本地磁盘,既保证了容量,又避免了纯内存的 GC 问题。状态的存在让 Flink 能做复杂的增量计算。
3. Checkpoint 与容错
Flink 定期做 Checkpoint,把当前状态快照持久化到分布式文件系统(如 HDFS)。Checkpoint 是通过 Chandy-Lamport 分布式快照算法实现的,能够在不停止处理的情况下记录全局一致的状态。如果任务失败,重启后从最近一次 Checkpoint 恢复状态,然后从 Kafka 对应位置重新消费。这套机制保证了 Exactly‑Once:每条数据只参与一次状态更新,不丢不重。
4. 统一的 SQL 支持
Flink SQL 让大部分实时 ETL 可以用声明式语言完成,降低了开发门槛。更重要的是,同一个 SQL 逻辑,既可以跑流任务,也可以跑批任务。这意味着实时和离线可以共用一套代码,进一步保证口径一致。
Flink 从 Kafka 消费数据,处理后将结果写入存储层。写入时,它通过表格式提供的连接器(如 Flink Hudi Connector)与存储层交互,保证数据以正确格式写入。
三、存储层:Paimon/Iceberg/Hudi
这是实时数仓最大的进步。过去实时数据存 Kafka,离线数据存 Hive,两套存储口径很难对齐。现在可以用一套湖表格式统一存储。
这些表格式的共同特点是:在对象存储(如 S3、HDFS)之上,构建了一个元数据层,用元数据管理数据文件,从而赋予数据湖类似数据库的 ACID、更新、时间旅行等能力。
为什么同一份数据能同时跑实时和离线?
因为数据文件和元数据是分离的。
Flink 写入时,按照表格式的规范生成数据文件(Parquet/ORC 格式)和元数据文件(例如 Iceberg 的元数据 JSON)。数据文件存盘,元数据文件记录“当前表由哪些数据文件组成”。
Spark、Trino 等引擎读取时,先读元数据文件,拿到数据文件列表,然后直接读这些文件。整个过程没有数据拷贝,所有引擎共用同一份物理文件。这就是“不需要 ETL”的真正含义:数据在哪里,引擎就去哪里读。
Kafka 不能这样用,因为它不是文件系统,数据必须拉下来才能处理。而对象存储 + 表格式,把数据变成了“可被任意引擎访问的资产”。
UPSERT 是怎么实现的?
传统数据湖不支持更新,因为文件一旦写入就不可变。湖表格式通过增量文件和合并机制实现更新。
以 Hudi 的 MOR(Merge On Read)表为例:更新一条数据时,系统不修改原来的基础文件,而是将更新操作追加到一个新的增量日志文件。查询时,引擎会同时读基础文件和所有增量文件,合并得到最新数据。后台会定期执行压缩任务,将增量文件合并到新的基础文件中,生成新版本文件。
这种设计借鉴了 LSM‑Tree(日志结构合并树)的思想,用读时合并的开销换取了实时写入的性能。写得快,读稍慢,适合写多读少的场景。Iceberg 的 COW(Copy On Write)则是另一种取舍:更新时直接重写整个数据文件,读得快,写得慢。
时间旅行如何实现?
每次写入都会生成一个新的快照,并记录在元数据中。Iceberg 的元数据文件里有一个快照列表,每个快照包含一个指向数据文件列表的指针。
查询时可以指定快照 ID 或时间戳,比如 SELECT * FROM table FOR SYSTEM_TIME AS OF '2024-01-01 10:00:00'。引擎会读取那个时刻的元数据,得到当时的数据文件列表,从而看到历史状态。这个能力在数据回溯、错误修复、历史分析时是非常有用的。
Flink 通过各表格式工具提供的连接器写入数据,同时更新元数据。Spark、Presto 等查询引擎通过元数据服务(如 Hive Metastore)发现表结构,然后直接读取数据文件,元数据服务成为存储层与计算层之间的桥梁。
四、服务层:StarRocks/ClickHouse
实时数仓的最后一公里是查询。业务方需要从海量数据中快速获取结果,可能是点查,比如查某个订单的状态,也可能是聚合查询,比如按小时统计销售额。
StarRocks 和 ClickHouse 是当前用得最多的实时 OLAP 引擎。它们能让查询跑得快,靠的是这几手:
- 列式存储:因为数据按列排的,查的时候不用把整行都捞出来只需要读需要的列,IO一下就少了。比如sum销售额,只要读销售额那一列,性能蹭蹭的涨。而且列存天生好压缩,存数据能省不少钱。
- 向量化执行:不再一行一行处理,而是一次处理一批,这一批可能上千行,能充分利用CPU缓存和SIMD指令,计算效率翻着倍的往上涨。
- MPP架构:把一个大查询切成很多小块,分给不同的节点同时跑,最后再把结果拼起来。当数据量大了就加节点,性能跟着线性涨。
- 索引技术:稀疏索引,先定位到大概的数据块,再在块里找;布隆过滤器更快,直接告诉你这个块里肯定没有你要的数据;能把不必要的数据快速筛掉,点查的时候直接定位到数据块,不用扫全表。
但这跟存储层有什么关系呢?
存储层的湖表格式虽然能存能算,但查起来毕竟不如专门干查询的OLAP引擎快。你总不能让业务方直接对着Paimon表跑SQL吧?那得等到地老天荒。
所以服务层的OLAP引擎,得跟存储层配合着来:
- 外部表直读:StarRocks能建指向Paimon表的数据目录的外部表,查的时候动态读元数据、拉数据文件,所以不用搬数据,实时性高,但每回都扫文件,所以性能就会差一点。
- 物化视图加速:可以先建个物化视图,把常用查询的结果提前算好存下来,比如按小时聚合销售额,查的时候直接读视图结果,不用扫全表。同时,这视图可以定时刷,也能基于湖表格式的增量数据实时更新。
- 数据导入:有些场景可以把热数据直接导入OLAP引擎,查的时候更快,通过牺牲一点实时性换查询性能。
你看,存储层和服务层这么一配合,就形成了“分层存储”的格局:基础数据在湖里呆着,加速层在OLAP引擎里呆着,两者通过物化视图同步。湖的灵活性和仓的性能,就这么捏到一起了。
总结
从采集到计算,从存储到查询,四层各司其职,又通过标准接口咬合在一起。采集层把数据从业务库里捞出来;计算层把数据洗干净、算明白;存储层把数据好好存着,还能被各种引擎直接读;服务层让业务方能快地把数据查出来。每一层都在为解决“快与准”的矛盾出力,合在一起,就成了一个能打能扛的 实时数仓。 如果你对其中某个组件或架构有更深的疑问,欢迎到 云栈社区 的对应板块与其他开发者交流探讨。
 发表于 2026-4-3 02:14:26
|
查看: 131|
回复: 0
发表于 2026-4-3 02:14:26
|
查看: 131|
回复: 0
