最近笔者在 PGConf 上分享了一篇关于 YMatrix mxvector 的主题 —— How to implement high performance pluggable vectorized executor(PPT 可以下载了)。
在这次分享中,我想表达的是 PostgreSQL 的扩展能力远不止于功能上的增强,它完全能够支撑执行模型的演进。mxvector 正是沿着这个方向的一次实践:在不重写 PostgreSQL 执行器的前提下,构建一条更适合 OLAP / HTAP 场景的分析型执行路径。
传统执行器的工作原理
PostgreSQL 的执行器采用的是经典的 tuple-at-a-time 模型,可以把它理解成一种“父节点向子节点不断要下一条数据”的模式。每个节点都像一个迭代器,父节点调用子节点的 next(),一条一条地把数据拉上来。这种模型在 OLTP 场景下表现非常好,可以高效处理点查、事务处理等工作负载。在执行过程中,数据库会按顺序处理每一条数据记录,逐个执行相应的计算、过滤、投影等操作。但是,当工作负载转向 OLAP 或 HTAP 场景时,逐行处理的方式就显得不够高效了,特别是在需要处理大量数据的查询中,每一条数据的处理都会带来显著的性能损耗。
一个简单条件背后的复杂路径:c1 < 10
在处理分析型查询时,标准执行器会经历大量的操作,比如 提取数据、函数调用、数据类型转换 等步骤。这些步骤虽然在单条记录的处理过程中看似开销不大,但随着查询数据量的增加,它们的累计开销会变得相当庞大,导致查询效率大幅下降。
让我们看一个简单的例子,比如计算 c1 < 10 这样的过滤条件,标准执行器会经历如下流程:
- 扫描算子从存储中加载一行,数据以 heap tuple 这样的序列化格式存储;
- 从 heap tuple 中提取出 c1 的值,转换成 datum 类型,将其填充进函数调用上下文结构体中的参数表,并调用指向 C 函数
int4lt() 的函数指针来完成比较;
- 然后将 bool 类型的比较结果转换成 datum 泛型并返回;
- 返回到扫描算子后,其把返回值从 datum 泛型格式转换回 bool 格式,从而得知过滤条件是否满足。

可以看到,即便是一条简单的比较运算,一条 CPU 指令就能完成,然而在执行这一条指令的前后却进行了大量额外的操作。相较于真正的比较指令,这些外围操作可能占据更主要的成本,甚至达到数倍到数十倍的量级。当这样的流程被重复几百万、几千万次时,就会显著影响分析型查询的吞吐。
向量化执行器的创新
那么为什么向量化执行器可以大幅提升性能呢?之前笔者也写过一篇类似的文章《为什么需要向量化执行引擎》。
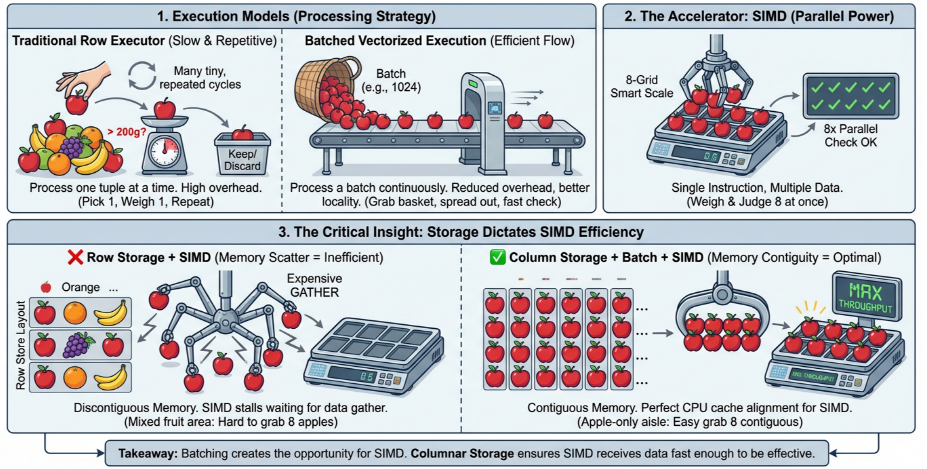
在传统执行模型下,对应的做法就像是每次拿起一个苹果,称一下重量,判断是否超过 200 克,然后放下,再拿起下一个苹果,不断重复,直到完成所有分拣任务。这个流程简单明了,当然可以完成工作,但问题也很明显:每处理一个苹果,都要重复一次“拿起、称重、判断、放下”的完整流程。如果只有几个苹果,这种方式没什么问题;但如果有几百万个苹果,这些重复动作本身就会变成巨大的开销。
于是,我们自然会想到第一步改进:能不能不要一次只处理一个,而是一次处理一批?
假设现在我们有一个篮子,一次可以拿起一篮苹果,比如 100 个。这样一来,处理流程就发生了变化:我们不再围绕单个苹果反复启动一套动作,而是把一批苹果集中起来连续处理。这样带来的好处很直接:原本每个苹果都要重复承担的“拿起 / 放下”等固定开销,现在可以被一整批苹果共同分摊。这对应到数据库中,就是批量化处理。它的核心价值不是简单地多拿了一些数据,而是把执行粒度从一条记录一次变成一批记录一次,从而减少大量重复的函数调用、状态切换和数据转换开销。
但批量化之后,我们还可以继续追问:既然苹果已经是一批一批地来了,能不能一次称多个苹果,而不是仍然一个一个称?
这就引出了第二步改进:SIMD。
假设现在我们拥有一台特殊的秤,它一次可以同时称 8 个苹果的重量。这样我们就不需要对这 8 个苹果分别称 8 次,而是一次称重,直接得到 8 个结果。这正是 SIMD 想表达的核心思想 —— 一条指令,同时处理多个数据。对应到数据库中,如果我们已经拿到了一批同类型的数据,比如一批 int32 数值,那么 CPU 就有机会通过 SIMD 指令一次处理多个元素,而不是一个一个做标量计算。
不过,到这里还有一个关键问题:批量处理和 SIMD 并不会凭空发生,它们需要数据本身足够规整。
这就引出了第三个关键点:存储布局。
在图的左下角可以看到,如果水果是杂乱无章存放的,比如苹果、橙子、香蕉、苹果、橙子……葡萄混在一起,那么即使我们有一台可以一次称 8 个苹果的秤,也很难直接发挥作用。因为在称重之前,我们还得先从一堆混杂水果里把苹果一个个挑出来,这就类似数据库中的行存布局:一行中包含多个列,查询如果只关心某一列,也往往需要先从整行数据中把目标列提取出来,这个过程会带来额外的数据访问和解码成本。
相反,如果所有苹果都整齐地放在一起,我们就可以很自然地一次拿起一批苹果,并直接交给那台秤处理。对应到数据库中,这就是列存的重要性。在列式存储中,同一列的数据连续存放。这样有几个好处:
- 查询只需要读取真正关心的列,减少不必要的 I/O;
- 同类型数据连续存放,更容易获得较好的压缩效果;
- 连续的数据更有利于 CPU cache;
- 数据天然接近数组形式,更适合批量处理和 SIMD 计算。
所以,列存、批量化和 SIMD 并不是三个孤立的概念,而是一条逐步增强的链路:列存让数据更连续,批量化让执行更规整,SIMD 让 CPU 一次处理多个值。换句话说,批量化创造了使用 SIMD 的机会,而列存让 SIMD 更容易真正发挥效果。
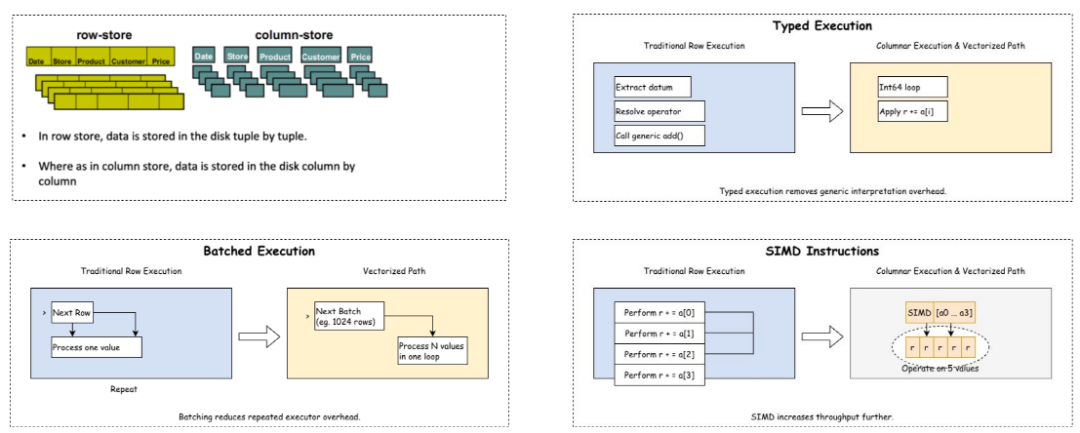
现在,让我们小结一下:向量化执行器的核心思路,是将数据处理单元从“逐行处理”转换为“批量处理”,并尽可能让数据访问和计算过程都变得更加连续、规整、CPU 友好。具体来说,它主要依赖三个关键能力:
- 列存储:数据按列而不是按行存储。查询时可以只读取需要的列,减少不必要的数据加载,同时提升压缩率和缓存友好性。
- 批量化处理:一次处理一批数据,而不是一条记录一条记录处理。这样可以减少重复的函数调用、状态切换和数据转换开销。
- SIMD 加速:当数据已经连续、同类型、批量化之后,CPU 就可以使用 SIMD 指令一次处理多个数据单元,进一步提升计算吞吐。
这些改变不仅减少了每条记录上的重复处理开销,也让数据访问和计算路径更加适合现代 CPU,从而提升分析型查询的整体执行效率。
那么理解了向量化执行的价值之后,下一个问题是如何实现呢?更多关于数据库引擎的高性能实践,欢迎访问云栈社区交流。
 发表于 2026-5-1 17:48:04
|
查看: 78|
回复: 0
发表于 2026-5-1 17:48:04
|
查看: 78|
回复: 0
