目录
- 引言:Memcached的核心价值与应用场景
- 基础概念:Memcached的核心特性与工作原理
- 数据存储与分布式架构揭秘
- Linux与Windows环境安装配置详解
- Python与Java客户端使用指南与避坑
- 高级特性:持久化、集群与安全设置
- 性能优化:内存管理、并发与命中率提升
- 常见问题与解决方案:穿透、击穿与雪崩
- Memcached与Redis的对比与选型
- 实际案例分析:电商、社交与游戏场景应用
- 技术演进与未来趋势
- 学习路径与资源推荐
1. 引言:Memcached的核心价值与应用场景
在当今对应用响应速度要求极高的时代,数据库往往成为性能瓶颈。Memcached作为一个分布式内存缓存系统,通过将频繁访问的数据存储在内存中,能够显著降低数据库负载,提升应用响应速度。
Memcached最初由Danga Interactive团队为LiveJournal开发,现已广泛应用于Facebook、Twitter、YouTube等大型互联网架构中。它充当数据库的“前置缓存层”,使数据读取操作无需每次都访问后端数据库。
1.1 Memcached的发展历程
- 2003年:诞生于LiveJournal,旨在解决动态内容加载缓慢的问题。
- 2007年:在Facebook得到大规模部署,支撑了亿级用户访问。
- 2010年:1.4版本支持64位系统,突破了单节点2GB的内存限制。
- 2024年:最新版本1.6.33发布,专注于代理模式性能与稳定性的提升。
1.2 Memcached的核心优势
- 高性能:纯内存操作,读写速度可达数十万QPS,远高于传统数据库。
- 分布式友好:通过客户端一致性哈希算法,轻松实现集群横向扩展。
- 设计简洁:采用键值对存储和简单的文本协议,学习与集成成本低。
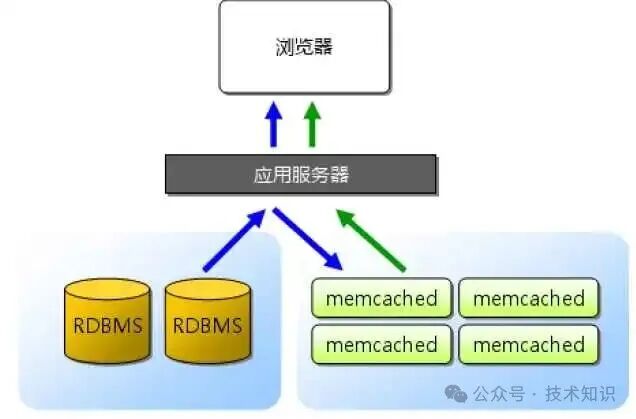 图1:Memcached作为数据库与应用服务器之间的缓存层,有效降低数据库压力
图1:Memcached作为数据库与应用服务器之间的缓存层,有效降低数据库压力
2. 基础概念:Memcached的核心特性与工作原理
2.1 什么是Memcached?
Memcached是一个开源、高性能、分布式的内存对象缓存系统。其本质是一个存储在内存中的大型哈希表,以键值对(Key-Value)形式存储数据。它主要用于缓存数据库查询结果、会话数据等,以减少对后端数据源的直接访问。
2.2 核心特性
- 无状态设计:服务器节点间不直接通信,数据分布逻辑由客户端负责,提升了系统的可扩展性。
- Slab内存管理:通过预分配固定大小的内存块(Chunk)来管理内存,有效减少内存碎片。
- LRU淘汰策略:当内存耗尽时,自动淘汰“最近最少使用”的数据,保留热点数据。
- 多语言支持:为Python、Java、PHP、Go等主流编程语言提供了成熟的客户端库。
2.3 典型应用场景
- 数据库查询缓存:缓存商品信息、用户资料等高频读取数据,可大幅降低数据库查询压力。
- 会话存储:在分布式系统中共享用户Session,替代数据库存储,提升访问速度。
- 计数器:利用原子递增/递减操作,实现点赞数、浏览量等实时计数功能。
- 静态资源元信息缓存:缓存CSS、JS等静态文件的元数据,减轻CDN回源压力。
3. 数据存储与分布式架构揭秘
3.1 数据存储:Slab Allocation机制
为了优化内存使用并避免碎片,Memcached采用了Slab Allocation机制:
- 内存分块:将内存划分为多个Slab Class(内存块组),每个Slab Class包含多个固定大小的Chunk(如88B、112B)。
- 按需分配:根据待存储数据的大小,选择最合适的Slab Class进行存储,以提高内存利用率。
- Page复用:每个Slab Class从操作系统申请1MB的Page(内存页),并切割为多个Chunk。当Page用尽时再申请新的Page。
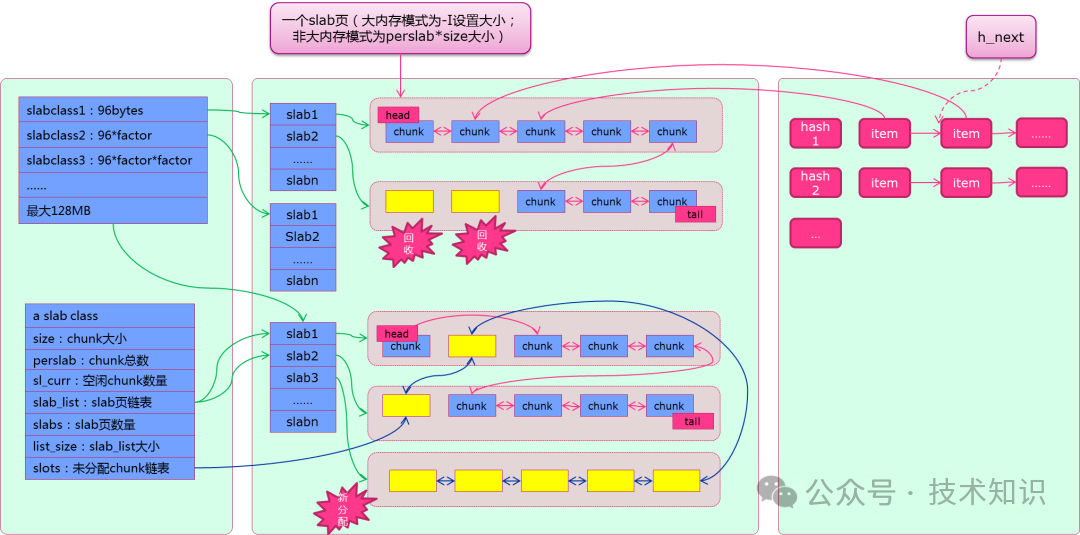 图2:Slab Class、Page与Chunk的关系示意图
图2:Slab Class、Page与Chunk的关系示意图
3.2 缓存策略:LRU与过期时间
- LRU(最近最少使用):系统内部维护LRU链表来追踪数据访问顺序,内存满时优先淘汰链表尾部的数据。
- 惰性删除:数据过期后并不会被立即清除,而是在下次被访问时检查并删除,减少了主动扫描的开销。
- 过期时间(TTL):可以在存储数据时设置一个过期时间,超时后数据将不可用。
3.3 分布式架构:一致性哈希
Memcached服务器本身不支持集群,但其客户端通过一致性哈希算法实现了分布式存储:
- 构建哈希环:将服务器节点的标识(如IP)通过哈希函数映射到一个32位的圆环上。
- 数据映射:将数据的Key同样哈希到圆环上,然后顺时针找到第一个服务器节点,将数据存储于该节点。
- 容错与扩展:当某个节点宕机或新增节点时,仅影响环上相邻部分的数据,大部分数据无需迁移。
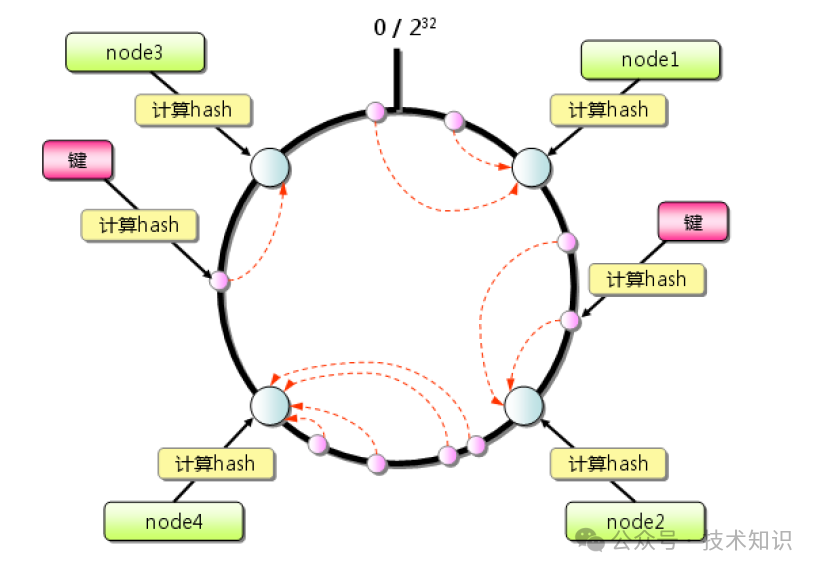 图3:一致性哈希环示意图,数据和节点均映射到环上
图3:一致性哈希环示意图,数据和节点均映射到环上
4. Linux与Windows环境安装配置详解
4.1 Linux环境安装(以CentOS为例)
步骤1:安装依赖库libevent
yum install -y libevent libevent-devel # CentOS/RHEL
# Ubuntu/Debian: apt-get install libevent-dev
步骤2:下载并编译安装Memcached
wget http://memcached.org/files/memcached-1.6.33.tar.gz
tar -zxvf memcached-1.6.33.tar.gz && cd memcached-1.6.33
./configure --prefix=/usr/local/memcached
make && make install
步骤3:启动与验证
# 启动Memcached服务
/usr/local/memcached/bin/memcached -d -m 1024 -p 11211 -u root -c 20000
# 验证服务状态
ps -ef | grep memcached
netstat -tuln | grep 11211
4.2 Windows环境安装
Windows用户可获取预编译的二进制包进行安装。
步骤1:安装为系统服务
cd C:\memcached
memcached.exe -d install
步骤2:启动服务并修改配置
memcached.exe -d start
# 通过修改注册表调整启动参数(如内存大小)
步骤3:验证安装
通过Telnet连接11211端口,并执行stats命令查看状态。
4.3 核心配置参数调优
| 参数 |
作用 |
默认值 |
推荐配置 |
-m |
最大内存(MB) |
64 |
根据业务需求,如1024~4096 |
-p |
监听端口 |
11211 |
建议修改为非默认端口以增强安全性 |
-c |
最大并发连接数 |
1024 |
高并发场景可设为20000 |
-t |
工作线程数 |
4 |
建议设为CPU核心数的1-2倍 |
-f |
Slab增长因子 |
1.25 |
根据数据大小分布调整(1.1或1.5) |
-I |
最大item大小 |
1MB |
存储大对象时可设为10MB (-I 10m) |
安全提示:生产环境中应使用专用用户启动Memcached(如-u memcache),并通过防火墙限制访问来源IP。
5. Python与Java客户端使用指南与避坑
5.1 Python客户端 (pymemcache)
推荐使用pymemcache库,性能优于旧版的python-memcached。
安装与基础操作
pip install pymemcache
from pymemcache.client import base
# 连接Memcached服务器
client = base.Client(('127.0.0.1', 11211))
# 设置键值对(expire单位:秒)
client.set('user:1001', '{"name":"张三","age":25}', expire=3600)
# 获取值
user = client.get('user:1001')
print(user.decode('utf-8')) # 输出: {"name":"张三","age":25}
# 批量操作(提升效率)
client.set_many({'product:100': 'iPhone 15', 'product:101': '华为Mate 60'})
products = client.get_many(['product:100', 'product:101'])
# 原子计数器操作
client.set('view:1001', 100)
client.incr('view:1001', 5) # 增加5
client.decr('view:1001', 3) # 减少3
避坑指南:
- 数据序列化:Memcached仅存储字节流,复杂对象需先序列化(如使用
json.dumps())。
- Key规范:Key长度建议不超过250字节,采用“业务:ID”的命名格式便于管理。
- 连接管理:在高并发场景下,应使用连接池(如
PooledClient)以避免频繁创建连接的开销。更多关于Python数据处理和客户端库的使用技巧,可以参考我们的 Python 技术板块。
5.2 Java客户端 (XMemcached)
推荐使用基于NIO的XMemcached客户端以获得更高性能。
Maven依赖与基础操作
<dependency>
<groupId>com.googlecode.xmemcached</groupId>
<artifactId>xmemcached</artifactId>
<version>2.4.7</version>
</dependency>
import net.rubyeye.xmemcached.MemcachedClient;
import net.rubyeye.xmemcached.XMemcachedClientBuilder;
import java.util.concurrent.TimeoutException;
public class MemcachedDemo {
public static void main(String[] args) throws Exception {
XMemcachedClientBuilder builder = new XMemcachedClientBuilder("127.0.0.1:11211");
MemcachedClient client = builder.build();
// 设置数据(过期时间3600秒)
client.set("order:5001", 3600, "iPhone 15 256G 黑色");
// 获取数据
String order = client.get("order:5001");
System.out.println(order);
// 原子递增操作
client.set("counter", 0, 100);
client.incr("counter", 10);
System.out.println(client.get("counter"));
client.shutdown();
}
}
6. 高级特性:持久化、集群与安全设置
6.1 持久化方案
Memcached默认将数据存储在内存中,重启后数据会丢失。可通过以下方案实现持久化:
- Memcachedb:一个基于Berkeley DB的第三方分支,支持数据持久化和主从复制。
- 客户端双写:应用程序在写入数据时,同时写入Memcached和持久化数据库(如MySQL)。读取时优先访问缓存。
6.2 集群部署模式
- 普通客户端分片集群:多个Memcached节点独立,客户端通过一致性哈希决定数据存储节点。架构简单,但不支持故障自动转移。
- Magent代理集群:通过Magent代理实现主从复制和数据分片。主节点处理写操作,数据同步到从节点,故障时可切换。更多关于分布式系统中间件的集群部署方案,可以查阅 数据库/中间件 相关专题。
6.3 安全增强设置
Memcached默认无认证机制,需主动加强安全防护:
- 网络层隔离:使用防火墙(如iptables)限制只有特定的应用服务器IP可以访问Memcached端口。
- SASL认证:编译时启用SASL支持,为Memcached服务设置用户名和密码。
- 传输加密:使用stunnel等工具对客户端与Memcached之间的TCP连接进行加密。
7. 性能优化:内存管理、并发与命中率提升
7.1 内存管理优化
- 调整Slab增长因子(
-f):若存储的数据大小相对均匀(如用户ID),可设置较小的增长因子(如-f 1.1)以减少内存浪费。若数据大小差异大,可适当调大。
- 控制Item大小(
-I):避免存储单个过大的对象(如超过1MB),可考虑拆分或压缩后再存储。
- 谨慎使用
-M参数:该参数禁用LRU,内存满时写入会报错。仅适用于不允许数据丢失且监控完善的场景。
7.2 并发性能调优
- 工作线程数(
-t):设置为CPU物理核心数的1-2倍,过多线程会增加上下文切换开销。
- 连接队列(
-b):在高并发访问下,适当增大backlog连接队列长度(如-b 4096),防止新连接被拒绝。
- 大页内存支持(
-L):在Linux系统中启用大页内存,可以减少TLB Miss,提升内存访问效率。
7.3 提升缓存命中率
缓存命中率是衡量缓存有效性的关键指标,目标应高于90%。
- 热点数据永不过期:对极少变更且访问频繁的数据(如配置信息)设置
expire=0。
- 细化缓存粒度:避免缓存大而全的结果集,按需拆分为更细粒度的Key。
- 缓存预热:在系统启动或业务高峰前,主动将热点数据加载到缓存中。
- 防止缓存穿透:对查询不到的Key,也缓存一个空值或特殊标记,并设置较短过期时间。
8. 常见问题与解决方案:穿透、击穿与雪崩
8.1 缓存穿透
问题:查询一个一定不存在的数据(如不存在的用户ID),请求会穿过缓存直接访问数据库,可能被恶意利用攻击数据库。
解决方案:
- 缓存空值:即使数据库未命中,也将该Key对应一个空值或特殊标记(如
NULL)存入缓存,并设置一个较短的过期时间(如30秒)。
- 布隆过滤器:在缓存之前加一层布隆过滤器,快速判断某个Key是否可能存在,不存在则直接返回。
8.2 缓存击穿
问题:某个热点Key在过期瞬间,有大量并发请求同时涌入,导致所有请求都去访问数据库,造成数据库瞬时压力过大。
解决方案:
- 互斥锁:当缓存未命中时,先尝试获取一个分布式锁(如使用Memcached的
add命令设置一个锁Key),只有拿到锁的线程去查询数据库并回填缓存,其他线程等待或重试。
- 永不过期与异步更新:对极热点的Key不设置过期时间,而是通过后台任务异步更新其数据。
8.3 缓存雪崩
问题:大量缓存Key在同一时间点过期,或缓存服务宕机,导致所有请求涌向数据库,引发连锁故障。
解决方案:
- 随机化过期时间:在设置缓存过期时间时,增加一个随机值(例如基础3600秒 ± 600秒),避免集中失效。
- 集群与高可用:部署Memcached集群,即使个别节点宕机,整体服务仍然可用。
- 服务降级与熔断:当检测到数据库压力过大时,暂时返回降级内容(如默认值、旧缓存),使用Hystrix等工具保护后端服务。
9. Memcached与Redis的对比与选型
| 对比项 |
Memcached |
Redis |
| 数据结构 |
仅支持简单的Key-Value(字符串) |
支持String, List, Hash, Set, Sorted Set等 |
| 持久化 |
不支持(需借助第三方方案) |
支持RDB快照和AOF日志两种持久化 |
| 分布式 |
依赖客户端实现(一致性哈希) |
原生支持Redis Cluster集群模式 |
| 线程模型 |
多线程 |
单线程(6.0后支持多线程I/O) |
| 性能特点 |
纯内存、多线程,小数据(<100KB)读写QPS极高 |
单线程模型下,大数据操作和复杂命令性能更优 |
| 高级功能 |
功能聚焦于缓存 |
支持事务、Pub/Sub、Lua脚本、地理空间等 |
| 主要场景 |
纯缓存场景:会话、简单计数器、高频读数据 |
缓存+数据存储:排行榜、消息队列、社交关系、复杂业务数据 |
选型建议:
- 选择Memcached:业务场景单纯,只需要高性能的键值缓存,且数据可以接受丢失。例如,存储用户Session、临时性的API响应缓存。
- 选择Redis:需要丰富的数据结构、数据持久化、内置集群支持或利用其高级功能(如发布订阅)。例如,实现实时排行榜、延迟队列、社交Feed流。
- 混合架构:在超大型系统中,可以同时使用两者:用Memcached缓存最热、最简小的数据;用Redis处理有状态的、结构复杂的业务数据。
10. 实际案例分析:电商、社交与游戏场景应用
10.1 电商秒杀场景
挑战:瞬时百万级并发访问,数据库无法直接承受库存查询与扣减压力。
Memcached方案:
- 库存预热:活动开始前,将秒杀商品库存数量加载到Memcached中。
- 原子扣减:用户下单时,使用
decr命令原子性地减少Memcached中的库存计数。
- 异步同步:扣减成功后,订单服务异步将库存变更写入数据库。
效果:将绝大部分库存判断压力转移至内存,数据库仅承担最终一致性写入,系统抗并发能力得到质的提升。
10.2 社交平台会话共享
挑战:分布式架构下,用户登录状态需要在多台应用服务器间共享。
Memcached方案:
- 集中存储Session:用户登录后,将其Session信息(JSON格式)存入Memcached,Key为Session ID。
- 客户端存储ID:仅将Session ID通过Cookie返回给客户端。
- 状态读取:任何应用服务器收到请求后,都通过Memcached中的Session ID读取用户状态。
效果:实现了无状态的应用服务器,便于水平扩展,同时会话读取延迟极低。
10.3 游戏实时数据缓存
挑战:MOBA游戏中,玩家金币、击杀数、实时排名等数据需要高频、低延迟地更新与读取。
Memcached方案:
- 数据分片:按玩家ID范围将数据哈希到不同的Memcached节点。
- 批量异步落盘:游戏逻辑中直接读写Memcached,保证实时性。每隔一定时间(如5分钟),将变动的数据批量写入持久化数据库。
- 防丢失机制:对关键数据(如充值记录)采用双写策略,同时写入Memcached和消息队列,确保可追溯。
效果:满足了游戏对数据实时性的苛刻要求,同时通过异步化保护了后端数据库,更多关于高并发场景下的架构设计实践,可以参考 后端&架构 相关内容。支持了大规模玩家同时在线的数据交互。
11. 技术演进与未来趋势
11.1 最新版本特性(1.6.33)
2024年底发布的1.6.33版本主要聚焦于稳定性和代理模式的增强:
- 代理模式优化:集成了
routelib库,使代理配置和自定义路由逻辑更加灵活。
- 性能与稳定性修复:解决了此前版本在代理模式下的一些内存泄漏和GC问题,提升了吞吐量。
- 编译兼容性:改善了对新版本操作系统和编译器的支持。
11.2 未来发展方向
- 云原生集成:更好地适配Kubernetes环境,可能出现官方的Operator或Helm Chart,简化在容器云中的部署和管理。
- 安全性增强:原生集成TLS加密传输和更细粒度的访问控制(ACL),降低对第三方安全工具的依赖。
- 功能适度扩展:在保持内核简洁的前提下,可能会引入少量最常用的数据结构(如简单的List),但核心定位仍是高性能缓存。
- 智能化运维:结合机器学习算法,自动预测数据访问模式,动态调整Slab分配或数据分布策略,实现智能化的缓存优化。
12. 学习路径与资源推荐
12.1 循序渐进的学习路径
- 第一阶段(1个月):掌握基础
- 理解Memcached的定位、核心概念(Slab, LRU, 一致性哈希)。
- 完成在Linux/Windows上的安装与基本配置。
- 熟练使用一种语言的客户端进行CRUD操作。
- 第二阶段(1个月):深入实战
- 理解内存管理、网络模型的内部原理。
- 动手搭建集群环境,模拟并解决缓存穿透、击穿、雪崩问题。
- 学习使用监控工具(如
memcached-tool)观察缓存状态。
- 第三阶段(1个月):源码与高阶调优
- 阅读Memcached核心模块的C语言源码(如
slabs.c, memcached.c)。
- 根据实际业务压力,进行针对性的性能参数调优。
- 探索Memcached在复杂业务架构中的最佳实践。
12.2 推荐资源
- 官方资源:Memcached Wiki 是最权威的文档和知识库。
- 经典书籍:《高性能MySQL》书中对缓存策略有深入论述;《Memcached完全指南》则是系统学习的专著。
- 实用工具:
memcached-tool:Perl脚本,用于查看Slab使用情况、统计数据等。memslap (libmemcached包自带):基准测试工具,用于压测Memcached性能。
- 技术社区:在Stack Overflow上搜索
memcached标签,或参与GitHub项目的Issues讨论,是解决具体问题和了解前沿动态的好途径。
 发表于 2025-12-8 01:21:33
|
查看: 212|
回复: 0
发表于 2025-12-8 01:21:33
|
查看: 212|
回复: 0
