相信很多开发者都能感同身受一个现象:用户规模或者营收规模没怎么增加,但团队要做的事情却越来越多。产品侧要么在不断拓展边界,往一个应用里塞进更多功能以吸引用户;要么在持续优化现有交互和体验,试图稳固基本盘。
对应到开发侧,就是源源不断的新需求。一个需求效果不好?那就再做两个。这自然加剧了开发团队的压力。于是,团队负责人往往会提出要“提升效率”。
但需求的增多,就必须伴随人力的扩张吗?软件行业“近乎零成本的可复用性”似乎给了我们否定的答案。理论上,前期沉淀的通用能力应该能让后续开发事半功倍,效率越来越高。
很多人理想中的软件开发团队,其开发成本与功能数量至少应保持线性关系。如果再引入一些重大技术创新,这个增长曲线还应该更平缓。
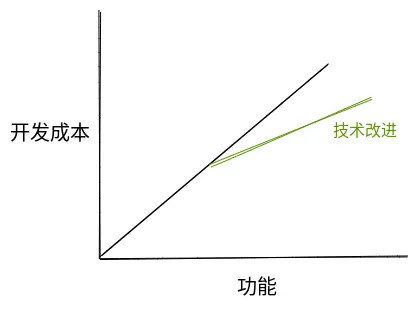
如果团队拥有良好的架构设计和合理的模块划分,考虑到复用带来的成本降低,这条曲线甚至应该更理想。
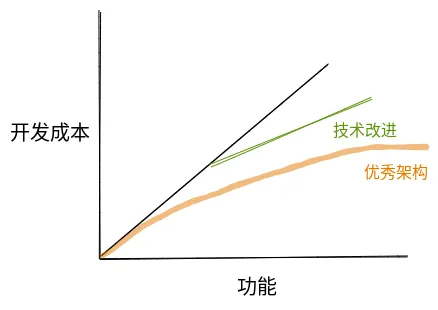
然而,现实往往更为骨感。如果你去问问一线开发者,他们感受到的曲线可能是这样的:
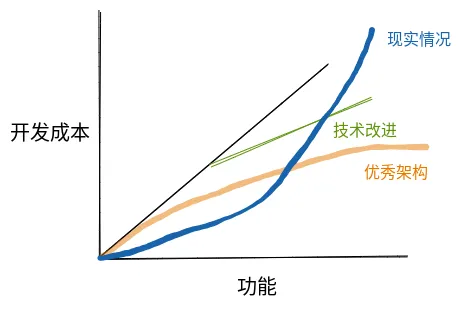
随着系统功能越来越多,实现每个新功能不是变得更简单,而是更困难。复用?常常只是一种奢望。别说理想中对数级的平缓曲线了,就连维持线性的需求吞吐率都变得异常艰难。
过去20年敏捷开发所追求的终极目标之一,也不过是维持那条黑色的线性曲线——每个迭代完成固定数量的需求。但在很多团队的实际操作中,这种“中华田园式敏捷开发”往往是在没有进行充分知识沉淀和重构的情况下,单纯靠堆人力维持着一种脆弱的平衡。
那么,为什么现实世界中的功能-成本曲线会是指数型,而非理想中的线性呢?这触及了软件模型 “根本复杂性(Essential Complexity)” 的核心。
软件开发的提效困境:没有银弹
过去一年,许多公司大力推动“降本增效”。对开发者而言,“降本”相对直观:精细化使用云资源、关注账单、在技术评审中加入成本考量以过滤低ROI需求。
但“降本”很快会遇到天花板。更大的潜力在于“增效”,而谈到软件开发增效,很多人首先想到的是工程效能(EP)——利用更好的工具来提升编码、构建和协作效率。从极速的代码托管平台到高度自动化的CI/CD流水线,从好用的RPC框架到先进的可观测系统,目标都是“让程序员专注于业务开发”。
但这里存在一个关键问题:在软件开发的总工作量中,业务开发(解决根本复杂性)和非业务开发(解决附属复杂性)究竟哪个占比更高?
图灵奖得主Fred Brooks在《没有银弹》一文中将软件工作分为两类:
- 根本复杂性 (Essential Complexity):软件要实现的功能本身内在具有的、不可避免的复杂性。
- 附属复杂性 (Accidental Complexity):由于软硬件限制、沟通不畅等工程原因额外引入的复杂性。
EP和各种中台工具,主要是在努力消除附属复杂性,让我们能更专注于根本复杂性。但如果根本复杂性占据了工作量的八成,而我们只在消除那两成的附属复杂性上发力,是否有些“隔靴搔痒”?
假设我们有一根魔法棒,能立刻拥有宇宙顶级的基础设施和工具:毫秒级克隆的代码仓库、智能的流水线、顶级的观测和发布系统。然后呢?我们终于可以心无旁骛地开发业务代码了。
但业务代码本身该如何开发?不合理的业务建模、仓促上线的需求、糟糕的接口设计、各种隐式的耦合……即便建立在最完美的基础设施之上,业务系统在一段时间后仍可能变成一座“屎山”。代码难以阅读,改动牵一发而动全身,一个小功能要修改无数个地方。

于是,功能-成本曲线会变成这样:
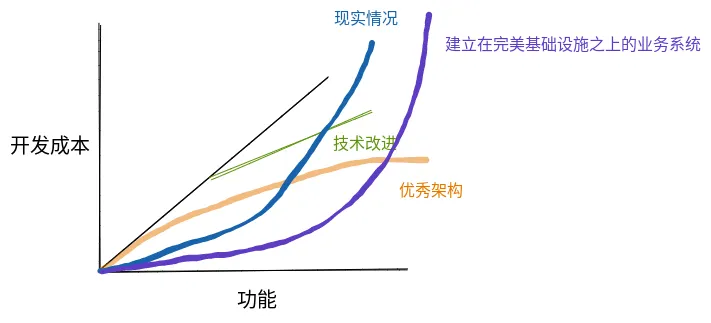
所以,只靠工具提效远远不够,我们必须正视业务系统本身的复杂性。真正为用户创造价值、为团队带来收入的,恰恰是这段业务代码。很多人低估了业务开发的复杂性,认为无非是“增删改查”,这反而加速了“屎山”的形成。
业务系统复杂的根本原因
结合实践经验,抛开人的因素(假设大家都是理智且有追求的),我认为导致业务系统复杂的根本原因有两个:功能之间隐秘增加的耦合,以及不可避免的代码腐化。
3.1 功能之间隐蔽增加的耦合
项目启动时,大家都怀揣着实践“整洁架构”的理想。但随着时间推移,代码总会变得越来越难改,明明修改功能A,却不得不担心功能B、C、D是否会受影响。
根源在于耦合。很多人只记得“低耦合”,却忘了前提是“高内聚”。在高内聚的边界内,模块间本就是强耦合的。这种由根本复杂性带来的耦合,很多时候难以通过架构设计彻底消除。
举例一:“名片系统”的长尾耦合
假设一个社区App有资讯、社区动态、评论区等独立模块,由不同小组负责。现在产品提出做“名片系统”,让用户可以在头像旁展示“认证作者”、“VIP等级”等标签。
初看很简单:一个配置页面 + 在各个展示头像的地方读取配置。但细想之下,耦合无处不在:
- 配置侧耦合:配置页面需要从毫不相干的“成就系统”、“会员系统”、“认证系统”拉取数据。这些系统在设计之初并未考虑彼此关联。
- 展示侧耦合:资讯流、动态列表、评论区、详情页的头像展示样式各异,空间有限。现在都要额外考虑名片的展示逻辑和优先级。这个逻辑是放在名片系统统一处理,还是各个场景自己决定?无论哪种选择,都引入了新的耦合。
更麻烦的是,这是一个长尾需求。后续只要涉及“用户身份”或“头像展示”的新功能,都需要考虑与名片系统的结合。如果新功能的开发者不知道这段历史,就很容易遗漏,导致上线后的紧急修复。

举例二:“分享到微信”带来的工作量倍增
为了拉新,希望将App内容分享到微信。这带来了天然的耦合:
- App是原生开发(iOS/Android),微信内只能打开H5页面。同一个功能需要开发两套。
- H5页面无登录态,而后台很多接口逻辑强依赖登录态(如记录浏览历史、增加浏览量、判断关注状态)。必须为H5定制一套无登录态的接口,这往往意味着功能阉割或逻辑重构。
于是,一个简单的分享功能,让后续所有需要分享的页面,其开发工作量几乎都变成了原来的两倍。
这些耦合并非糟糕的架构设计或代码所致,而是产品功能叠加后,由根本复杂性带来的天然关联。到项目后期,每个新变更都可能需要修改N个耦合点。软件工程中的优化手段,往往只是将复杂性从一个地方转移到另一个地方,而不会消失。
3.2 不可避免的代码腐化
除了耦合,代码腐化是另一个让系统复杂化的核心原因。许多开发者的心路历程是这样的:
- 项目初期:雄心勃勃,决心打造整洁架构的典范。
- 开发中期:排期紧张,需求反复,Code Review流于形式,在“业务先行”的压力下对代码质量妥协。
- 项目后期:系统逐渐变成自己曾经讨厌的样子,并将希望寄托于“下一次”。

腐化不仅源于低质量的代码,更源于系统架构的腐化。而在“小步快跑、快速迭代”的开发模式下,架构设计天然是短视和有局限性的。
我们比较两种开发模式:
- 瀑布流开发:拥有完整的全局视图后再进行架构设计,但周期过长,难以适应市场变化。
- 敏捷开发:小步快跑,先交付核心价值,再根据反馈迭代。这种方式能快速响应市场,但设计者每次只能看到宏大蓝图的一角。
如今互联网公司普遍采用的“中华田园敏捷开发”,就是后者的变体。在这种模式下,技术方案设计所依据的信息只是产品全貌的碎片。仅凭这些碎片信息,即使最优秀的架构师,其设计也必然存在局限性,只能较好地适应“当下”的需求。
举例:无法复用的“通用”权限系统
团队为后台管理系统设计了一个基于RBAC模型的“通用”权限模块,并加入了多租户(appid)支持以便复用。
两周后,一个新需求需要类似的权限管理,但略有不同:它类似于游戏帮派系统,角色(如帮主、长老、堂主)之间存在上下级管理关系。
最初的RBAC模型并未考虑角色间的关联,因此无法直接复用。如果最初就为这种未知的扩展性投入大量设计,又可能陷入“过度设计”的陷阱。最终,新业务只能重写一套。
这个例子揭示了一个常见陷阱:看似相似的需求,其根本复杂性可能不同,对应的软件建模也应有区别。盲目追求复用,在函数后面不断添加参数,往往适得其反。
开源领域有两个有趣的比喻:
- Free as Beer(像啤酒一样免费):拿来即用,无需额外负担。
- Free as Puppy(像小狗一样免费):获得时是免费的,但后续需要持续的照料(铲屎、喂养、看病),负担可能大于快乐。
那些未经深思熟虑的“通用系统”,对使用者来说就是“Free as Puppy”。用起来磕磕绊绊,改起来困难重重,最终大家宁愿自己“再造个轮子”。
总结
由于根本复杂性的存在,软件开发领域“没有银弹”。而为了快速响应市场所采用的迭代开发模式,又带来了不可避免的代码腐化和架构局限。
程序员其实并不害怕根本复杂性,状态好时“日码千行”也不在话下。真正让人头疼的是代码腐化以及伴随的知识丢失。很多设计决策和代码逻辑是“隐性知识”,只存在于最初开发者的脑中,随着人员变动,这些知识便永久丢失了。
因此,应对复杂性的核心在于 “代码防腐” 与 “知识沉淀” 。但这恰恰是费力不讨好、个人收益不直接的事情。事前的代码规范(EPC)只能提升质量下限,而结构性的腐化,只能通过“重构”来解决。
重构本质上是“事后诸葛亮”,是在获得更多信息后,对早期设计的局限性进行修正和优化。但重构的收益难以量化,如何向产品和管理层争取时间,是一个永恒的难题。
技术债务就像金融债务,并非总是有害的,有时甚至是抓住时代红利的手段。但债务终究要偿还。何时还、还多少、怎么还,是每个技术团队需要持续思考的平衡艺术。
关于文档沉淀、代码防腐的具体实践,以及如何更有效地管理业务系统的复杂性,欢迎在云栈社区与广大开发者继续交流探讨。技术的道路没有终点,我们都在不断的反思与实践中前行。
 发表于 2026-3-7 16:59:51
|
查看: 230|
回复: 0
发表于 2026-3-7 16:59:51
|
查看: 230|
回复: 0
