
软件开发圈正在发生一件事:人工智能代码审查工具正在被大规模引入团队工作流程。
问题不在于这项技术好不好用,而在于——它究竟在解决谁的问题?
它在做什么
AI代码审查,本质上是用机器学习模型替代人工,在代码提交时自动扫描几类问题:
- 潜在的程序漏洞(Bug)
- 安全漏洞
- 性能浪费
- 代码风格不统一
- 架构设计缺陷
与传统静态扫描工具不同,现在的AI工具能理解代码上下文,不只是逐行对规则,还能建议怎么改、甚至直接生成修复代码。
准确率大概在70%到90%之间——这个数字值得单独记住,因为剩下的10%到30%,依然需要人来兜底。
数字背后的扩张速度
几组数字可以说明这场扩张有多快。
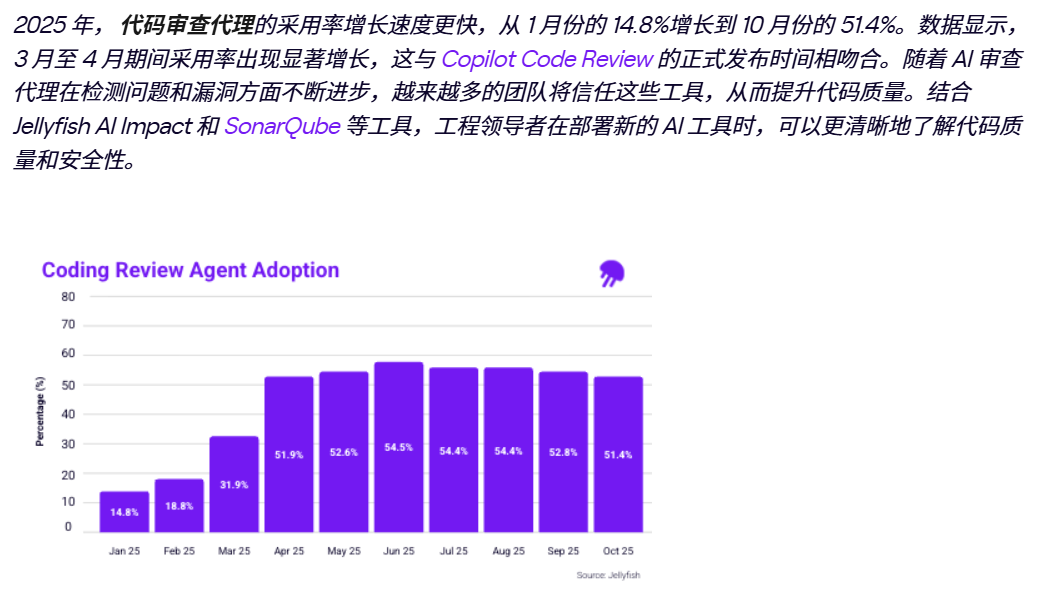
2025年,AI代码审查代理的采用率从1月的14.8%增长到10月的51.4%,其中3月到4月之间出现了一次明显跃升——恰好对应GitHub Copilot代码审查功能全面开放的时间节点。
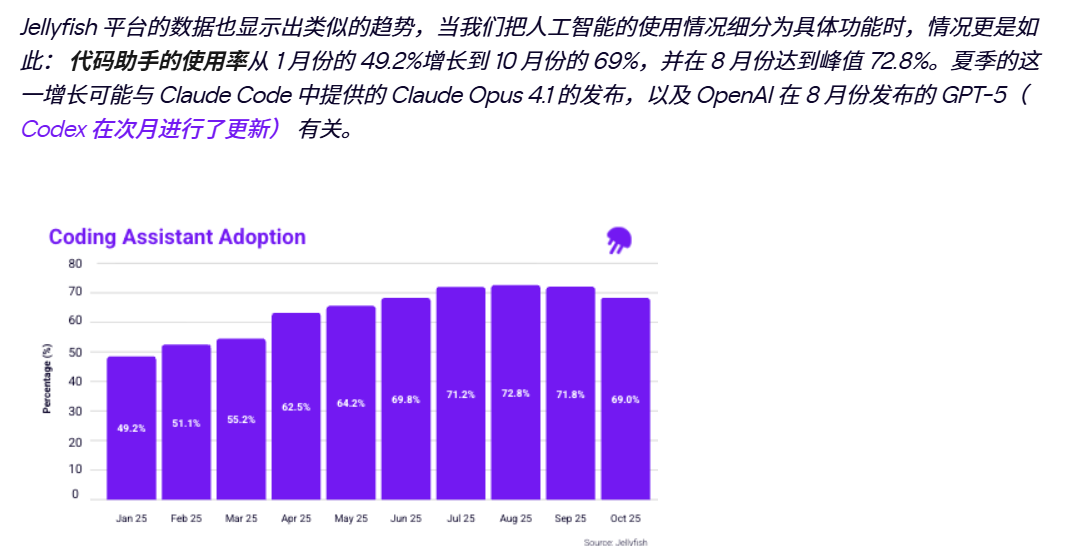
2025年的行业调查显示,82.3%的团队报告生产效率提升超过20%,其中24.1%的团队效率提升超过50%。代码审查和文档生成是2025年新晋主流用例,前一年这两项还不在榜单前列。

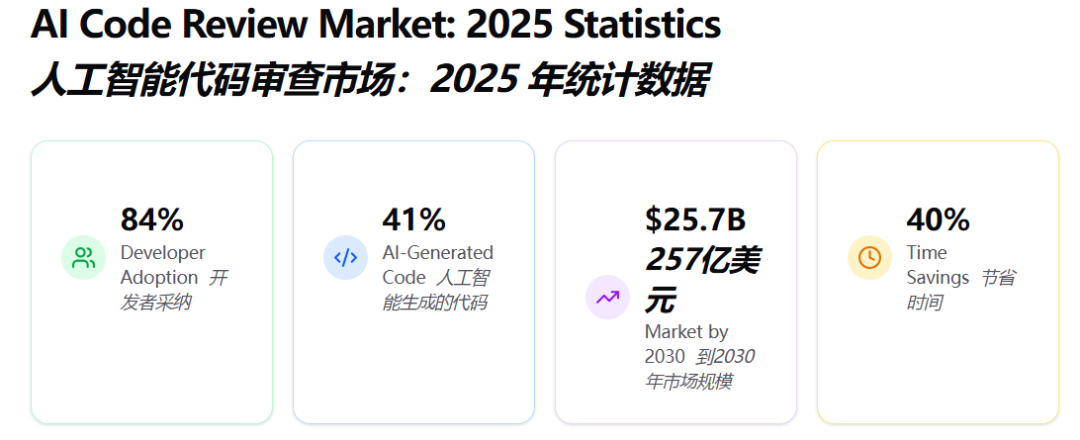
AI代码审查市场预计从2024年的67亿美元增长到2030年的257亿美元。这不是一个小数字。
谁在享受收益
表面上,开发者节省了时间,代码质量提升了,团队效率更高了。

有一个具体案例值得拆开看。一家拥有25名开发者的中型电商平台,在2024年第四季度引入AI代码审查工具后,PR审查时间从平均18小时降至4小时,生产环境Bug减少62%,此前因审查积压而延迟数月的3个主要功能得以上线。资深开发者报告,用于常规审查的时间减少了70%,这部分时间被重新分配给了架构规划和对初级工程师的指导。

https://www.digitalapplied.com/blog/ai-code-review-automation-guide-2025
如果深一层看:真正受益的,是需要管理大规模工程团队的公司。代码审查曾经依赖资深工程师的经验判断,这是一种难以标准化、难以复制的能力。AI的介入,让这种能力部分可量化、可自动化。
换句话说,它降低了对“稀缺人才”的依赖。
谁在承担风险
风险结构并不对称。

https://www.qodo.ai/reports/state-of-ai-code-quality/

一项行业报告显示,76%的开发者处于“红色区域”——他们频繁遭遇AI幻觉(hallucination),且对AI生成代码的可信度评价偏低。这是目前最大的群体。他们在使用AI工具,但不信任输出结果,其直接后果是重复检查、丢弃、重写,投入回报率有限。


https://www.netcorpsoftwaredevelopment.com/blog/ai-generated-code-statistics
GitClear对超过1.53亿行代码的分析发现,AI工具可能正在悄悄改变代码的写法和可维护性——代码重复率上升了4倍,短期代码改动频率也在增加,这意味着更多复制粘贴、更少可持续设计。

https://www.augmentcode.com/tools/open-source-ai-code-review-tools-worth-trying
更隐蔽的风险还有一个维度。对470个PR(Pull Request拉取请求)的行业分析发现,AI生成的代码包含的缺陷数量是人工编写代码的1.7倍。AI代码审查工具需要验证的,恰恰是越来越多由AI生成的问题代码。这是一个自我循环的结构:AI生产代码,AI审查代码,问题在这个闭环里以某种我们还没完全看清的方式积累。
真正值得追问的是:当AI建议被大量接受之后,代码风格的话语权,是不是在从工程师转移向模型提供商?
Google的取舍逻辑
Google目前有25%的代码由AI辅助生成,CEO Sundar Pichai将此定性为“工程速度的提升”而非“人员替代”,并表示生产效率提升约10%。
这句话值得仔细读。Google选择公开强调的是速度,而不是质量或成本节约。这个表述本身就是一种信号管理——在内部,它需要向工程师团队解释AI工具的定位;在外部,它需要管理市场对“AI替代工程师”这一叙事的预期。
如果真的只是效率提升10%,那意味着Google庞大的工程投入里,AI代码生成和审查带来的边际价值,比行业宣传的数字要克制得多。
表象背后的因果关系
文章反复强调“AI是补充,不是替代”——这句话本身没错,但背后有一个因果逻辑值得拆开看:
如果AI处理的是80%的常规检查,那么人类审查员的注意力就会集中在剩余20%的复杂问题上。这听起来是效率提升,但同时也意味着,初级开发者参与日常代码审查、从中学习成长的机会在减少。
GitHub Copilot的代码补全率为46%,但只有约30%的建议最终被开发者采纳。这个数字有两种读法:乐观的读法是,开发者在主动筛选、保持判断力;悲观的读法是,有70%的AI输出在消耗开发者注意力,制造一种持续的低信号噪声。
谁在享受效率红利?是已经掌握能力的资深工程师。谁在承担机会成本?是正在成长中的新人。
如何用,才算没用错
几个关键操作,新手也可以理解:
建立人工兜底机制。 AI做初筛,人工做最终判断,特别是涉及架构和业务逻辑时,不能把决策权完全交给机器。
记录哪些建议被拒绝了,以及为什么。 这不是走程序,这是让AI系统持续校准的唯一方式。
安全问题单独处理。 AI生成的涉及用户输入、数据库操作、权限验证的代码,必须人工复核,不能依赖自动化扫描自证清白。
配置优先于依赖默认值。 不同团队、不同业务场景,对代码的敏感度要求不同。直接用开箱即用的规则集,等于用别人的标准管自己的代码。
最后一个问题
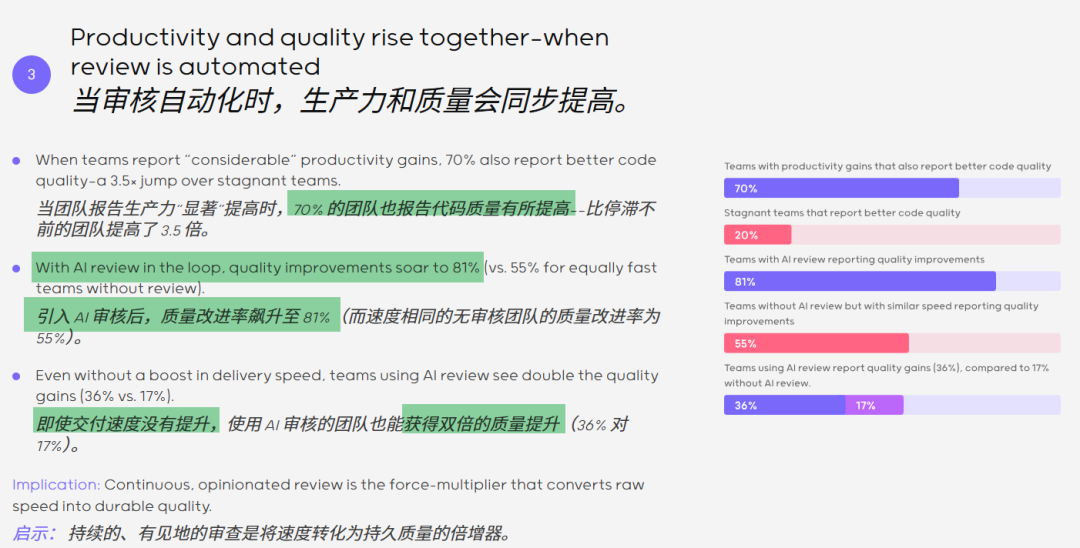
当团队报告“显著”生产效率提升时,70%的团队同时报告了代码质量改善;引入AI审查后,这一比例进一步上升至81%。
这套指标本身没有问题。
但真正值得追问的是:有没有一套指标,在衡量团队工程能力的长期成长?毕竟,提高了工具的效率和降低了人的能力,在短期财务报表上,看起来是同一件事。
在庆祝效率提升之前,值得有人去设计另一套量尺,专门量那些慢慢变化、短期看不见的东西。
我们这一代人在适应AI的过程中,要想清楚,新环境里什么能力值得主动培养。
比如:清楚自己在想什么,为什么这么想,以及什么时候不该相信眼前的答案。
文章专业术语解释
AI代码审查(AI Code Review)
开发者写完代码提交后,由AI工具自动扫描这段代码,找出问题并给出修改建议的过程。相当于给代码配了一个不会累、随时在线的“检查员”。
PR / Pull Request(拉取请求)
开发者写完一段新功能或修复后,向主代码库发起的“申请合并”请求。合并之前,团队其他人(现在加上AI)会检查这段代码有没有问题。可以理解为“提交审批”。
静态分析(Static Analysis)
不运行代码,只看代码本身的文字结构来查找问题,类似于语文老师批改作文时不需要把文章“读出声”,看着就能找语病。传统工具做的是静态分析,AI工具在此基础上能理解语义。
误报(False Positive)
AI把没有问题的代码标记为“有问题”。就像安检仪把一瓶水误判成危险品——触发了警报,但实际上不是威胁。误报多了,开发者会开始忽略所有提示,真正的问题反而被淹没。
AI幻觉(Hallucination)
AI生成了看起来合理、实际上完全错误的内容。在代码场景里,表现为AI给出一段逻辑清晰但根本跑不通、甚至会引发安全问题的代码建议。名字来自医学术语,指感知到不存在的事物。
代码上下文(Code Context)
理解一段代码,不能只看这几行,还要知道它在整个程序里是干什么的、前后有哪些依赖。这就是“上下文”。老一代工具做不到这点,现代AI工具的核心竞争力之一就是能理解上下文。
CI/CD 流水线(CI/CD Pipeline)
CI是“持续集成”,CD是“持续交付/部署”。简单说就是:开发者每次提交代码后,系统自动运行一系列检查(测试、扫描、构建),没问题就自动推送到线上环境。AI代码审查通常作为其中一个自动化步骤嵌入进去。
Webhook
一种自动通知机制。比如开发者刚提交了代码,代码托管平台(如GitHub)会自动向AI审查工具发送一条通知,触发审查流程。不需要人工手动启动,事件发生、审查自动开始。
架构决策(Architectural Decision)
决定整个系统怎么搭建的顶层选择,比如“用微服务还是单体架构”、“数据库选关系型还是文档型”。这类决策影响深远、牵一发动全身,是目前AI工具普遍做不好、也不该完全依赖AI的领域。
技术债务(Technical Debt)
为了赶进度而走的“捷径”,日后需要花时间补回来的代价。代码写得不规范、没有测试覆盖、架构设计图省事——这些都是在“借债”。AI代码审查的价值之一,是在债务积累之前提早发现问题。
代码覆盖率(Code Coverage)
测试用例覆盖了多少比例的代码逻辑。覆盖率高,意味着大部分代码都经过了自动化测试验证;覆盖率低,意味着很多代码在“裸奔”——出了问题才知道。
N+1查询问题(N+1 Query Problem)
一种常见的性能陷阱。程序本来只需要查一次数据库,结果因为代码写法问题,变成查了1次之后,又循环查了N次。数据量小时感觉不出来,数据量大时系统会明显变慢甚至崩溃。
反馈回路(Feedback Loop)
系统根据结果不断自我调整的机制。在AI代码审查场景里,指的是:记录哪些AI建议被接受、哪些被拒绝,并用这些数据持续优化AI的判断标准。没有反馈回路,AI只会重复犯同类错误。
回顾与展望
它是怎么走到今天的
从“人传人”开始
代码审查最早是一种手艺传承。老工程师坐在新人旁边,一起看代码,一起找问题。效率不高,但有个隐藏价值——新人在这个过程里学的,不只是“这行代码错了”,而是“为什么错,怎么想对”。
这是代码审查最朴素的形态,也是它最有温度的阶段。
工具来了,速度快了,但少了点什么
后来出现了自动扫描工具。格式不对?标出来。语法有误?标出来。效率提升了好几倍,但工具有个天然的短板——它只会对照规则,不会理解意图。就像一个只背过语法书、从没读过小说的人来帮你修改文章,他能找出错别字,但他不知道你这句话想表达什么感情。
AI读懂了代码,但账还没算清楚
2022年之后,事情开始真正有趣起来。以GitHub Copilot为代表的AI工具,不再只是对规则,而是开始“理解”代码在做什么。有团队因此把18小时的审查周期压缩到4小时,效果是真实的。
但与此同时,研究者发现AI介入后代码重复率上升了四倍,AI给出的建议有70%最终被开发者否掉。效率的账算清楚了,质量的账,还在算。
这三步走下来,代码审查完成了一次深刻的变化:从经验传递,到规则执行,再到AI辅助判断。每一步都有收获,每一步也都有东西留在了原地。
接下来,我大胆猜三件事
第一,“会用AI”这件事,会比“会写代码”更值钱。
这不是说写代码不重要了。而是当AI能帮你写、帮你查、帮你改,真正稀缺的能力变成了:知道AI在哪里会出错,并且能在它出错之前拦住它。这种能力,没法靠刷题获得,靠的是大量真实的判断积累。
好消息是,这件事是可以练的。而且越早开始练,越有优势。
第二,代码审查会成为AI治理的第一个“实验田”。
今天关于AI的很多讨论,都停留在宏观层面——监管怎么设计,责任怎么划分,风险怎么控制。但代码审查是一个少见的、足够具体的场景:输入是代码,输出是建议,对错可以被验证,影响可以被追踪。
如果人类要学会和AI协作,代码审查可能是最好的练习场。从这里摸索出来的经验,迟早会被用到更大的地方。
迟早会有一次严重事故,然后行业才会真正建立规矩。这不是恐吓,是规律。汽车出现之后有了交通法规,互联网出现之后有了数据保护条例。AI代码审查还太新,还没出过足够大的事故。但那一天会来,来了之后,今天所有的“最佳实践”才会真正变成硬约束。
第三,未来的工程师教育,会把“理解AI的局限”列为必修课。
不是因为AI不好,而是因为工具越强大,使用者越需要清醒。就像计算器普及之后,数学教育没有消失,反而更强调“估算能力”和“对结果的直觉判断”。AI代码审查普及之后,工程师教育同样会迎来一次升级——升级的方向,是更深的系统理解,而不是更熟练的键盘操作。
这篇文章,我们试图做的事情很简单:把一件正在发生、但还没被大多数人注意到的事,讲清楚。
不制造焦虑,不贩卖恐惧。技术的每一次演进,都有人适应,都有新的机会冒出来。这一次,也不会例外。
我愿意和读者一起期待。
本文基于公开行业数据与报告编译整理,结合实践案例分析,不代表对任何特定产品的背书或批评。关于DevOps自动化与代码质量管理的更多深度技术文档与讨论,欢迎访问云栈社区进行探索。
 发表于 2026-3-8 01:59:30
|
查看: 163|
回复: 0
发表于 2026-3-8 01:59:30
|
查看: 163|
回复: 0
