你是否厌倦了在通用搜索引擎中筛选海量广告和不相关信息?对于开发者或技术研究者而言,一个能直达高质量信息源、并保障隐私的搜索工具至关重要。Perplexica 是一款注重隐私的开源 AI搜索引擎,它能够在你自己的硬件上运行,结合了互联网的实时信息与大型语言模型的推理能力,为你提供带有准确来源引用的答案。
其核心特色包括:
- 🤖 广泛的AI模型支持:既可通过 Ollama 使用本地大型语言模型,也能连接 OpenAI、Anthropic Claude、Google Gemini、Groq 等云端服务,让你根据需求灵活选择。
- ⚡ 智能搜索模式:提供“速度”、“平衡”、“质量”三种模式,分别对应快速回答、日常查询和深度研究。
- 🔍 私有化网页搜索:默认由 SearxNG 提供支持,这是一个开源的元搜索引擎,能在聚合多个搜索引擎结果的同时保护你的隐私。
- 📄 多格式文件理解:支持上传 PDF、文本、图片等文档,并针对文档内容进行提问和分析。
- 🌐 指定网站搜索:当你明确知道目标信息所在领域时,可以限定只搜索特定网站(如技术文档站、学术论文库),大幅提升效率。
- 📚 信息管理:所有搜索历史、上传的文件都会保存在本地,方便你随时回溯和管理自己的研究资料。
下面,我们来看看如何在自己的 NAS 上通过 Docker容器 快速部署它。
部署安装
Perplexica 提供了两种 Docker Compose 部署方式。第一种是集成版,包含了内置的 SearxNG 服务,开箱即用。
services:
perplexica:
image: itzcrazykns1337/perplexica:latest
container_name: perplexica
ports:
- 3000:3000
volumes:
- ./data:/home/perplexica/data
restart: always
第二种是轻量版,不包含 SearxNG,需要你自行部署并连接一个外部的 SearxNG 实例。这种方式更灵活,适合已经拥有 SearxNG 服务或希望进行更复杂配置的用户。
services:
perplexica:
image: itzcrazykns1337/perplexica:slim-latest
container_name: perplexica
ports:
- 3000:3000
volumes:
- ./data:/home/perplexica/data
environment:
- SEARXNG_API_URL=http://your-searxng-url:8080
restart: always
searxng:
image: searxng/searxng:latest
container_name: searxng
ports:
- 8080:8080
volumes:
- ./searxng:/etc/searxng
environment:
- BASE_URL=http://your-searxng-url:8080
restart: always
选择其中一种方式,将 docker-compose.yml 文件保存到 NAS 的某个目录,然后在该目录下执行 docker-compose up -d 即可启动。
配置与使用
容器启动后,在浏览器中输入 http://你的NAS_IP:3000 即可访问 Perplexica 的 Web 界面。
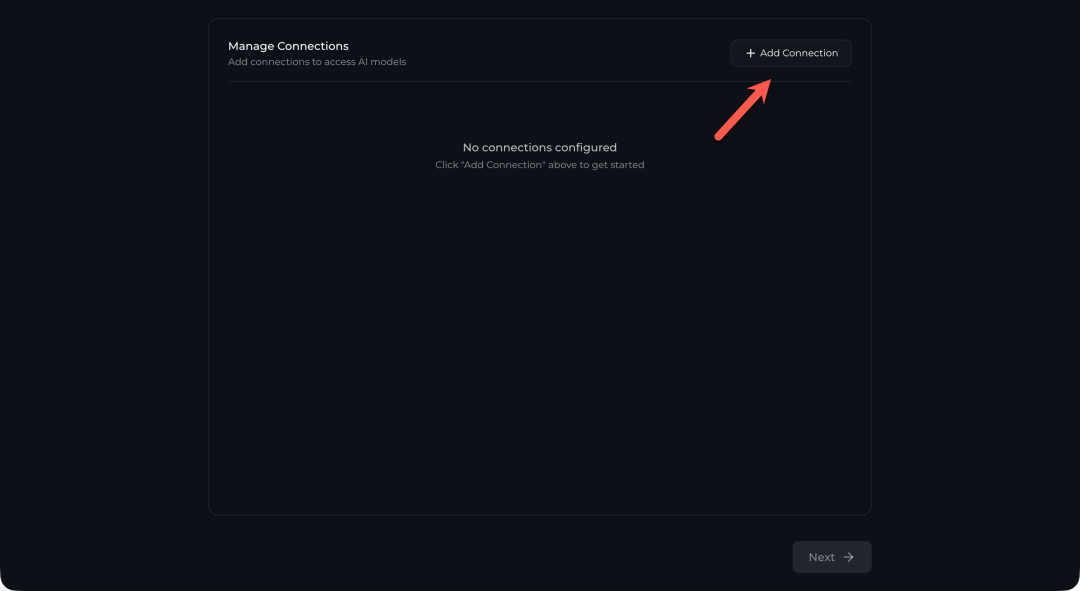
首次使用需要进行简单的初始化配置。首先,点击界面上的 “+ Add Connection” 来添加一个 AI 模型连接。
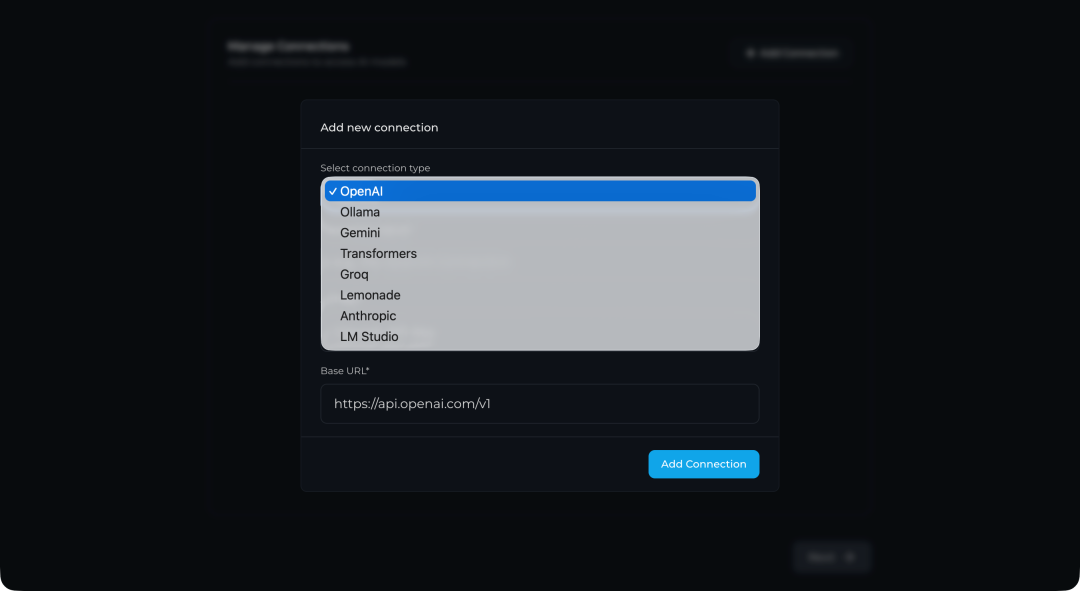
Perplexica 支持众多 AI 提供商,包括 OpenAI、Ollama、Gemini 等。为了使用国内可访问的模型,这里我们选择兼容 OpenAI API 的接口。许多国内模型平台(如硅基流动、深度求索等)都提供了兼容 OpenAI 的 API。
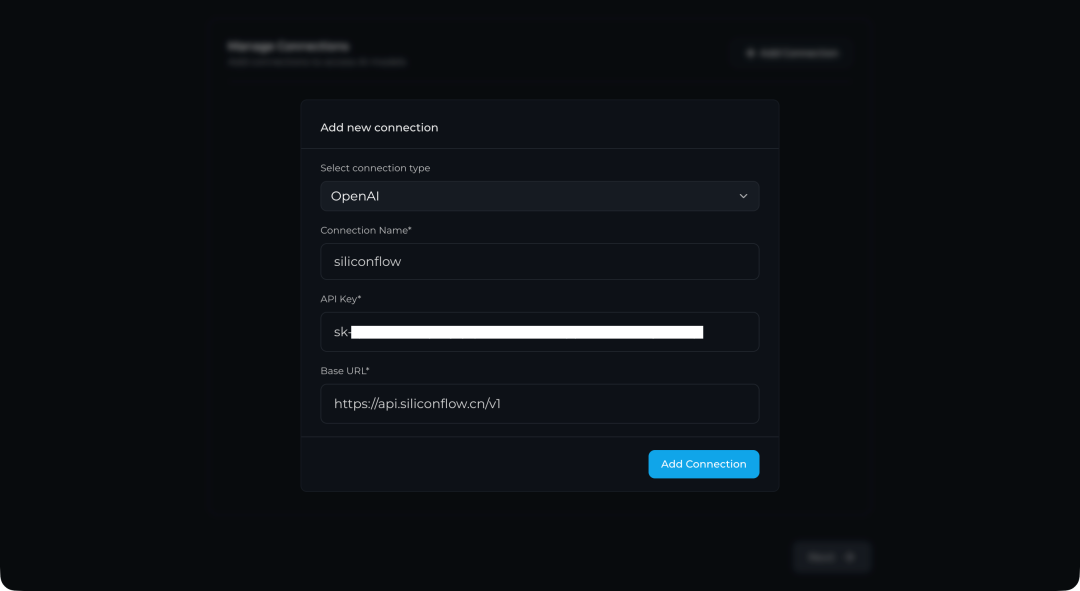
以硅基流动 (SiliconFlow) 为例,在连接配置中填入:
- Connection Name:
siliconflow (可自定义)
- API Key: 你的平台 API Key
- Base URL:
https://api.siliconflow.cn/v1
配置好连接后,还需要为此连接添加具体的“对话模型”和“嵌入模型”。点击 “CHAT MODELS” 下的 “+ Add”。
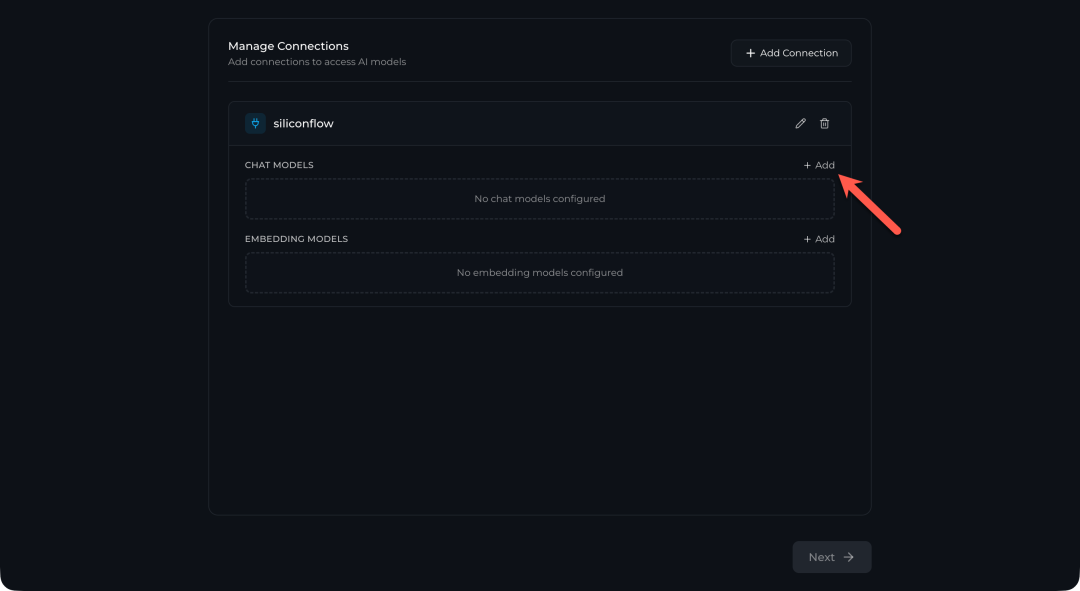
在弹出窗口中,填写你希望使用的模型名称。例如,可以使用 DeepSeek 的模型:
- Model name:
DeepSeek-V3.2
- Model key:
deepseek-ai/DeepSeek-V3.2
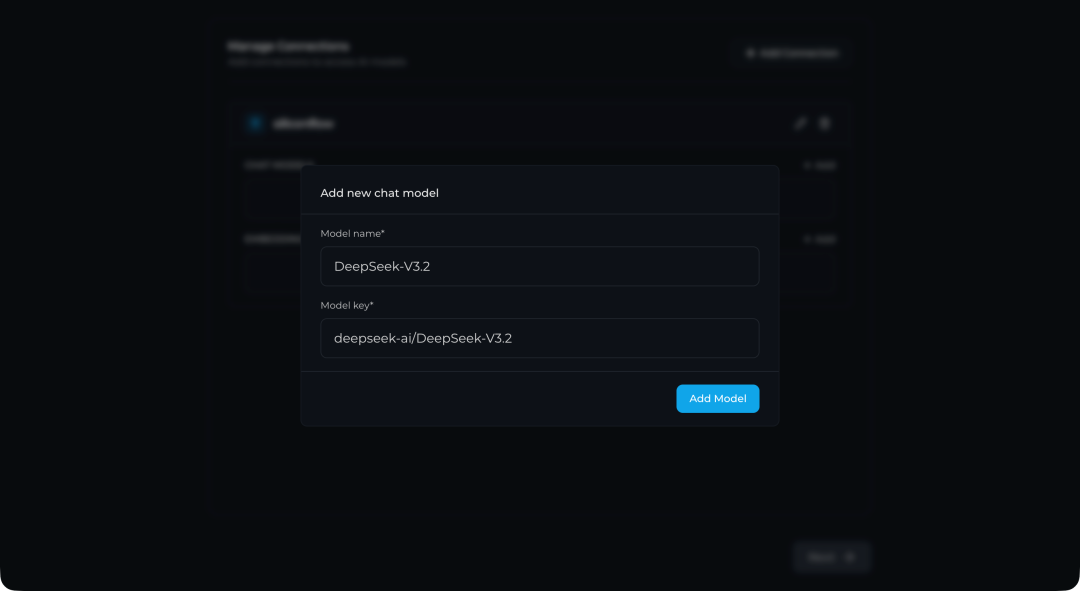
同样地,点击 “EMBEDDING MODELS” 下的 “+ Add” 来添加一个用于文本向量化的模型。这一步不是必须的,你可以直接使用对话模型来兼任,但专用的嵌入模型通常效果更好。例如,添加 Qwen 的嵌入模型:
- Model name:
Qwen3-Embedding-8B
- Model key:
Qwen/Qwen3-Embedding-8B
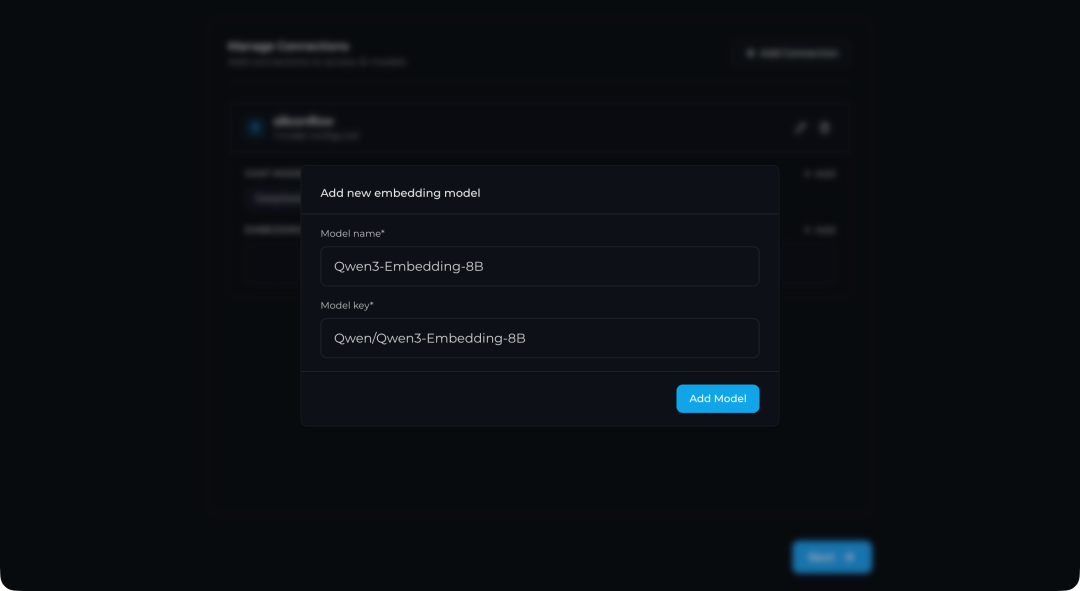
添加完模型后,界面会显示已配置的模型列表。确认无误后,点击右下角的 “Next →”。
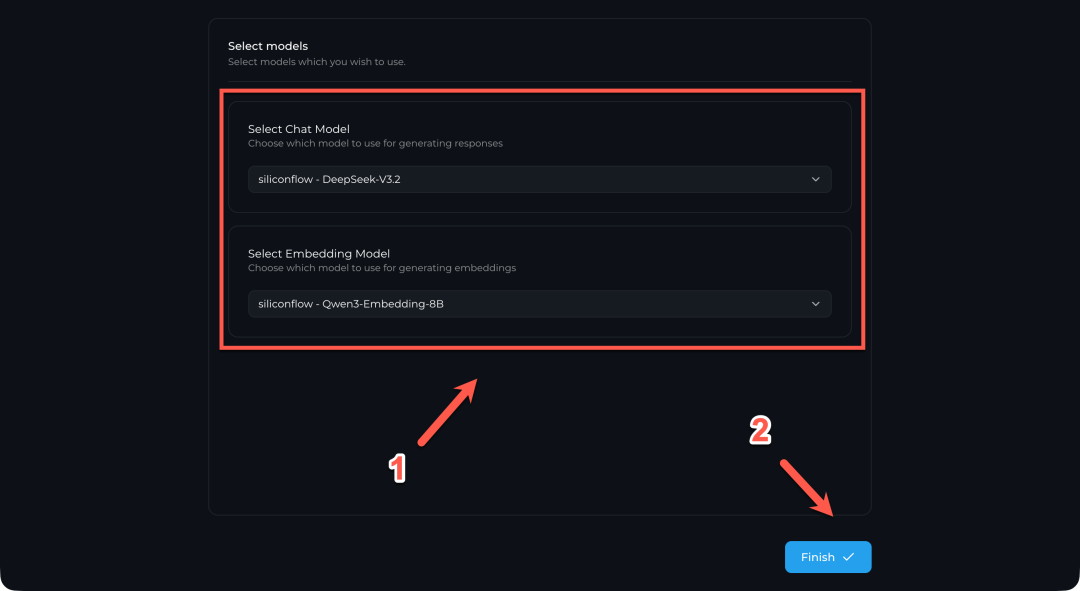
在最后的模型选择页面,分别在下拉菜单中选择刚才配置的对话模型和嵌入模型,然后点击 “Finish” 即可完成初始化。
现在,你就进入了 Perplexica 的主界面,可以开始使用了。界面中央的输入框就是你的搜索入口。
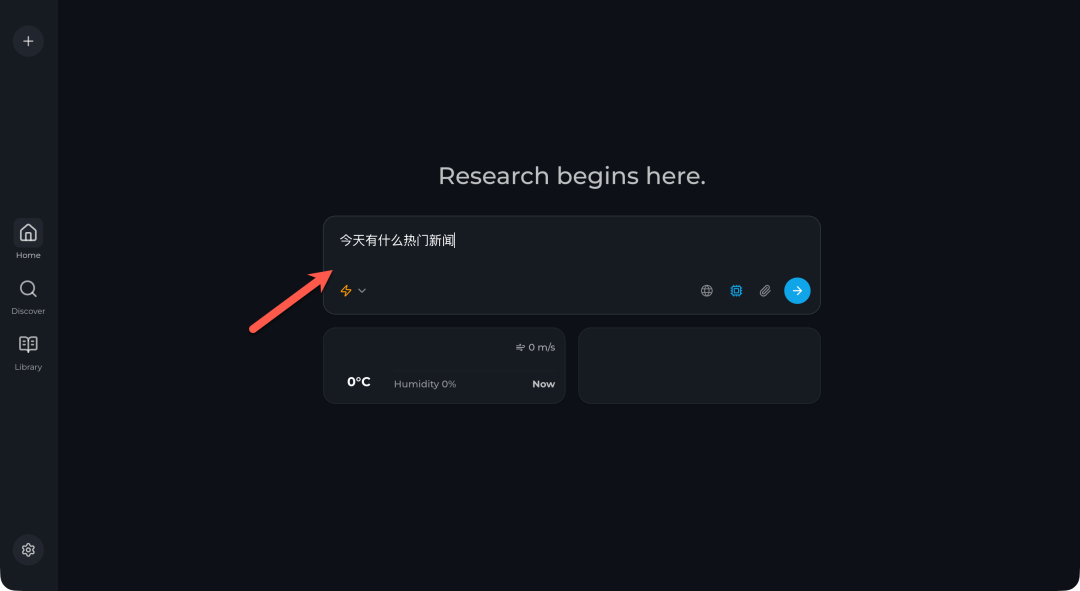
实际体验
我们直接输入一个常见问题来测试效果,例如:“今天有什么热门新闻”。
Perplexica 会立即开始工作。与直接询问通用 AI 不同,它的工作流程是:先通过 SearxNG 在互联网上实时搜索相关信息,然后利用你配置的 AI 模型对搜索结果进行整理、归纳和总结,最后生成一份结构清晰的答案报告。
可以看到,生成的答案质量相当高,信息聚合效率远超传统的手动搜索。
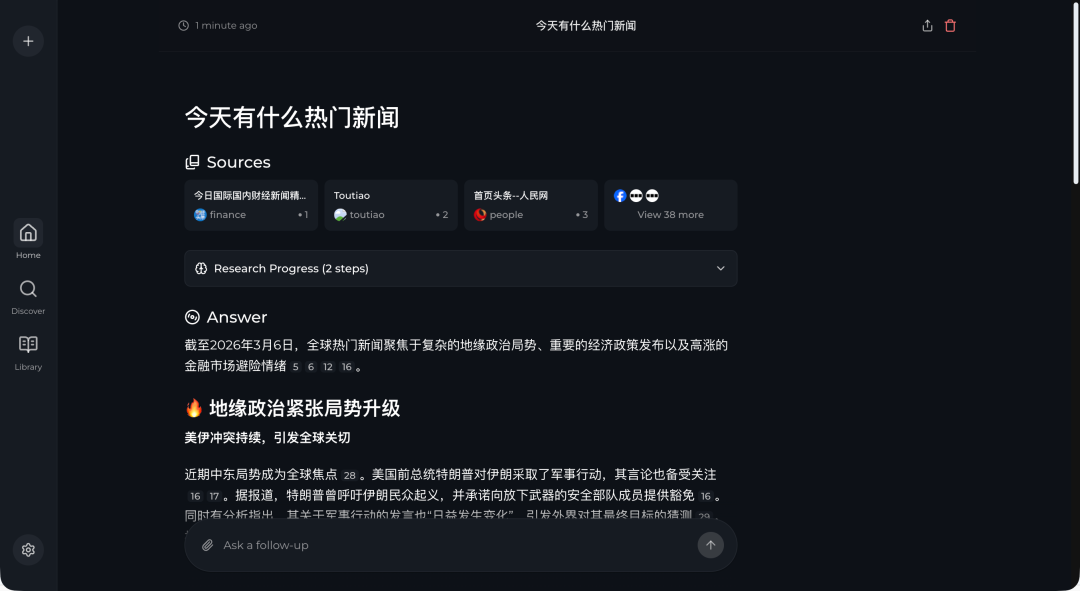
最关键的特性是,答案中的每一段陈述几乎都标有数字上标,这些上标对应左侧 “Sources” 栏中的信息来源链接。你可以轻松点击查看原文,核验信息的真实性和上下文,这极大地增强了答案的可信度。
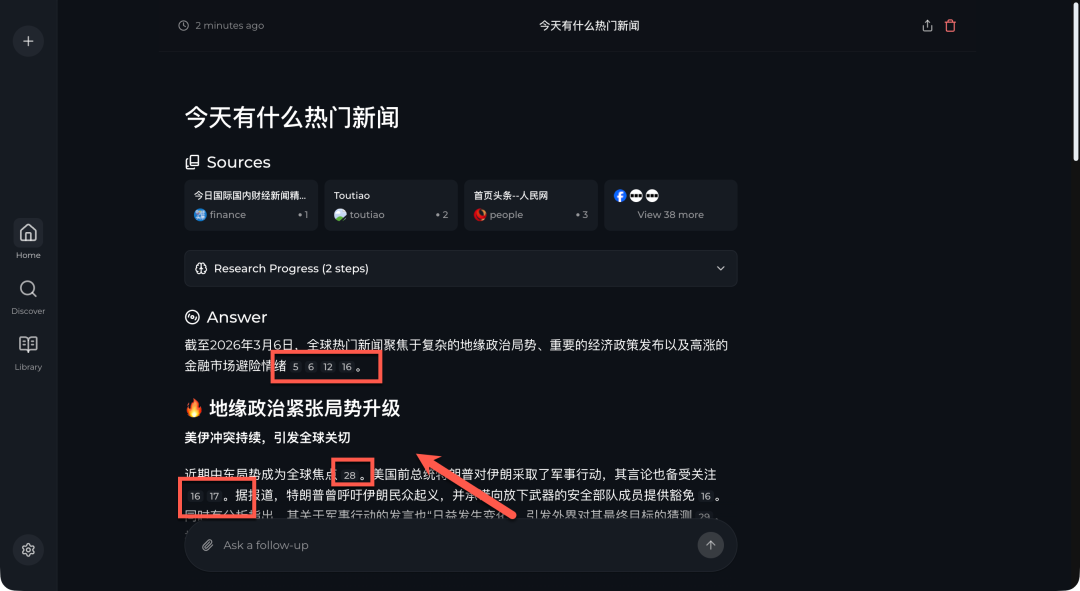
报告末尾,AI 还会根据当前话题,智能生成一系列相关的延伸问题,帮助你进行更深入的探索。
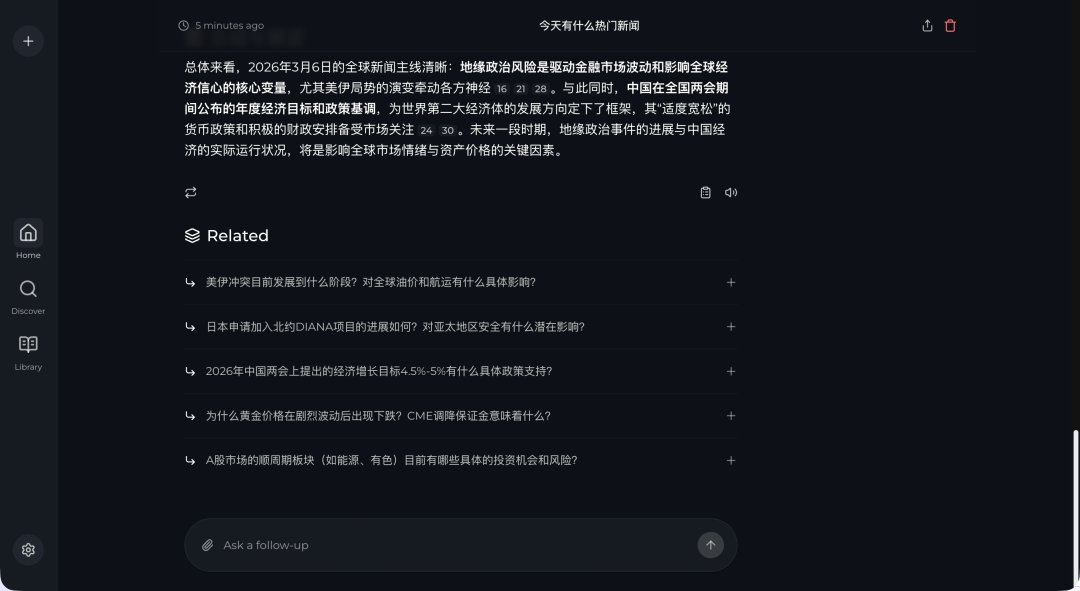
对于有价值的搜索结果,你可以点击右上角的导出按钮,将整个对话(包括问题、答案和来源)导出为 Markdown 或 PDF 格式的文件进行保存,方便日后查阅或分享。
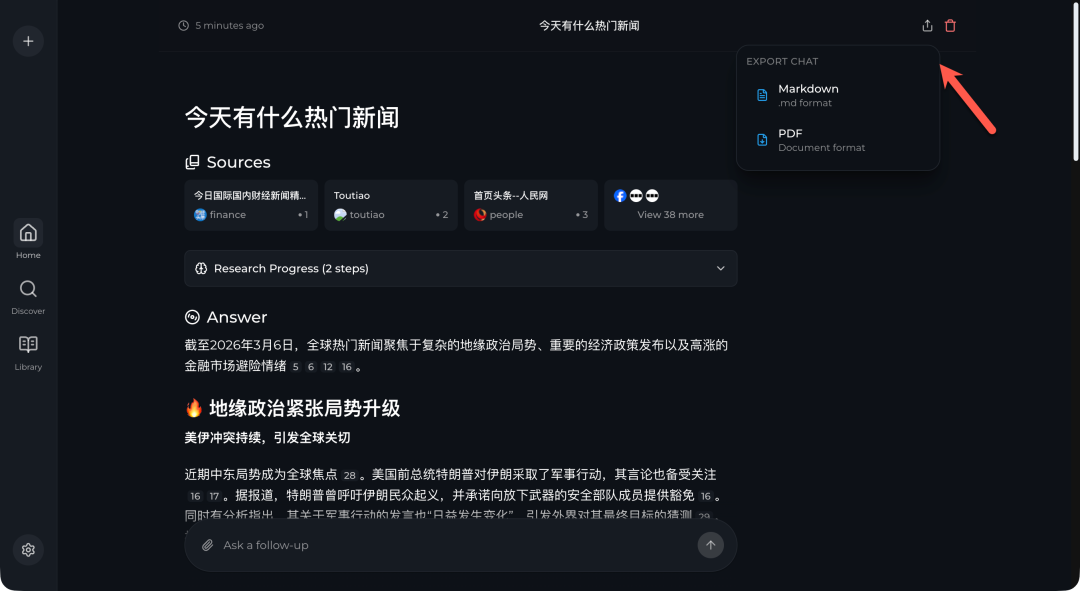
如果你对默认 “Balanced” 模式下的快速答案不够满意,可以在提问前点击输入框左侧的地球图标,切换到 “Quality” 模式。该模式下,AI 会进行更深度、多步骤的搜索和思考,当然耗时也会更长,但最终答案的广度和深度会显著提升。
在 “Quality” 模式下,你可以在侧边栏实时看到 AI 的“思考过程”,包括它规划了哪些搜索查询、找到了多少结果等,整个过程非常透明。
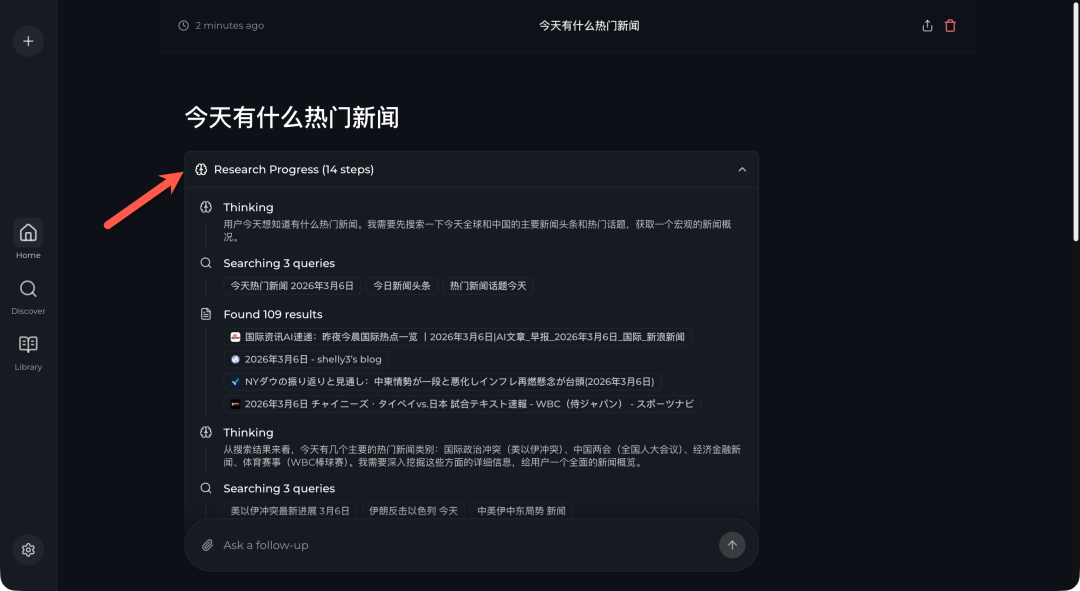
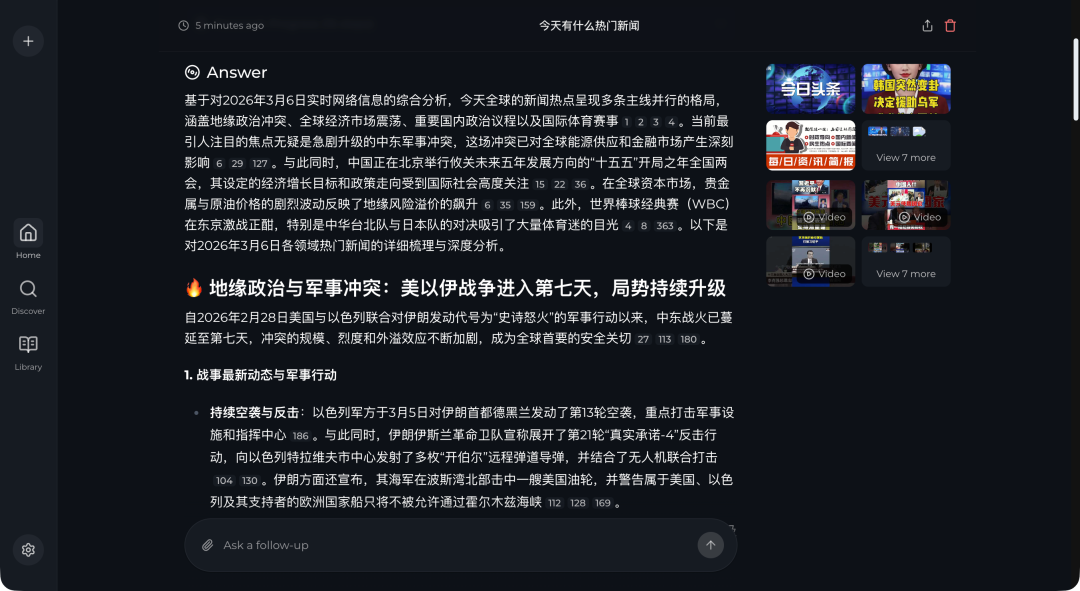
最终生成的报告内容也更为详实,更像一篇经过充分调研的综述。
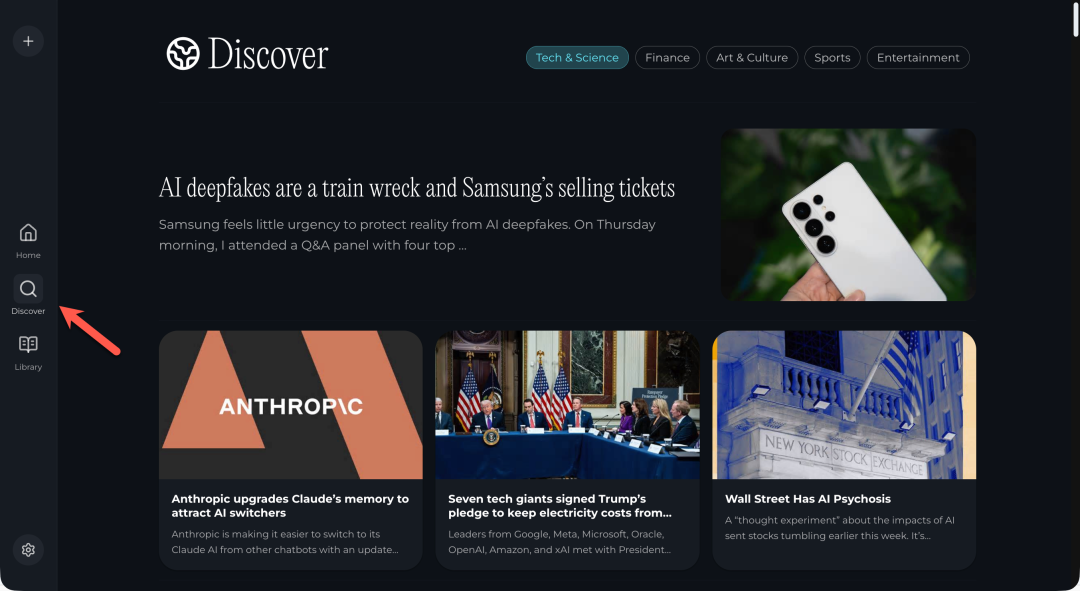
除了主动搜索,Perplexica 还提供了一个 “Discover” 页面,它会聚合当前网络上的热门或有趣的文章内容,帮你被动获取信息,保持对领域热点的敏感度。
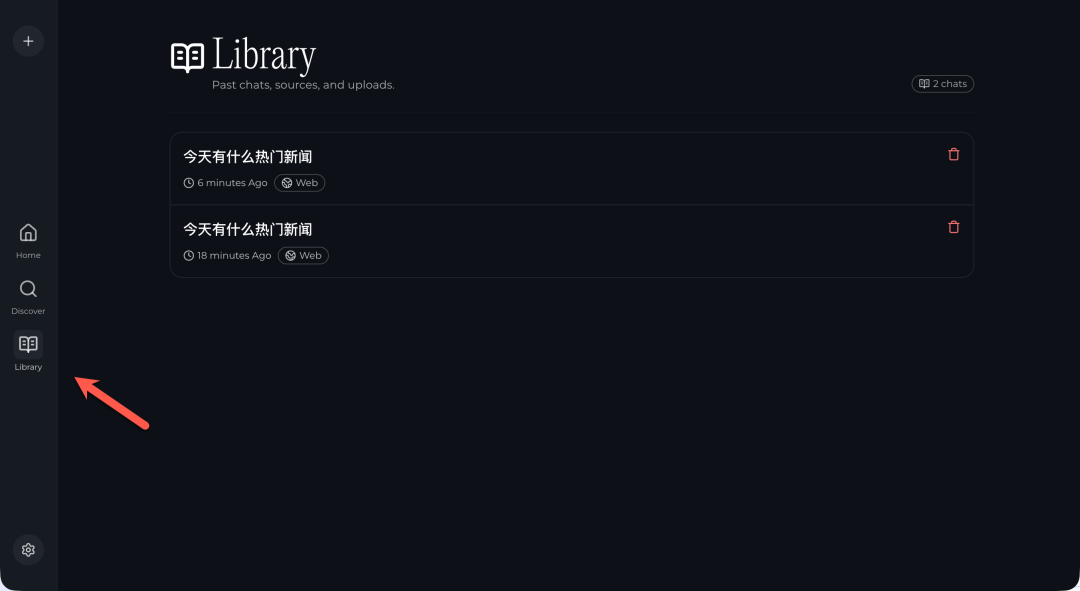
所有你进行过的搜索对话,都会自动保存在 “Library” 库中。你可以随时回来查看历史记录,快速回溯之前的研究内容。
总结
经过一段时间的体验,Perplexica 确实给人带来了惊喜。对于需要高频、高效获取高质量信息的技术人员或内容工作者来说,它解决了几个核心痛点:
- 信息提纯:利用 AI 从嘈杂的网络信息中快速提炼出关键内容,节省大量筛选时间。
- 来源可溯:每一条信息都附带原始链接,这不仅便于核验,也让你能够追溯到更丰富的上下文,这是普通 AI 聊天机器人无法做到的。
- 隐私可控:所有数据(搜索历史、上传文件)都保存在你自己的服务器上,搜索请求也通过私有 SearxNG 实例发出,隐私性有保障。
- 部署灵活:基于 Docker 的部署方式极其简单,无论是在 NAS、家庭服务器还是云主机上都能快速搭建。
实测中,即使不依赖特殊的“良好网络”,仅使用默认配置也能获得可用的搜索结果。对于有进阶需求的用户,完全可以单独深度配置 SearxNG,添加自定义搜索引擎或进行更复杂的网络设置。
总的来说,Perplexica 是一款能切实提升信息获取质量和效率的优秀开源工具。如果你正在寻找一个更智能、更私密的搜索解决方案,不妨在你的 NAS 上尝试部署一下。对于这类优秀的开源项目实践,也欢迎大家在 云栈社区 进行更多的交流和分享。
综合推荐:⭐⭐⭐⭐(绝非噱头,有效提高信息获取质量)
使用体验:⭐⭐⭐⭐(功能全面,模式灵活)
部署难度:⭐⭐(基于Docker,非常简单)
 发表于 2026-3-8 05:37:01
|
查看: 128|
回复: 0
发表于 2026-3-8 05:37:01
|
查看: 128|
回复: 0
