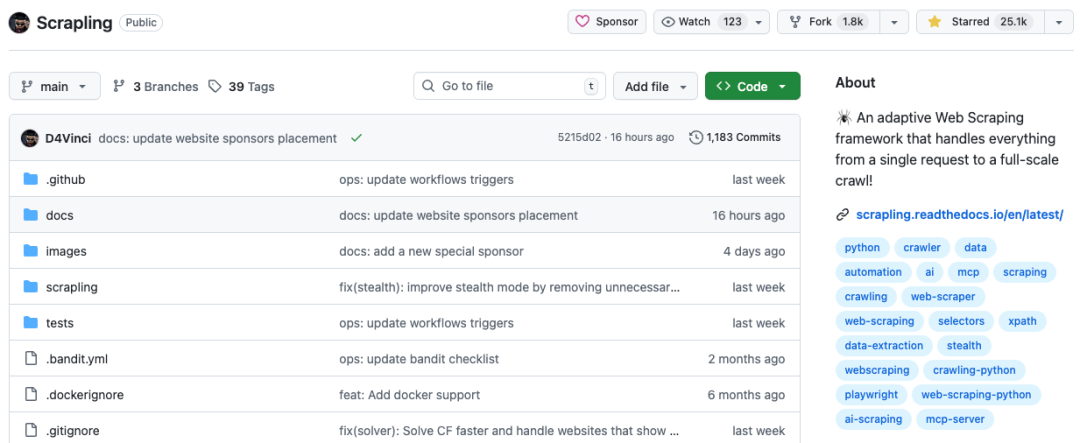
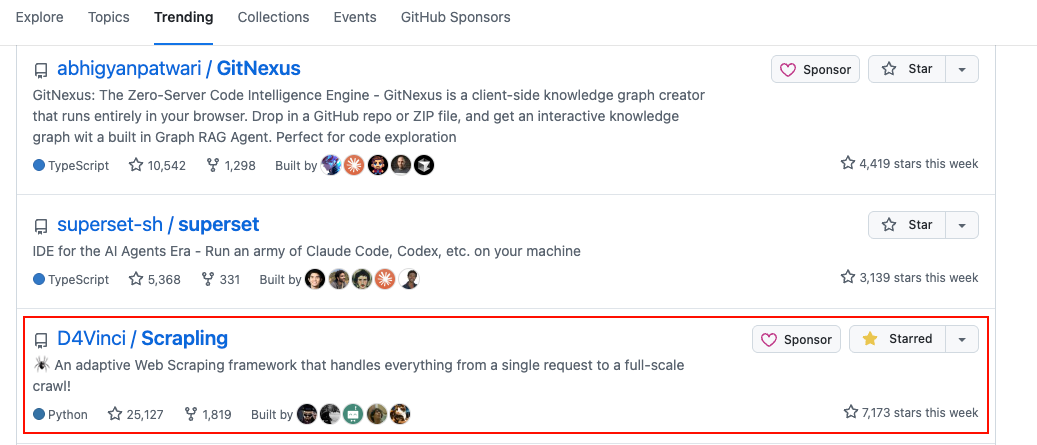
最近在 GitHub 上,一个名为 Scrapling 的 Python 项目正以惊人的速度获得关注,星标数已突破 2.5 万。对于需要经常进行数据抓取的开发者来说,这或许是一个值得深入研究的工具。
很多开发者都有过类似的困扰:花费大量时间编写的爬虫脚本,一旦目标网站进行改版,之前精心编写的 CSS 选择器 或 XPath 路径 便瞬间失效,所有工作推倒重来。这种“网站一变,代码就挂”的窘境,着实令人头疼。更严峻的是,如今网站的反爬虫机制愈发严密,诸如 Cloudflare Turnstile、复杂的人机验证、浏览器指纹检测等技术层出不穷,使得数据采集工作变得像一场艰难的“游击战”。
传统的方案各有局限:BeautifulSoup 虽然易用,但面对大规模、高并发的爬取任务时性能堪忧;Scrapy 框架功能强大,但其学习曲线对于新手而言又显得过于陡峭。正是在这样的背景下,Scrapling 的出现,似乎提供了一个新的解题思路。该项目近期在 GitHub 趋势周榜上表现抢眼,热度持续不减。
项目简介
Scrapling 被定义为一个“自适应”的 Web 爬虫框架。其核心目标并非简单地“能爬”,而是致力于让爬虫具备“学习”和“适应”的能力。它的设计理念强调“一个框架,零妥协”——旨在用统一的方案处理从单次页面请求到大规模分布式爬取的所有场景。
这个项目最引人注目的特点在于,它的解析器能够学习并记忆网页的结构特征。当页面布局发生变动时,它可以自动尝试重新定位目标数据元素,而无需开发者手动调整选择器。与此同时,其内置的请求器能够开箱即用地绕过 Cloudflare Turnstile 等主流反爬系统。
核心亮点
1. 🧠 自适应元素追踪
这是 Scrapling 解决“网站改版噩梦”的核心功能。与依赖固定路径的传统爬虫不同,Scrapling 的解析器会利用智能算法学习目标元素的视觉特征和上下文语义关系。
使用方法非常简单:在首次成功抓取时,通过 auto_save=True 参数保存元素的特征。之后即使网站改版,只需开启 adaptive=True 选项,框架便会利用多维相似度算法自动尝试找回目标元素。
from scrapling.fetchers import StealthyFetcher
page = StealthyFetcher.fetch('https://example.com', headless=True)
# 第一次爬取时保存元素特征
products = page.css('.product', auto_save=True)
# 后来网站改版了,开启自适应模式自动找回
products = page.css('.product', adaptive=True)
这种“编写一次,长期适配”的能力,对于需要长期监控的网站(如电商价格、新闻源)而言,价值巨大。
2. 🛡️ 强大的反反爬虫能力
Scrapling 提供了四种不同类型的 Fetcher(抓取器),以适应不同复杂度的场景:
Fetcher:基础的 HTTP 请求器,支持 TLS 指纹伪装,可模拟 Chrome、Firefox 等真实浏览器的指纹。AsyncFetcher:异步版本,提供更强的性能。StealthyFetcher:专为绕过 Cloudflare 等高级反爬系统设计,具备先进的隐身和指纹伪装功能。DynamicFetcher:基于 Playwright 的动态页面抓取器,支持完整的浏览器自动化操作。
其中,StealthyFetcher 可以自动化处理 Cloudflare Turnstile/Interstitial 验证,无需人工干预。
from scrapling.fetchers import StealthyFetcher, StealthySession
with StealthySession(headless=True, solve_cloudflare=True) as session:
page = session.fetch('https://nopecha.com/demo/cloudflare')
data = page.css('#padded_content a').getall()
此外,框架还内置了 ProxyRotator(代理轮换器),支持多种轮换策略,并可针对单个请求覆盖代理配置。
3. ⚡ 卓越的性能表现
根据官方基准测试,在涉及5000个嵌套元素的文本提取任务中,Scrapling 的解析速度相比 BeautifulSoup 有数百倍的提升。同时,其优化的数据结构和懒加载机制确保了极低的内存占用。在 JSON 序列化等操作上,性能也比 Python 标准库快一个数量级。这对于需要进行海量数据抓取的 开源项目 或商业应用至关重要。
4. 🕷️ 完整的爬虫框架
Scrapling 提供了类似 Scrapy 的 Spider API,让开发者能够轻松构建结构化的爬虫应用。其核心特性包括:
- 并发控制:可配置的并发数、按域名限流和下载延迟。
- 多会话支持:在单个爬虫内统一管理 HTTP 请求和无头浏览器会话,并可按需路由。
- 暂停与恢复:基于检查点的持久化机制,允许爬虫优雅暂停后从断点继续。
- 流式处理:支持通过
async for 实时流式输出抓取结果,并附带统计信息。
- 阻塞检测:自动检测并重试被阻塞的请求。
更强大的是,你可以在一个爬虫内混用不同类型的会话。
from scrapling.spiders import Spider, Request, Response
from scrapling.fetchers import FetcherSession, AsyncStealthySession
class MultiSessionSpider(Spider):
name = "multi"
start_urls = ["https://example.com/"]
def configure_sessions(self, manager):
manager.add("fast", FetcherSession(impersonate="chrome"))
manager.add("stealth", AsyncStealthySession(headless=True), lazy=True)
async def parse(self, response: Response):
for link in response.css('a::attr(href)').getall():
if "protected" in link:
yield Request(link, sid="stealth")
else:
yield Request(link, sid="fast", callback=self.parse)
5. 🤖 AI 友好集成
Scrapling 内置了 MCP (Model Context Protocol) Server,可以直接与 Claude、Cursor 等 AI 开发工具集成,实现 AI 辅助的数据提取。这能显著提升从复杂页面中提取结构化信息的效率,并通过减少传递给 AI 的上下文内容来降低 token 消耗成本。
快速安装与使用
Scrapling 要求 Python 3.10+。基础安装仅包含解析引擎:
pip install scrapling
如需使用请求器、爬虫框架等完整功能,需要安装额外依赖:
pip install "scrapling[fetchers]"
scrapling install # 下载浏览器及依赖
你也可以通过 Docker 快速体验:
docker pull pyd4vinci/scrapling
# 或
docker pull ghcr.io/d4vinci/scrapling:latest
基础使用示例
1. 简单的 HTTP 请求:
from scrapling.fetchers import Fetcher, FetcherSession
with FetcherSession(impersonate='chrome') as session:
page = session.get('https://quotes.toscrape.com/', stealthy_headers=True)
quotes = page.css('.quote .text::text').getall()
# 一次性请求
page = Fetcher.get('https://quotes.toscrape.com/')
quotes = page.css('.quote .text::text').getall()
2. 构建一个完整的爬虫:
from scrapling.spiders import Spider, Request, Response
class QuotesSpider(Spider):
name = "quotes"
start_urls = ["https://quotes.toscrape.com/"]
concurrent_requests = 10
async def parse(self, response: Response):
for quote in response.css('.quote'):
yield {
"text": quote.css('.text::text').get(),
"author": quote.css('.author::text').get(),
}
next_page = response.css('.next a')
if next_page:
yield response.follow(next_page[0].attrib['href'])
result = QuotesSpider().start()
print(f"Scraped {len(result.items)} quotes")
result.items.to_json("quotes.json")
3. 命令行工具:
Scrapling 提供了便捷的 CLI,无需编写代码即可完成简单抓取。
# 启动交互式爬虫 Shell
scrapling shell
# 直接提取页面内容到文件
scrapling extract get 'https://example.com' content.md
scrapling extract fetch 'https://example.com' content.md --css-selector '#main' --no-headless
适用场景与技术特点
典型应用场景
- 电商价格监控:利用自适应解析,无视前端频繁改版。
- 竞品数据追踪:借助高性能并发与反爬能力,稳定收集信息。
- AI 训练数据收集:快速、大规模地获取清洗后的数据。
- SEO 分析:自动化监控排名与竞争对手策略。
- 新闻聚合与知识库构建:定时抓取多源信息并自动化整理。
其他技术亮点
- 高代码质量:拥有 92% 的测试覆盖率。
- 完整的类型提示:提供优秀的 IDE 支持和代码补全体验。
- 丰富的 API:提供高级 DOM 遍历、增强的文本处理、自动选择器生成等功能。
- 熟悉的开发体验:API 设计上借鉴了 Scrapy 和 BeautifulSoup 的优点,降低了学习成本。

总结
总而言之,Scrapling 尝试将 自适应解析、强大的反爬绕过、高性能 以及 AI 集成 融合到一个 Python 框架中。它直指传统爬虫开发中的几个核心痛点:网站改版的维护成本、日益复杂的反爬机制以及大规模抓取的性能瓶颈。
对于正在寻找下一代爬虫解决方案的开发者,尤其是那些苦于应对动态网站和反爬系统的朋友,Scrapling 提供了一个值得尝试的新选择。它的设计理念降低了爬虫脚本的长期维护成本,并试图让数据抓取工作变得更加稳健和高效。
项目地址:https://github.com/D4Vinci/Scrapling

 发表于 2026-3-8 09:24:16
|
查看: 249|
回复: 0
发表于 2026-3-8 09:24:16
|
查看: 249|
回复: 0
