每次在网上看到那些回测曲线近乎完美、夏普比率高得离谱的量化策略展示,作为从业者,心里往往不是惊喜,而是立刻警觉:这十有八九是数据泄漏了,也就是俗称的“未来函数”在作祟。
回顾现有的量化防泄漏手段,很多人首先想到的是 Marcos Lopez de Prado 提出的 Purging(剔除)和 Embargo(隔离),或者组合交叉验证(CPCV)。这些方法对于处理时间序列自相关导致的标签重叠确实非常有效。
于是,不少人在实践中严格遵循了 Lopez de Prado 的框架,或者像 Gu、Kelly 和 Xiu 那样采用滚动窗口验证,以为这样就万无一失了。然而,一个常见的疏忽发生在数据预处理阶段:他们在模型训练前,对整个数据集的特征进行了 Z-score 标准化。正是这一步,全局的均值和方差悄无声息地将未来的信息“泄漏”给了历史样本。这还没算上诸如前复权处理、成分股变更、退市股带来的幸存者偏差、财报数据修正等更细微的陷阱。
最近一篇题为 Lookahead Bias in Alpha Factor Models 的论文给我带来了新的启发。为了量化未来函数带来的性能膨胀效应,作者 Merlini 做了一个颇为反直觉的决定:他完全没有使用真实的股票市场数据,而是手动构建了一个包含2000个交易日的合成数据集。
这听起来可能让人怀疑:一篇量化论文不用真实数据,如何让人信服?但关键在于,如果我们使用真实的市场数据,实际上根本无法确切证明某个因子是否真的包含了未来信息。你只能依靠猜测和人工代码审查。而合成数据的优势在此刻凸显出来:Merlini 自己定义了“上帝视角”的数据生成方程,在其中加入了几个干净的短动量、长动量、均值回归和波动率因子,同时故意掺入了一个名为 SmoothedSignal 的污染因子。这个听起来像某种高端私有平滑信号的因子,实际上与目标变量有着高达 0.80 的相关性。
仅仅这一个伪装信号,就将模型的 R² 从真实的 0.31 硬生生拔高到了 0.66,膨胀了约 53.4%。为了揪出这个“内鬼”,他设计了一套名为“Honest OOF”(诚实样本外)的评估协议。其中的前置泄漏扫描器,在划分任何训练集和验证集之前,直接在全量数据上计算皮尔逊相关系数和互信息。
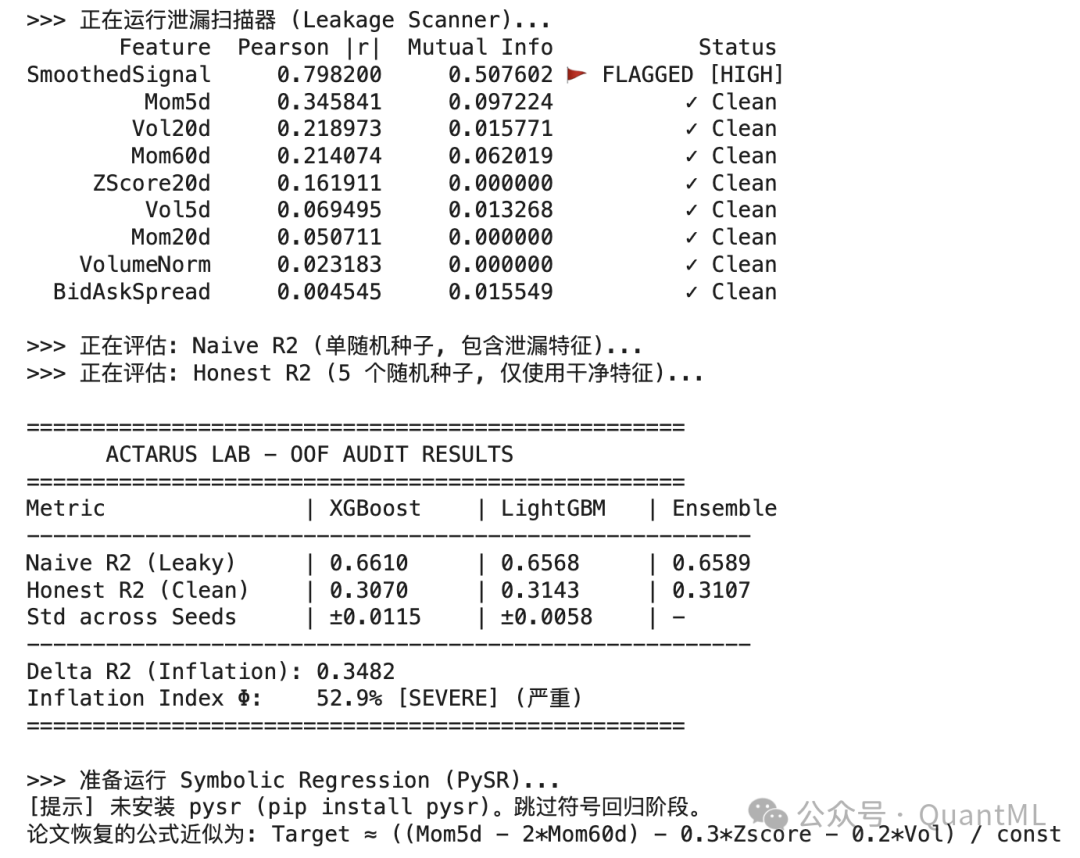
通过对论文的复现,我构造了一批干净的 Alpha 特征以及包含前瞻性偏差的特征,分别测试了因子相关性和互信息(MI),并进行了模型训练。结果与论文结论一致:一旦剔除未来函数,模型的 R² 从 0.66 大幅下降至 0.31。
这正是我想借这篇论文深入探讨的重点。Merlini 论文中指出的前置特征污染,恰好击中了现有防泄漏方法的一个正交维度的漏洞。即便你的交叉验证划分得再严谨,只要某个因子在构建时用到了尚未发生的数据,整个回测的公正性就被破坏了。那句老生常谈的准则——“模型训练时的 StandardScaler 必须只在训练折上拟合,再用于转换验证折”——据我所知,在许多机构的生产代码库里依然没有被严格遵循。
在后续分析中,我们使用符号回归工具 PySR 对剩下的干净数据进行了分析,结果几乎完整地还原出了原始的数据生成方程,包括符号和结构。
过去,符号回归在金融领域多被视为一个寻找公式的工具。而将其用作因子模型的“白盒审查工具”,则提供了一个新的思路。如果你喂给模型的特征是干净且符合逻辑的,符号回归理应能捕捉到符合经济直觉或因果关系的公式结构。反之,如果它产生了一堆难以解释的复杂结构,或者连基本的动量方向都搞错了,那么这组特征很可能仍然包含“脏数据”。
回测本质上是一场与自己的博弈。欺骗编译器、用华丽的图表说服他人都不难,真正的考验始于实盘交易启动的那一刻。接受一个平庸但真实的绩效数字,远比带着美好的幻觉将真金白银投入市场要明智得多。在机器学习驱动的量化研究过程中,对数据纯洁性的持续审计和警惕,是构建稳健策略不可或缺的一环。对这类话题的深入探讨,也欢迎在云栈社区与更多同行交流。 |  发表于 2026-4-23 01:44:34
|
查看: 219|
回复: 0
发表于 2026-4-23 01:44:34
|
查看: 219|
回复: 0
