刚刚,谷歌正式发布了首个原生多模态嵌入模型——Gemini Embedding 2。这次发布的核心突破在于,模型首次将文本、图像、视频、音频和文档全部映射进同一个统一的语义嵌入空间中。

简单来说,不同的数据模态第一次拥有了共通的语义坐标系。这项革新为更高级的多模态理解应用铺平了道路。
在输入能力上,Gemini Embedding 2支持以下数据类型:
- 文本:支持最多8192个token。
- 图像:每次请求最多处理6张图像,支持PNG和JPEG格式。
- 视频:支持最长120秒的视频输入,格式为MP4和MOV。
- 音频:支持原生嵌入音频数据,无需先将其转录为中间文本。
- 文档:可直接嵌入最多6页的PDF。
更为重要的是,模型不仅支持单一模态输入,还支持多模态混合输入(例如图像+文本)。这使得模型能够捕捉不同媒体之间的复杂语义关系,从而更准确地理解现实世界中的复合信息。
在评测方面,Gemini Embedding 2不仅整体性能较上一代有所提升,更在多模态嵌入任务上设立了新的性能基准。一方面,它显著增强了语音处理能力;另一方面,在文本、图像和视频等多项任务中都超越了现有领先模型,达到了新的SOTA水平。
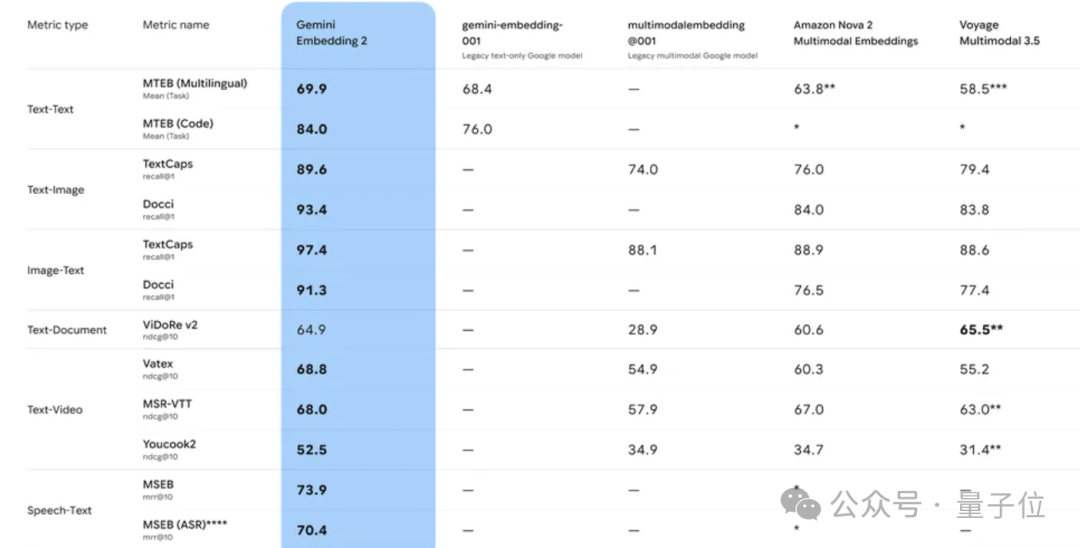
这看似只是一次底层嵌入模型的技术升级,但它实际上为AI Agent真正“看懂”并理解世界,提供了关键基础设施。
目前,Gemini Embedding 2已经通过Gemini API和Vertex AI平台展开公测。
原生多模态嵌入意味着什么?
嵌入模型的本质是将数据转化为稠密的向量表示。在这个向量空间中,语义相似的数据彼此靠近,不相似的数据则距离更远。
传统的嵌入模型主要针对文本。例如,在谷歌此前的论文 《Gemini Embedding: Generalizable Embeddings from Gemini》 中,模型利用大语言模型已有的海量知识构建表征,并将获得的嵌入用于语义检索、文本聚类、分类等下游任务。

但这仅限于文字范畴。最新的Gemini Embedding 2则首次彻底打通了多模态数据。文本、图片、视频、音频和文档,都被压缩到同一个向量空间之中。
这实现了“跨模态语义对齐”,让“猫”这个文字概念与一张猫的照片这个视觉概念,在统一的嵌入空间中拥有极度接近的数学向量表示。
通俗地说,当你搜索“猫”时,系统不仅能找到相关文字,还能直接关联到猫的图片、视频甚至叫声。因此,许多原本复杂的多模态流程可以被大幅简化。从 RAG检索、语义搜索、情感分析到数据聚类等应用场景,都能直接受益。
为AI Agent提供“感官总线”
这类能力对于AI Agent的发展意义尤为重大。
过去的Agent在操作电脑时,往往只能依赖屏幕上的文字信息,例如识别按钮上的“设置”、“确认”等标签。但真实世界的UI界面充满了视觉信息:图标、布局、颜色、控件位置等,这些都是传统文本嵌入模型难以处理的部分。
有了原生多模态嵌入之后,情况则完全不同。对于像OpenClaw(龙虾) 这样需要操作电脑、识别屏幕的Agent而言,它不再只是“阅读”文字。

它可以直接理解:哪个像素区域代表设置图标、哪个按钮与当前任务最相关,以及屏幕截图与文本指令之间的深层关系。
换句话说,Gemini Embedding 2为AI Agent提供了一条统一的感官总线。视觉、听觉与文本信息都能在同一个语义空间中进行关联、比较和推理,这为未来Agent真正理解屏幕、理解环境并自主操作电脑,奠定了最重要的语义基础。
背后的技术与应用
在技术层面,Gemini Embedding 2继续采用了Matryoshka Representation Learning(MRL) 方法。

这种方法允许嵌入向量在保持核心语义信息的同时进行动态维度缩减。它强制模型将最关键的特征压缩在向量的前几十维,次要特征放在后面。开发者可以根据实际的计算预算和存储成本,自由选择使用不同维度的向量(例如3072维、1536维或768维),从而实现性能与成本之间的平衡。
Gemini Embedding 2的默认输出维度为3072维。除了直接通过API调用外,该模型也支持通过LangChain、LlamaIndex、Haystack、Weaviate、Qdrant、ChromaDB等主流工具和向量数据库进行集成与调用。
通过为不同类型的数据赋予统一、可比的语义表示,Gemini Embedding 2正在为下一代AI应用——包括多模态Agent乃至具身智能机器人——构建关键的基础设施。
参考链接
[1]https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-embedding-2/
[2]https://arxiv.org/pdf/2503.07891
关于多模态嵌入技术如何具体应用于 RAG 和 Agent 开发,欢迎到 云栈社区 的技术讨论板块分享你的见解或提出疑问。
 发表于 2026-3-12 09:40:38
|
查看: 145|
回复: 0
发表于 2026-3-12 09:40:38
|
查看: 145|
回复: 0
