最近在网上看到一个帖子,味儿一下子就冲上来了:有人月薪实际不到1万,面试时却一口气报成了2万5,试图把最终报价抬到3万。结果刚入职,就被HR拿着薪资流水“当场验明正身”,面临被开除的局面。
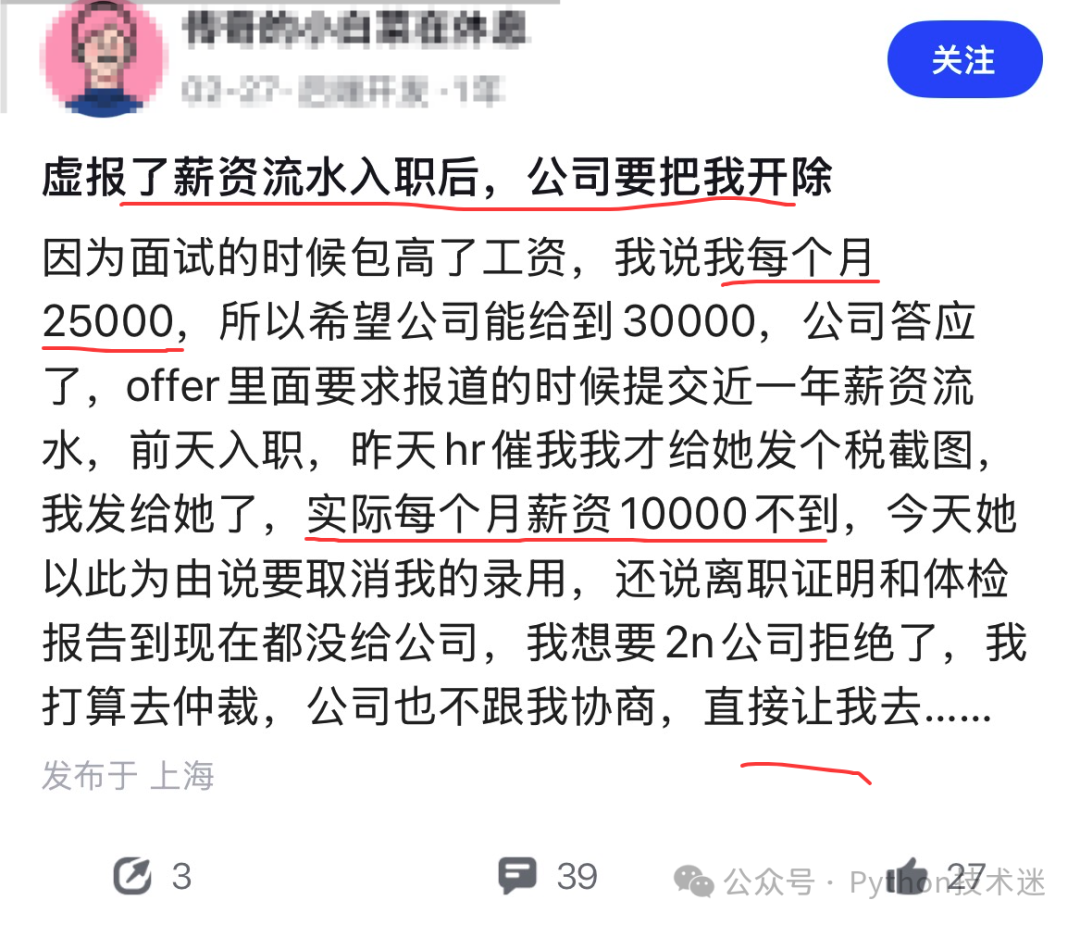
有网友评论得很直接:你这不叫谈薪,是开盲盒,结果开出来吓到了自己。也有人补刀:公司翻脸是快,可你这数字吹得也确实有点离谱。
站在面试求职和诚信的角度看,虚报流水无疑是自己埋下的雷。公司以此为由取消录用,虽然显得不近人情,但在规则上并非毫无依据。这件事也给广大求职者提了个醒:薪资谈判可以谈预期、谈能力价值,但硬性证明材料最好实事求是。
抛开职场八卦,作为一名开发者,我更习惯把复杂问题抽象成代码逻辑来思考。下面,就结合一道经典的算法/数据结构题目——“最大整除子集”,来看看如何用清晰的思路解决看似棘手的问题。
算法题:最大整除子集
这题我第一次看到时,直觉是回溯。毕竟题目要的是一个“子集”,很容易往“选或者不选”的思路上靠。但真动手写会发现,回溯虽然可行,一旦数据量变大,效率就会急剧下降。这道题真正顺手的解法,还得是动态规划。
题目描述(LeetCode 368):给你一组互不相同的正整数 nums,找出并返回其中最大的子集 answer,使得子集中的任意两个元素 (answer[i], answer[j]) 都满足:answer[i] % answer[j] == 0,或者 answer[j] % answer[i] == 0。如果存在多个有效子集,返回其中任何一个即可。
先看一个简单的例子,[1,2,3],结果可以是 [1,2],也可以是 [1,3]。因为 2 和 3 互相不能整除,所以它们不能同时存在于同一个合法子集中。
解决这道题,有一个非常关键的前置动作:先排序。排序之后,如果我们想判断 nums[i] 能否加入一个以 nums[j] 结尾的合法子集,就只需要检查 nums[i] % nums[j] == 0(其中 i > j)。这样一来,问题就巧妙地转化为了:以 nums[i] 结尾的最大整除子集长度是多少。这是一个典型的序列型动态规划问题。
我的思路是,用一个 dp 数组记录长度,再用一个 prev 数组来还原路径。以下是具体的 Python 实现:
def largestDivisibleSubset(nums):
if not nums:
return []
nums.sort()
n = len(nums)
dp = [1] * n # dp[i] 表示以 nums[i] 结尾的最大长度
prev = [-1] * n # 记录路径,方便最后倒着还原答案
best_len = 1
best_idx = 0
for i in range(n):
for j in range(i):
if nums[i] % nums[j] == 0 and dp[j] + 1 > dp[i]:
dp[i] = dp[j] + 1
prev[i] = j
if dp[i] > best_len:
best_len = dp[i]
best_idx = i
ans = []
while best_idx != -1:
ans.append(nums[best_idx])
best_idx = prev[best_idx]
return ans[::-1]
代码的核心是两层循环。外层枚举当前的数字 nums[i],内层遍历它之前的所有数字 nums[j]。如果 nums[i] 能被 nums[j] 整除,并且接在 j 后面能形成更长的链,那么就更新 dp[i] 和记录前驱节点的 prev[i]。
举个例子,对于输入 [1, 2, 4, 8]:
print(largestDivisibleSubset([1, 2, 4, 8]))
输出是 [1, 2, 4, 8],这是一个完美的整除链。
再看一个稍复杂的例子 [3, 4, 16, 8],排序后是 [3, 4, 8, 16]:
print(largestDivisibleSubset([3, 4, 16, 8]))
最终会得到 [4, 8, 16]。注意,虽然 16 也能被 4 整除,但 3 无法与 4、8、16 中的任何一个构成整除关系,因此最长的链是 4 -> 8 -> 16。
这里有一个重要的细节需要理解:题目要求子集中“任意两个数”满足整除关系,为什么我们在动态规划转移时,只需要判断当前数 nums[i] 和前一个数 nums[j] 的关系就够了?
关键在于排序和整除的传递性。假设我们有一条已经合法的链:a -> b -> c,且满足 b % a == 0 和 c % b == 0。由于整除的传递性(c 是 b 的倍数,b 是 a 的倍数,那么 c 也一定是 a 的倍数),自然就有 c % a == 0。所以,只要保证在构建链时,每一个新加入的元素都能整除它紧邻的前一个元素(在排序后的数组中,实际上是它的某个前驱),那么整条链就一定满足“任意两数整除”的条件。
这个解法的时间复杂度是 O(n^2),空间复杂度是 O(n)。对于面试或日常刷题,这个复杂度通常是可以接受的。一开始不必纠结于复杂的剪枝或回溯优化,那样很容易让代码变得冗长且难以解释。
我在解这道题时,真正的卡点不是动态规划的状态定义,而是如何还原出具体的子集。很多人能把 dp 数组计算正确,但最后只能返回最大长度,拿不到那个具体的集合。这时候,增加一个 prev 数组来记录转移路径就非常巧妙,最后从最长链的末尾(best_idx)开始,沿着前驱指针一路回溯,就能得到整个子集,最后别忘了反转一下顺序。
我们可以写个简单的测试来验证:
cases = [
[1, 2, 3],
[1, 2, 4, 8],
[3, 4, 16, 8],
[5, 9, 18, 54, 108]
]
for arr in cases:
print(arr, "->", largestDivisibleSubset(arr))
这道题不算特别难,但它非常经典,很适合用来练习“排序 + 动态规划 + 路径还原”这一套组合拳。在面试中如果能清晰地将这个思路表达和实现出来,通常能很好地体现你的逻辑和编码能力。
从虚报薪资的职场困境,到最大整除子集的算法求解,看似不相关的两件事,背后其实都关乎“规则”与“逻辑”。在职场上,诚信是基本规则;在代码世界,严谨的逻辑是解决问题的基石。希望这篇杂谈与技术讲解的结合,能给你带来一些不同的思考。如果你对这类算法问题或职场话题有更多想法,欢迎到云栈社区与我们交流。
 发表于 2026-3-12 09:42:41
|
查看: 207|
回复: 0
发表于 2026-3-12 09:42:41
|
查看: 207|
回复: 0
