上周,Fish Audio 正式开源了其 S2 版本的文本转语音模型。相比于之前的版本,S2 在生成速度、音质效果以及情感控制方面都有显著提升。因为我之前在本地实时互动数字人产品中一直使用其1.5版本的模型,所以对这次更新一直很期待。之前使用的是 Windows 版本,总感觉功能上有所限制。这次我决定利用 WSL(Windows Subsystem for Linux)的方式在 Linux 环境下安装它,看看效果究竟如何。
项目地址:https://github.com/fishaudio/fish-speech
在线体验:https://fish.audio/s2/
生成效果示例
以下是一些带有情感标记的文本,经 S2 模型合成后的语音效果非常生动:
小小的兔子窝里,[超级开心] 今天是我的生日![兴奋地跳起来]
森林里的朋友们都来了,[笑着] 他们带来了好多礼物!
看啊,[惊喜] 一篮红红的胡萝卜![开心大笑] 还有闪闪发光的胡萝卜蛋糕!
[温柔地] 谢谢大家,[语气温暖] 我们一起唱生日歌吧~
[突然大喊] 许愿!吹蜡烛![超级兴奋] 呼~我的愿望是:每天都这么快乐!
哇![好奇惊讶] 海底世界好神奇![兴奋]
小鱼儿在跳舞,海星在眨眼,[开心笑] 还有会唱歌的海螺!
[勇敢地] 别怕,我们继续往前游![语气坚定]
突然——[惊讶大叫] 一只大章鱼伸出手臂!
[调皮地] 它其实想和我们玩捉迷藏呢![大笑]
[超级开心] 耶!今天是最棒的冒险日!
我是一朵小小的花,[害羞低声] 总是躲在叶子后面。[小声叹气]
太阳公公说:[鼓励] 孩子,勇敢抬头看看天空吧!
[慢慢自信] 我试着伸展花瓣……[惊喜] 哇,好温暖!
[开心绽放] 蝴蝶来了!蜜蜂来了![自豪地] 现在我是一朵最漂亮的花啦~
[温柔感谢] 谢谢阳光,谢谢雨水,[幸福地] 我终于开心地盛开了!
更新亮点
- 首包延迟极低:可以做到约 100ms,这意味着几乎在你话音刚落时,语音回复就能开始生成,非常适合实时对话场景。
- 精细化情感控制:模型能更好地理解并模拟人类情绪。你可以在输入文本中直接加入自然语言描述,例如“小声说”、“笑着说”、“压低声音”等,这使得生成的语音更加灵活自然。更重要的是,它能理解上下文,知道在什么地方应该轻笑一声,什么地方应该放低音量,更具人情味。
- 高效的多说话人合成:只需上传一段包含多位说话人的参考音频,模型通过内置的
<|speaker:i|> token 就能自动提取并区分每位说话人的声学特征。单次推理即可生成完整的多人对话音频,无需再为每个角色单独准备和上传音频样本。
WSL 安装步骤详解
这是我第一次使用 WSL 方式部署,因此记录下详细步骤,也方便日后回顾。事实上,Fish-Speech 官方也更推荐使用 Linux 或 WSL 环境。
前提条件:确保你已在 Windows 上安装了最新的 NVIDIA 显卡驱动。
步骤 1:启用并安装 WSL2(如果尚未安装)
- 以管理员身份打开 PowerShell,执行 WSL 安装命令。
wsl --install
- 设置 WSL 默认版本为 2。
wsl --set-default-version 2
- 安装 Ubuntu 24.04 发行版。
wsl --install -d Ubuntu-24.04
- 进入 WSL 的 Ubuntu 环境。
wsl -d Ubuntu-24.04
# 或者直接在开始菜单搜索 “Ubuntu” 并打开
步骤 2:在 WSL 中安装基本依赖
进入 WSL 的 Ubuntu 终端后,执行以下命令安装必要的基础软件包。
sudo apt update && sudo apt upgrade -y
sudo apt install -y git build-essential python3 python3-pip python3-venv ffmpeg libsndfile1 portaudio19-dev libsox-dev
步骤 3:安装 Miniconda(强烈推荐,便于管理 Python 和 CUDA 环境)
使用 Conda 可以避免系统 Python 环境冲突,是管理 开源实战 项目依赖的利器。
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh -b -p $HOME/miniconda
~/miniconda/bin/conda init
执行后关闭并重新打开终端,使 Conda 初始化生效。
步骤 4:创建 Conda 环境并安装 Fish Speech
- 创建一个新的 Conda 环境。
conda create -n fish-speech python=3.10 -y
conda activate fish-speech
- 根据你的 CUDA 版本安装 PyTorch(通过
nvidia-smi 命令查看 CUDA Version)。
# 根据你的 CUDA 版本选择(查看 nvidia-smi)
# 常见选项:cu121 / cu124 / cu128 / cu129 等
# 以 CUDA 12.8 为例(2025-2026 大多数 40/50 系显卡推荐)
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu128
- 克隆 Fish Speech 项目仓库并安装依赖。
git clone https://github.com/fishaudio/fish-speech.git
cd fish-speech
# 安装依赖(最重要的一步)
pip install -e .[stable]
# 如果你不需要 compile 加速(最常见情况),上面就够了
# 如果要 compile,需要额外装 triton(Windows/WSL 有时很麻烦,不推荐初次尝试)
步骤 5:下载模型权重
进入项目目录,使用 huggingface-cli 从 HuggingFace 下载模型。你可以选择一个合适的模型进行测试。
# 进入项目目录
cd ~/fish-speech # 假设你克隆在 home 目录下
# 下载一个较小的模型用于测试(例如 Fish-Speech-2)
huggingface-cli download fishaudio/fish-speech-2 --local-dir checkpoints/fish-speech-2
# 或者下载最新的 S2-pro(需要更大显存)
# huggingface-cli download fishaudio/s2-pro --local-dir checkpoints/s2-pro
步骤 6:启动 WebUI(最常用的交互方式)
在 Conda 环境激活的状态下,运行以下命令启动 Web 界面。你需要将路径替换为你实际存放模型的位置。
python tools/run_webui.py --llama-checkpoint-path /mnt/g/FishModels/checkpoints/fish-speech-2 --decoder-checkpoint-path /mnt/g/FishModels/checkpoints/fish-speech-2/codec.pth --decoder-config-name firefly_gan_vq --half --compile
小提示:
- 如果遇到显存不足的问题,可以尝试使用更小的模型,或者确保添加了
--half 参数使用半精度推理。
- WSL 中访问 Windows 文件系统:路径
/mnt/c/ 对应 Windows 的 C 盘,以此类推。
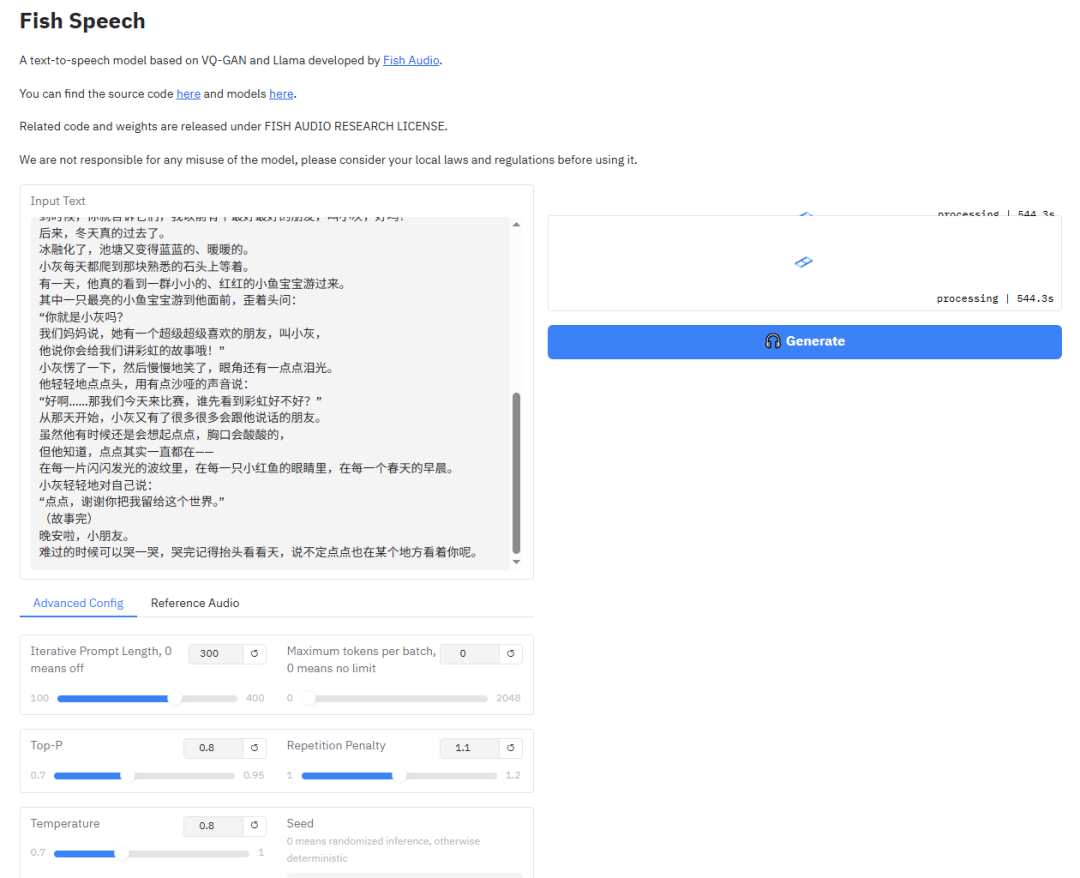
安装与管理技巧
将 WSL 安装到非系统盘
如果你的系统盘空间紧张,可以将 WSL 发行版安装到其他磁盘。
mkdir G:\WSL\Ubuntu-24.04
wsl --install -d Ubuntu-24.04 --location G:\WSL\Ubuntu-24.04
//验证位置
wsl -l -v
迁移已安装的 WSL 到其他盘
如果已经安装,也可以进行迁移。
wsl --shutdown
mkdir G:\WSL\Ubuntu-24.04
wsl --export Ubuntu-24.04 G:\WSL\Ubuntu-24.04\backup.tar
wsl --unregister Ubuntu-24.04
wsl --import Ubuntu-24.04 G:\WSL\Ubuntu-24.04 G:\WSL\Ubuntu-24.04\backup.tar --version 2
wsl -d Ubuntu-24.04
后续启动命令
安装完成后,每次使用需要按顺序执行以下命令:
- 启动 WSL 并进入 Ubuntu。
- 激活 Conda 环境。
- 启动 Fish Speech WebUI。
为了方便,你可以将以下命令保存为一个脚本。
wsl -d Ubuntu-24.04
cd ~/fish-speech
conda activate fish-speech
PYTHONUNBUFFERED=1 python -u tools/run_webui.py --llama-checkpoint-path /mnt/g/FishModels/checkpoints/fish-speech-2 --decoder-checkpoint-path /mnt/g/FishModels/checkpoints/fish-speech-2/codec.pth --decoder-config-name modded_dac_vq --half --device cuda --compile
执行成功后,WebUI 将默认运行在 7860 端口,你可以在浏览器中通过 http://localhost:7860 访问。
另一款开源 TTS 简介:Hume AI TADA
除了 Fish Audio,近期 Hume AI 也开源了其 TADA 语音模型。它采用了创新的文本-声学双流对齐架构,打破了传统 TTS 的固定帧率限制,通过 1:1 的 Token 对齐机制,能在一个自回归步内动态生成完整的语音片段,显著提升了推理效率。
核心亮点:
结语与资源
目前,S2 的 4B 参数模型在我的 RTX 3070 显卡上进行实时对话推理仍有些迟缓,因此暂时没有集成到我现有的实时互动数字人系统中。后续会持续关注其优化进展。现阶段,CosyVoice2 和 Qwen3-TTS 已经能够满足大部分需求。
为方便大家快速上手,这里提供了整合好的模型安装包,包含文中提到的必要组件,可节省大量下载和配置时间。详细的部署步骤和故障排查,你也可以在 云栈社区 的技术文档板块找到更多参考资料。
模型安装包获取:https://pan.quark.cn/s/9d0da3c53395
希望这篇详细的 TTS 部署教程能帮助你顺利运行 Fish-Audio S2,体验下一代语音合成的魅力。
 发表于 2026-3-16 02:05:50
|
查看: 458|
回复: 0
发表于 2026-3-16 02:05:50
|
查看: 458|
回复: 0
