Karmada 是一个开放的多云多集群容器编排引擎,旨在帮助用户在多云环境下轻松部署和运维业务应用。凭借对 Kubernetes 原生 API 的完全兼容能力,Karmada 可以让单集群工作负载实现平滑迁移,并且依然能与丰富的 Kubernetes 周边生态工具链无缝协同。

Karmada v1.17[^1] 版本现已正式发布!这个版本带来了数项重要更新,帮助用户应对更复杂的 多集群管理 场景:
- 工作负载亲和与反亲和调度
- Dashboard v0.3.0 发布
- 持续的性能优化
这些新特性让 Karmada 在处理大规模、拓扑关系复杂的多集群部署时变得更加成熟和可靠。我们推荐您尽快升级到 v1.17.0,亲自体验这些功能带来的实际价值。对这类多云多集群技术的深入探讨,欢迎访问 云栈社区 与更多开发者交流。
新特性概览
支持工作负载亲和与反亲和调度
在多集群的实际生产环境中,许多应用对于工作负载之间的部署位置有明确要求。无论是为了实现高可用、降低跨集群访问延迟,还是为了优化成本与运维隔离,都需要更精细的调度控制。为了满足这类需求,v1.17 版本正式引入了工作负载亲和与反亲和调度能力,让你可以精准定义工作负载在多集群间的拓扑关系。
工作负载亲和(Workload Affinity)
这项功能旨在将存在紧密关联的工作负载(例如一个微服务与其专用的缓存组件,或一个分布式训练任务的各个部分)调度到同一个集群内。
- 核心价值:极大减少跨集群网络通信带来的延迟,对性能敏感型应用(如AI训练、实时数据处理)的效率提升尤为显著。
- 典型场景:核心服务与其依赖的数据库/缓存同集群部署;分布式计算任务的各个子任务就近调度。
工作负载反亲和(Workload Anti-Affinity)
与亲和性相反,反亲和性要求将同一逻辑组内的工作负载尽可能分散到不同的集群。
- 核心价值:避免因单个集群发生故障而导致整个关键服务不可用,从而构建更强的跨集群高可用保障。
- 典型场景:核心业务服务的多副本跨集群容灾部署;同一应用的不同实例分散部署以实现地域隔离。
使用方式
配置起来非常简便,只需在 PropagationPolicy 的 placement 字段下添加 workloadAffinity 配置项。调度器会根据你在资源模板(如 Deployment、Job)上定义的特定标签来识别“亲和组”,进而实现工作负载的“抱团”或“分散”。
下面来看一个工作负载亲和性的具体例子。假设你有一组关联紧密的机器学习训练任务,为了获得最佳性能,你希望这组任务的所有 Pod 都在同一个集群内运行。你可以通过以下 PropagationPolicy 来实现:
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: training-tasks-affinity-example
namespace: default
spec:
resourceSelectors:
- apiVersion: batch/v1
kind: Job
labelSelector:
matchLabels:
workload.type: training
placement:
spreadConstraints:
- maxGroups: 1
minGroups: 1
clusterAffinity:
clusterNames:
- member1
- member2
- member3
workloadAffinity:
affinity:
groupByLabelKey: app.training-group
启用该功能后,Karmada 调度器会自动将所有具有相同 app.training-group 标签值的训练任务 Job,调度到同一个成员集群上。
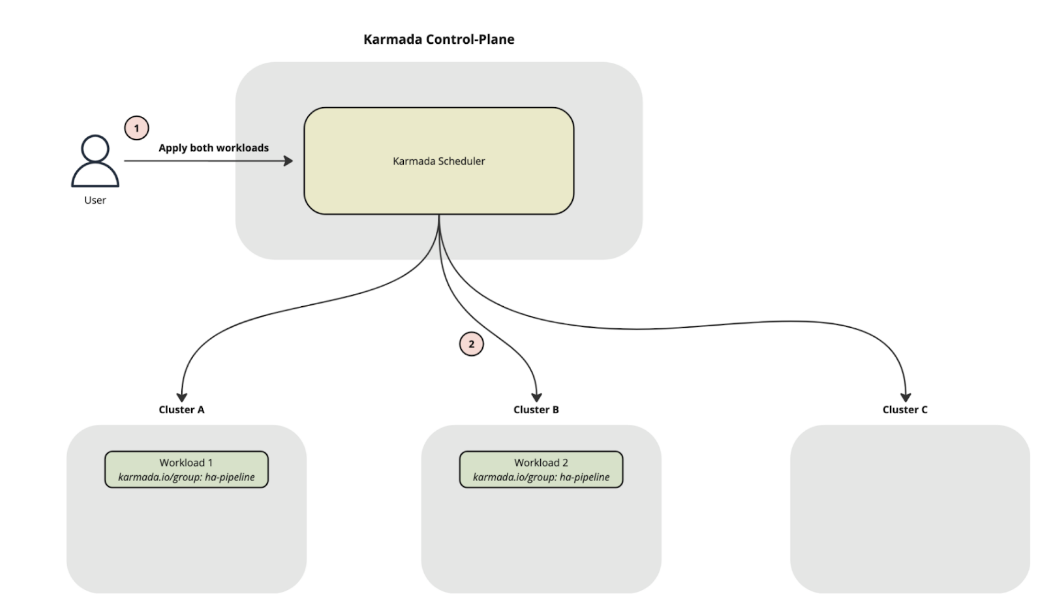
再来看一个工作负载反亲和性的例子。假设你运行着对停机时间零容忍的 Flink 流处理任务,并部署了多个副本来保证高可用。为了防止单个集群故障导致服务完全中断,你需要让同一任务的多个副本运行在不同的集群上。配置如下:
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: flink-anti-affinity-example
namespace: default
spec:
resourceSelectors:
- apiVersion: flink.apache.org/v1beta1
kind: FlinkDeployment
labelSelector:
matchLabels:
ha.enabled: “true”
placement:
spreadConstraints:
- maxGroups: 1
minGroups: 1
clusterAffinity:
clusterNames:
- clusterA
- clusterB
- clusterC
workloadAffinity:
antiAffinity:
groupByLabelKey: karmada.io/group
配置生效后,Karmada 会将所有带有相同 karmada.io/group 标签值的 Flink 任务副本,尽可能地调度到不同的集群中,其调度效果如下图所示:
更多关于此功能的详细说明和用例,请参考官方文档:工作负载亲和性调度[^2]。
Dashboard v0.3.0 发布
Karmada Dashboard 是一款为 Karmada 量身定制的图形化管理工具,它的目标是让复杂的多集群运维工作变得更简单直观。用户可以通过它实时查看集群状态、监控资源分布、管理策略,从而大幅提升管理效率。
经过社区开发者的持续投入,Karmada Dashboard v0.3.0 现已发布!这个版本带来了智能助手、增强的成员集群管理等重磅功能,标志着多集群运维体验迈上了一个新台阶——更易用、更稳定、更智能。
Karmada Dashboard v0.3.0 主要更新包括:
- 智能化运维:深度集成 MCP (Model Context Protocol) 与大语言模型 (LLM),推出了智能聊天助手。支持使用自然语言进行交互,并能实时响应和扩展工具能力,让多集群管理变得前所未有的智能。
- 成员集群管理能力增强:新增了专为成员集群设计的仪表盘,支持实时查看 Pod 日志和通过 Web Terminal 与集群进行交互,实现了对子集群的精细化管控。
- 界面优化:前端框架升级至 React 19,并采用了更现代化的 Ant Design v6 组件库,界面视觉更加美观。同时对数据请求和构建性能进行了优化,提升了交互流畅度与运行效率。
- 安全性和稳定性增强:引入了端到端 (E2E) 测试框架来保障核心功能的稳定性,并自动升级相关安全依赖,有效降低了潜在的安全风险。
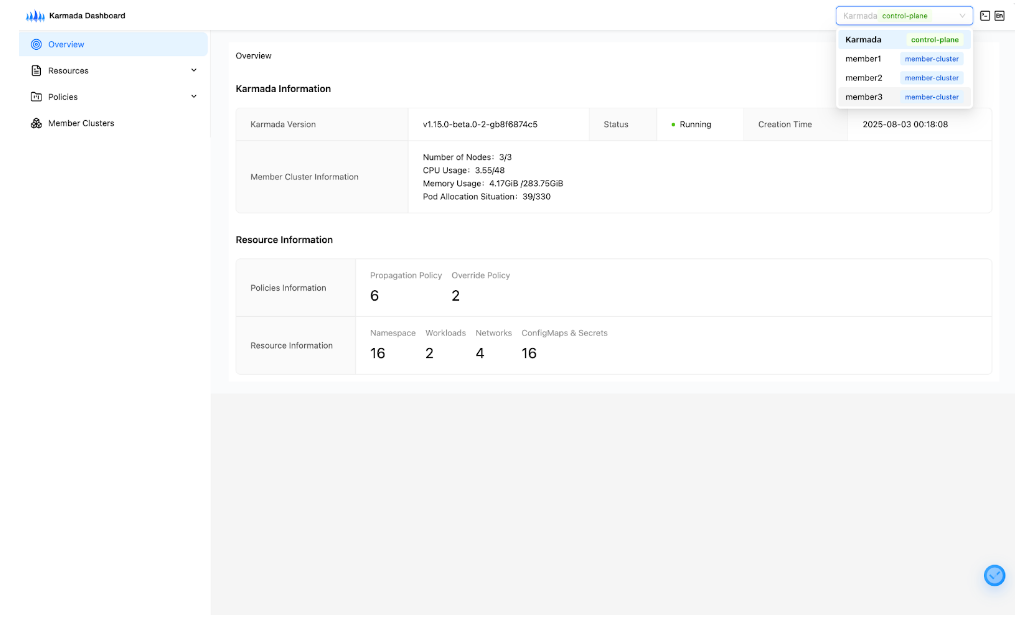
下图展示了 Karmada Dashboard v0.3.0 的新版界面。注意顶部导航栏,现在可以一键切换不同的成员集群,实现控制面与成员集群间的无缝视角切换:
有关 Karmada Dashboard 的安装和使用详情,请访问其项目仓库:Karmada Dashboard[^3]。
持续的性能优化
在 v1.17 版本中,性能优化工作仍在稳步推进。团队对控制器的核心机制进行了重要改进,以提升系统在大规模场景下的响应能力。
控制器优先级队列(ControllerPriorityQueue)特性升级至 Beta 并默认启用
控制器优先级队列特性自 v1.15 版本引入后,经过两个版本的持续打磨和严格测试,其稳定性和效果已得到充分验证。本次版本正式将其升级为 Beta 阶段,并默认启用。
该特性的核心价值在于,当 Karmada 控制器因重启或主备切换等原因需要重新协调资源状态时,能够立即响应并优先处理用户主动触发的资源变更操作。这显著缩短了服务重启或计划性维护升级过程中可能出现的业务中断时间。
依赖资源分发能力性能优化
本次优化重点解决了在并发更新由依赖资源(如 ConfigMap、Secret)产生的 ResourceBinding 时,可能出现的 API 冲突问题。通过优化更新机制,依赖资源跟随主工作负载分发的效率得到了大幅提升。
在一个包含 30,000 个 Workload 及其 PropagationPolicy,以及 30,000 个作为依赖的 ConfigMap 的测试环境中,此项优化将控制器首次启动后的队列处理时间从原来的 20 分钟以上 缩短至 约 5 分钟。这对于拥有海量资源的大规模集群而言,意味着系统响应速度的质的飞跃。
有关此项性能优化的详细技术内容和完整测试报告,请查阅相关 Pull Request: [Performance] optimize the mechanism of create or update dependencies-distribute resourcebinding[^4]。
致谢贡献者
Karmada v1.17 版本的顺利发布,离不开社区开发者的辛勤付出。本版本共包含了来自 32 位贡献者 的 264 次代码提交,在此向所有贡献者表示由衷的感谢(排名不分先后):
| @7h3-3mp7y-m4n |
@Abhay349 |
@abhinav-1305 |
| @AbhinavPInamdar |
@Ady0333 |
@Aman-Cool |
| @Arhell |
@arnavgogia20 |
@CharlesQQ |
| @cmontemuino |
@dahuo98 |
@FAUST-BENCHOU |
| @gmarav05 |
@goyalpalak18 |
@jabellard |
| @kajal-jotwani |
@LivingCcj |
@mohamedawnallah |
| @mszacillo |
@RainbowMango |
@rayo1uo |
| @seanlaii |
@SunsetB612 |
@suresh-subramanian2013 |
| @vie-serendipity |
@warjiang |
@XiShanYongYe-Chang |
| @yaten2302 |
@yoursanonymous |
@zach593 |
| @zhengjr9 |
@zhzhuang-zju |
|
感谢每一位参与者的智慧与汗水!🎉

相关链接
[^1]: Karmada v1.17 变更日志: https://github.com/karmada-io/karmada/blob/master/docs/CHANGELOG/CHANGELOG-1.17.md
[^2]: 工作负载亲和性调度: https://karmada.io/zh/docs/next/userguide/scheduling/propagation-policy/#workloadaffinity%E5%B7%A5%E4%BD%9C%E8%B4%9F%E8%BD%BD%E4%BA%B2%E5%92%8C%E6%80%A7
[^3]: Karmada Dashboard: https://github.com/karmada-io/dashboard
[^4]: [Performance] optimize the mechanism of create or update dependencies-distribute resourcebinding: https://github.com/karmada-io/karmada/pull/7153

关于 Karmada
Karmada 是 CNCF 首个多云多集群容器编排项目(孵化级),旨在让用户能够像管理单个 Kubernetes 集群一样轻松地管理遍布多个云上的多个集群,帮助基于 Karmada 的多云方案无缝融入云原生技术生态。社区已吸引了来自华为、道客、浙江大学、腾讯、中国电子云、滴滴、Zendesk、携程等上百家公司和机构的全球贡献者,广泛分布于 20 多个国家和地区。目前,Karmada 已在华为云、道客、兴业数金、中国移动、中国联通、携程、360集团、新浪、中通快递等众多企业单位的生产环境中得到应用,为企业提供了从单集群到多云混合架构的平滑演进方案。
 发表于 2026-3-16 07:25:43
|
查看: 165|
回复: 0
发表于 2026-3-16 07:25:43
|
查看: 165|
回复: 0
