本文将通过一个基于ARM裸机开发的简单实例,为你详细剖析一段C语言中的for循环代码,最终被编译器翻译成了怎样的ARM汇编指令。理解这一过程,对于深入掌握计算机基础原理和进行底层调试至关重要。
1. 示例C代码
我们从一个非常简单的C语言程序开始,它的功能是计算从0到100的累加和。
/*
* main.c
*
* Created on: 2025-11-26
* Author: pengdan
*/
int main(void)
{
int i = 0;
int sum = 0;
for(i=0; i<=100; i++)
{
sum+=i;
}
return 0;
}
代码逻辑清晰:定义两个整型变量i和sum,然后通过一个for循环,将i从0递增到100,并将每一步的i累加到sum中。
2. 编译与反汇编
我们使用ARM交叉编译工具链进行编译。下图展示了在Ubuntu终端中执行make命令的过程:
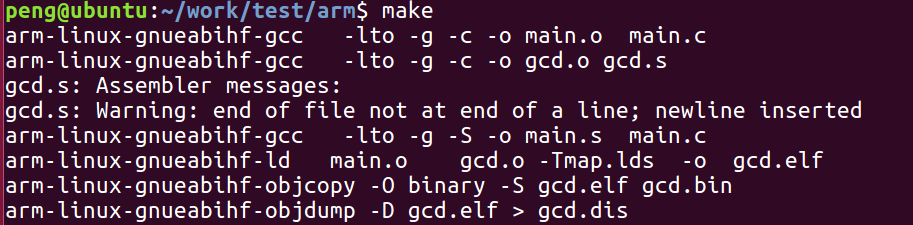
编译最终会生成可在ARM板子上运行的gcd.bin文件。为了方便分析,我们使用arm-linux-gnueabihf-objdump工具对生成的ELF文件进行反汇编,剥离符号信息,得到可读的汇编指令文件gcd.dis。
gcd.dis文件内容节选(.text段,main函数部分)如下:
gcd.elf: file format elf32-littlearm
Disassembly of section .text:
40008000 <_start>:
40008000: e3a0d207 mov sp, #1879048192 ; 0x70000000
40008004: ea00000d b 40008040 <__main_from_arm>
40008008 <main>:
40008008: b480 push {r7}
4000800a: b083 sub sp, #12
4000800c: af00 add r7, sp, #0
4000800e: 2300 movs r3, #0
40008010: 607b str r3, [r7, #4]
40008012: 2300 movs r3, #0
40008014: 603b str r3, [r7, #0]
40008016: 2300 movs r3, #0
40008018: 607b str r3, [r7, #4]
4000801a: e006 b.n 4000802a <main+0x22>
4000801c: 683a ldr r2, [r7, #0]
4000801e: 687b ldr r3, [r7, #4]
40008020: 4413 add r3, r2
40008022: 603b str r3, [r7, #0]
40008024: 687b ldr r3, [r7, #4]
40008026: 3301 adds r3, #1
40008028: 607b str r3, [r7, #4]
4000802a: 687b ldr r3, [r7, #4]
4000802c: 2b64 cmp r3, #100 ; 0x64
4000802e: ddf5 ble.n 4000801c <main+0x14>
40008030: 2300 movs r3, #0
40008032: 4618 mov r0, r3
40008034: 370c adds r7, #12
40008036: 46bd mov sp, r7
40008038: f85d 7b04 ldr.w r7, [sp], #4
4000803c: 4770 bx lr
...
接下来,我们逐部分分析这些汇编指令是如何对应到我们最初的for循环C代码的。
3. 汇编代码逐行分析
1)函数入口与栈帧建立
40008008 <main>:
40008008: b480 push {r7} ; 保存旧的帧指针r7
4000800a: b083 sub sp, #12 ; 在栈顶预留12字节空间
4000800c: af00 add r7, sp, #0 ; 设置新的帧指针r7指向当前栈顶
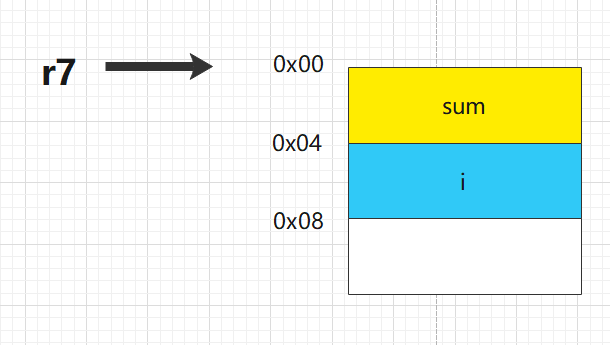
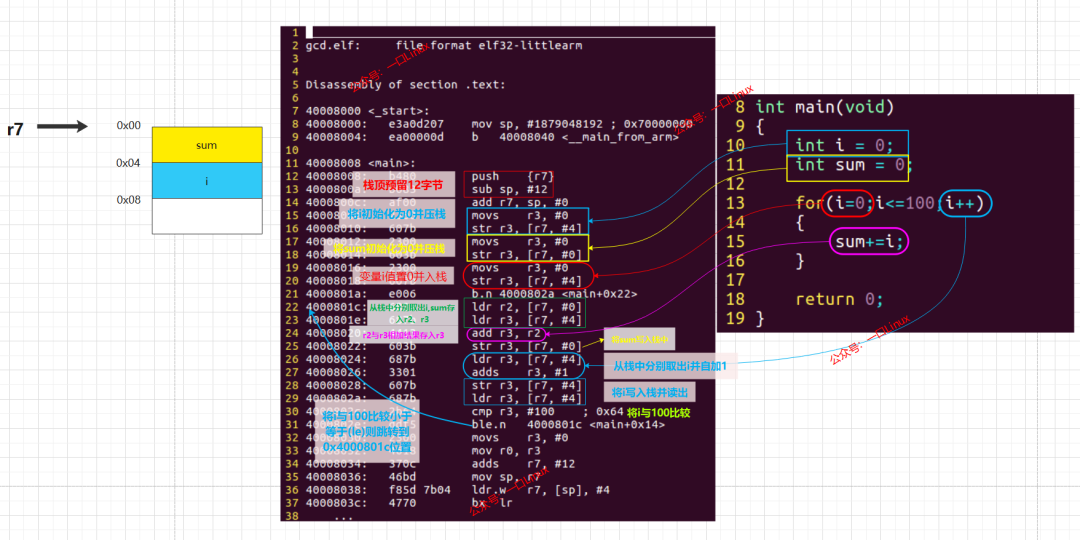
这几条指令是函数的标准开场白(prologue)。push {r7}将上一个函数的帧指针保存到栈中。sub sp, #12在栈上分配了12个字节的空间,这正好用于存放我们的两个整型变量i和sum(每个int在ARM架构下通常占4字节)以及一些对齐空间。随后add r7, sp, #0让寄存器r7指向这片新分配空间的起始地址,作为本函数的帧指针,方便后续通过它来访问局部变量。
此时,栈的布局如下图所示,r7指向地址0x00处,sum变量在[r7, #0],i变量在[r7, #4]:
2)变量初始化与循环主体
4000800e: 2300 movs r3, #0 ; r3 = 0
40008010: 607b str r3, [r7, #4] ; 将0存入 [r7+4],即 i = 0
40008012: 2300 movs r3, #0 ; r3 = 0
40008014: 603b str r3, [r7, #0] ; 将0存入 [r7+0],即 sum = 0
40008016: 2300 movs r3, #0 ; r3 = 0 (再次初始化i为0,对应for(i=0;...)
40008018: 607b str r3, [r7, #4] ; i = 0
4000801a: e006 b.n 4000802a <main+0x22> ; 无条件跳转到循环条件判断处
第15-18行对应int i=0; int sum=0;的初始化。有趣的是,编译器在19-20行又生成了一次i=0的指令,这对应了for(i=0; ...)中的初始化部分。然后第22行直接跳转(b.n)到地址4000802a,即循环条件判断的位置。这是一种常见的优化,让循环先进行条件检查。
循环体开始 (地址 4000801c):
4000801c: 683a ldr r2, [r7, #0] ; r2 = sum (从栈加载)
4000801e: 687b ldr r3, [r7, #4] ; r3 = i (从栈加载)
40008020: 4413 add r3, r2 ; r3 = r3 + r2 (即 r3 = i + sum)
40008022: 603b str r3, [r7, #0] ; sum = r3 (将结果存回sum)
这4条指令完美实现了循环体内的 sum += i; 操作:先分别加载sum和i到寄存器,相加,再存回sum。
循环步进 i++ (地址 40008024):
40008024: 687b ldr r3, [r7, #4] ; r3 = i
40008026: 3301 adds r3, #1 ; r3 = i + 1
40008028: 607b str r3, [r7, #4] ; i = r3 (i++)
这3条指令实现了for循环的第三部分i++:读i,加1,写回。
循环条件判断 (地址 4000802a):
4000802a: 687b ldr r3, [r7, #4] ; r3 = i (再次加载,用于比较)
4000802c: 2b64 cmp r3, #100 ; 比较 i 和 100
4000802e: ddf5 ble.n 4000801c <main+0x14> ; 如果 i <= 100,跳回循环体开始
这里是for循环的第二部分i<=100。cmp指令将i与立即数100比较,并设置处理器状态标志。ble.n(Branch if Less than or Equal)根据标志位判断,如果条件满足(i <= 100),则跳转回地址4000801c执行下一次循环;否则,顺序执行,循环结束。
下图清晰地展示了从C源码到汇编指令的对应关系,以及r7指向的栈内存如何被访问:
3)函数返回
40008030: 2300 movs r3, #0 ; r3 = 0 (返回值)
40008032: 4618 mov r0, r3 ; 将返回值放入r0 (ARM ABI规定)
40008034: 370c adds r7, #12 ; 恢复帧指针r7到分配前的状态
40008036: 46bd mov sp, r7 ; 恢复栈指针sp
40008038: f85d 7b04 ldr.w r7, [sp], #4 ; 从栈中弹出旧的帧指针到r7
4000803c: 4770 bx lr ; 跳转回调用者 (函数返回)
循环结束后,执行return 0;。将0放入返回值寄存器r0。随后是函数收尾工作(epilogue):调整r7和sp指针,回收栈空间,恢复旧的帧指针,最后通过bx lr指令返回。
4. 其他工程文件
为了保持文章的完整性和可复现性,这里也提供工程中的其他关键文件。
gcd.s (汇编启动文件)
.text
.global _start
_start:
ldr sp,=0x70000000 /*get stack top pointer*/
b main
Makefile
TARGET=gcd
TARGETC=main
all:
arm-linux-gnueabihf-gcc -lto -g -c -o $(TARGETC).o $(TARGETC).c
arm-linux-gnueabihf-gcc -lto -g -c -o $(TARGET).o $(TARGET).s
arm-linux-gnueabihf-gcc -lto -g -S -o $(TARGETC).s $(TARGETC).c
arm-linux-gnueabihf-ld $(TARGETC).o $(TARGET).o -Tmap.lds -o $(TARGET).elf
arm-linux-gnueabihf-objcopy -O binary -S $(TARGET).elf $(TARGET).bin
arm-linux-gnueabihf-objdump -D $(TARGET).elf > $(TARGET).dis
clean:
rm -rf *.o *.elf *.dis *.bin
map.lds (链接脚本)
OUTPUT_FORMAT(“elf32-littlearm”, “elf32-littlearm”, “elf32-littlearm”)
/*OUTPUT_FORMAT(“elf32-arm”, “elf32-arm”, “elf32-arm”)*/
OUTPUT_ARCH(arm)
ENTRY(_start)
SECTIONS
{
. = 0x40008000;
. = ALIGN(4);
.text :
{
gcd.o(.text)
*(.text)
}
. = ALIGN(4);
.rodata :
{ *(.rodata) }
. = ALIGN(4);
.data :
{ *(.data) }
. = ALIGN(4);
.bss :
{ *(.bss) }
}
总结
通过以上逐步分析,我们可以看到,一个高级语言中简洁的for循环,在底层被翻译成了一系列精细的汇编指令,包括:栈帧管理、内存访问(str/ldr)、算术运算(add)、条件比较(cmp)和流程跳转(b, ble)。理解这种对应关系,不仅能加深我们对计算机基础工作原理的认识,更是进行嵌入式系统调试、性能分析和编写高效代码的基石。希望这篇在云栈社区分享的解析能为你带来启发。
 发表于 2026-3-17 05:37:59
|
查看: 128|
回复: 0
发表于 2026-3-17 05:37:59
|
查看: 128|
回复: 0
