聊聊那 7 种你天天见、却未必都用过的结构体写法
翻一份 MCU 项目的源码,你会发现满屏都是 struct。寄存器是 struct,驱动是 struct,任务控制块是 struct,协议帧也是 struct。如果只把它理解成“把几个字段塞进一个盒子里”,那就太小看它了。
在嵌入式这种对内存布局、硬件时序、抽象层次都很敏感的场景里,结构体承担的角色其实非常像一门“微型面向对象”——它负责把硬件的形状、模块的接口、通信的协议、运行时的状态,全部组织起来。只不过它穿了一件很普通的 C 语言外衣,看起来朴实无华,用好了却非常厉害。
下面按照我自己在项目里用得最顺手的顺序,整理 7 种写法。每一种都给一张小图、一段示例,建议对着自己的工程对号入座。
这篇不打算从“什么是 struct”开始讲。默认你已经会定义、会用指针访问、知道有内存对齐这回事。重点是这些写法在真实工程里解决了什么问题,以及它们彼此之间的联系——搞清楚这一层,你对“好代码长什么样”的直觉,会比多啃半本语法书有用得多。
一、把硬件寄存器“画”成一张结构体
这是每个做 MCU 的人最早接触的用法,但不一定真正想清楚它为什么能跑。
CPU 眼里的外设,其实是一块从某个基地址开始、按字节排布的物理内存。比如某款 MCU 的 UART1 基地址是 0x4001_3800,往上每 4 个字节就是一个寄存器。那我们完全可以把这一串连续的寄存器,用一个结构体“画”出来:
typedef struct {
volatile uint32_t CR; // +0x00 控制寄存器
volatile uint32_t SR; // +0x04 状态寄存器
volatile uint32_t DR; // +0x08 数据寄存器
volatile uint32_t BRR; // +0x0C 波特率寄存器
} UART_TypeDef;
#define UART1 ((UART_TypeDef *)0x40013800UL)
// 用起来就像操作一个对象
UART1->BRR = 0x683;
UART1->CR |= (1U << 13); // 使能
UART1->DR = 'A';
示意图大致长这样:
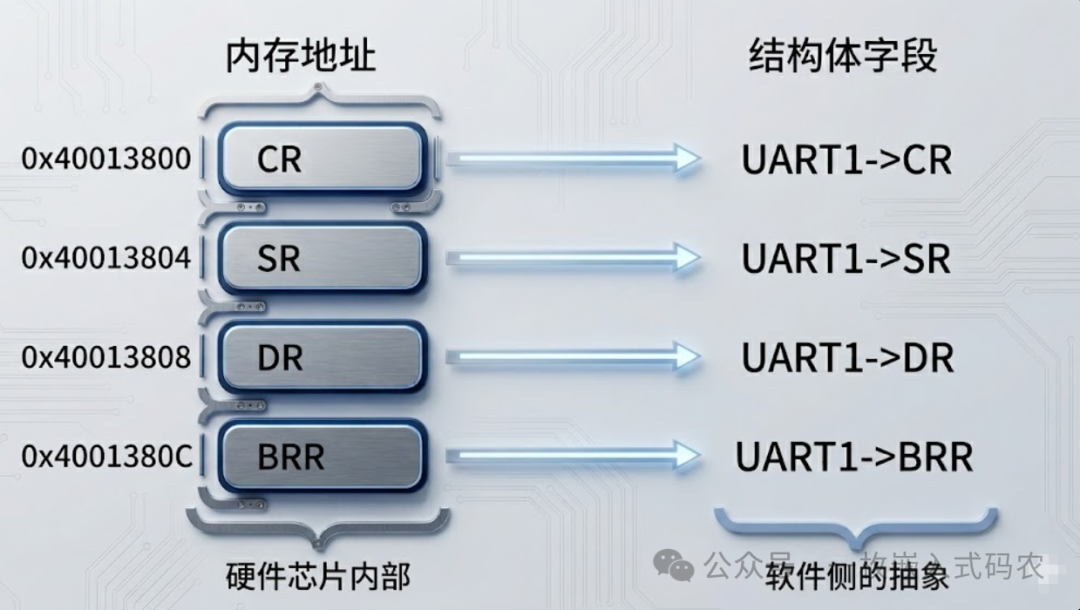
这里有三个细节值得琢磨:一是字段顺序必须严格对应寄存器手册,不能随便调换;二是 volatile 不能省,否则编译器可能把“读一次状态寄存器”优化成“读一次就缓存”;三是为什么用结构体而不是一堆 #define——因为结构体让寄存器之间的“归属关系”一眼就看得清楚,UART1 的事情就在 UART1 里,不会和 SPI1 串味。
这是结构体在嵌入式中的第一层价值:它让硬件的形状和代码的形状长得一模一样。
二、用函数指针把“接口”做出来
做嵌入式难免要接不同型号的传感器、不同厂家的 Flash、不同类型的通信芯片。如果每换一个器件就改一遍上层逻辑,代码很快就会烂。
这时候结构体 + 函数指针就是救星。核心思路只有一句话:把“数据”和“能对这个数据做什么”一起装进结构体里。
struct sensor; // 前向声明
typedef struct sensor_ops {
int (*init) (struct sensor *self);
int (*read) (struct sensor *self, float *value);
int (*sleep) (struct sensor *self);
} sensor_ops_t;
typedef struct sensor {
const char *name;
const sensor_ops_t *ops;
void *priv; // 各家传感器的私有参数
} sensor_t;
// 上层只认 sensor_t,不认具体型号
static inline int sensor_read(sensor_t *s, float *v) {
return s->ops->read(s, v);
}
温度、气压、IMU 各自实现一套 ops,对外暴露一个 sensor_t 变量就行。结构长这样:
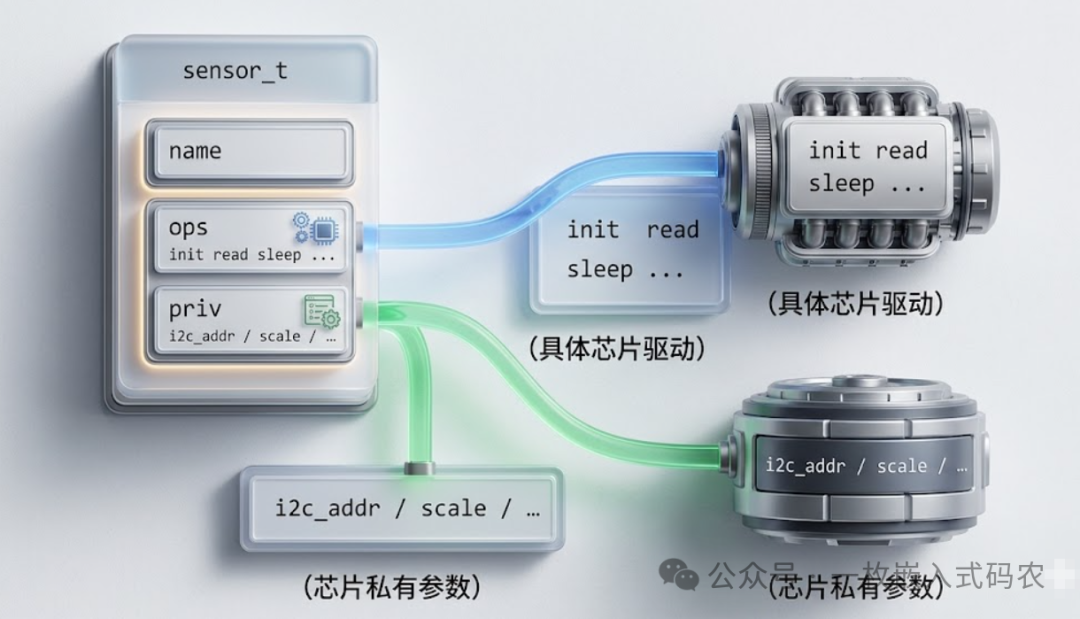
只要把这层接口抽稳,新加一种传感器,业务代码一行都不用改。这就是 C 语言版的“多态”——没有 class,也没有 virtual,但语义完全一致。
这里有个经常被忽略的细节:ops 最好声明成 const。函数指针表在编译期就已经写死,运行期没有任何理由去改它,放进只读段既安全又能省点 RAM。再进一步,priv 里放什么完全由具体驱动决定——I2C 地址、量程、滤波参数、校准系数,这些“芯片自己的事”统统塞进去,上层永远只看 sensor_t 这个“外壳”。有了这层分离,代码评审、单元测试、仿真替身 (mock) 都能做得很干净。了解了这种设计思路,你会发现它与那些成熟的 C/C++ 编程范式 中的 RAII 和面向接口编程思想不谋而合。
三、把一个状态机,凝固成一个结构体
嵌入式里状态机无处不在:按键消抖、充电管理、OTA 升级、协议握手……写着写着就会发现,状态机真正难的不是写 switch,而是“状态相关的数据”散落各处。
解决办法就是把状态、计时、上下文一并收进一个结构体里,让每个状态机都是一个独立的对象:
typedef enum {
ST_IDLE, ST_CONNECTING, ST_WORKING, ST_ERROR, ST_MAX
} state_t;
typedef struct fsm {
state_t cur;
uint32_t enter_tick; // 进入当前状态的时刻
uint8_t retry; // 重试计数
void *ctx; // 业务上下文
void (*on_event)(struct fsm *, uint8_t evt);
} fsm_t;
它的好处随手就能数出来:状态日志集中打印、超时判断只看 enter_tick、重试次数不用到处传参、多个并行的状态机之间互不干扰。
想再进一步,可以把“状态 × 事件 → 下一个状态”这张表也做成一个结构体数组:
typedef struct {
state_t from;
uint8_t event;
state_t to;
void (*action)(fsm_t *);
} transition_t;
static const transition_t g_table[] = {
{ ST_IDLE, EVT_START, ST_CONNECTING, do_connect },
{ ST_CONNECTING, EVT_CONNECTED, ST_WORKING, do_start_job },
{ ST_CONNECTING, EVT_TIMEOUT, ST_ERROR, do_log_fail },
{ ST_WORKING, EVT_STOP, ST_IDLE, do_cleanup },
};
整个状态机的逻辑,就会从“一堆 switch”变成“一张可读的表”。维护成本至少下降一半,而且很多时候还能把它直接从需求文档里的状态迁移表抄过来——产品、测试、开发三方看的是同一张表,沟通成本也跟着降下来。
四、柔性数组:让“一个消息”只 malloc 一次
只要项目里有任务间通信、有消息队列,就一定会遇到同一个问题——消息头是固定的,但数据是变长的。最笨的写法是结构体里放一个指针,再单独申请一块 buffer。结果是:两次 malloc、两次 free,少释放一次就是内存泄漏。
C99 给了一个更漂亮的办法,叫柔性数组:
typedef struct {
uint16_t msg_id;
uint16_t length; // 实际 payload 长度
uint32_t timestamp;
uint8_t payload[]; // 注意:不写长度
} msg_t;
// 一次申请:头部 + 数据 连续存放
msg_t *m = malloc(sizeof(msg_t) + data_len);
m->msg_id = MSG_SENSOR_DATA;
m->length = data_len;
memcpy(m->payload, src, data_len);
xQueueSend(q, &m, 0); // 扔给下一个任务
内存布局是连续的一块:
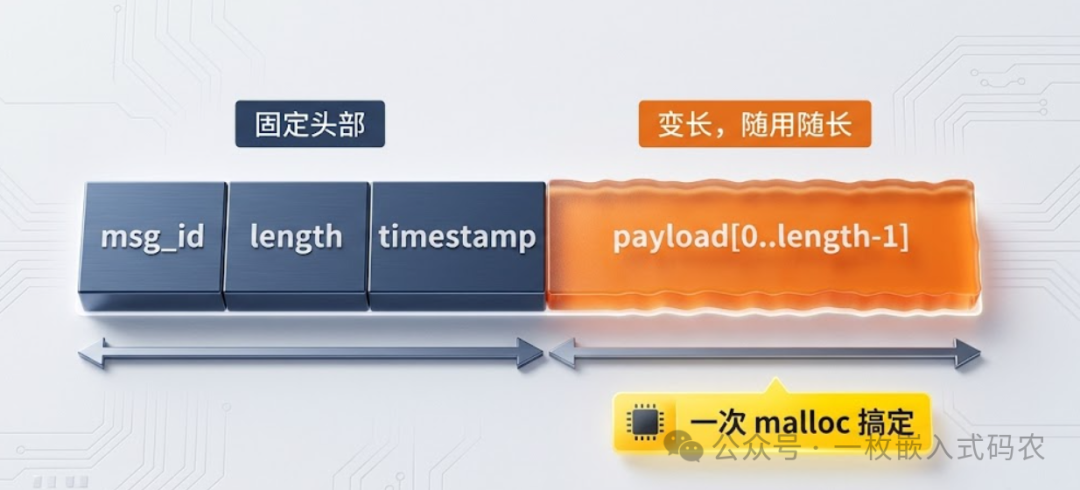
这一招对嵌入式特别合适:一次分配、一次释放、一次拷贝,队列里传递只需要传一个指针。如果再配合内存池(把几种常见大小的消息预先切好槽,运行期只做存取),基本就告别了堆碎片焦虑——很多 RTOS 里的 mail box、zero copy 队列,底层都是这个结构。涉及到系统级的内存管理策略,你可以进一步参考 后端架构设计 中关于高并发与内存优化的通用思路。
五、侵入式链表:一个对象挂进多条队列
做 RTOS 或自己搓一个任务调度器的人,一定会反复写链表。初学者常见的写法是:
typedef struct node {
void *data; // 指向真正的对象
struct node *next;
} node_t;
这种“外挂式”链表每多一条链表就要多一组节点,内存开销大、访问多一层间接。Linux 内核给了另一种更高级的写法——把链表节点直接嵌进对象里:
struct list_head {
struct list_head *next, *prev;
};
typedef struct task {
int id;
uint8_t prio;
struct list_head ready_node; // 可以挂进就绪队列
struct list_head delay_node; // 也能同时挂进延时队列
} task_t;
示意上看,一个对象自己“长”着若干根可以被串起来的小钩子:

反过来,从 list_head * 怎么找回所属的 task_t?靠大名鼎鼎的 container_of 宏,用字段偏移做指针减法就拿到了。看起来很唬人,拆开其实就两步:已知“嵌入字段的地址”和“这个字段在结构体里的偏移量”,两者一减,就是结构体起始地址。整个操作完全发生在编译期,不花一个 CPU 周期。
这样写出来的数据结构,复用性极强——同一个对象在不同时间段、不同子系统里,可以挂在不同的链上,而对象本身只在内存里存在一份。嵌入式设备资源紧张,能把“一份数据复用到多处”做到这种程度,对 RAM 和 Flash 的占用都非常友好。
六、协议帧:让一次 memcpy 就是一次解析
写串口、CAN、LoRa、蓝牙这些通信协议的时候,最烦的不是校验,而是“一个字节一个字节地挪”。如果把协议帧直接定义成结构体,很多脏活就可以消失。
#pragma pack(push, 1) // 关键:关闭填充
typedef struct {
uint8_t header; // 0xAA
uint8_t version;
uint16_t cmd;
uint16_t length;
uint8_t payload[256];
uint16_t crc;
} frame_t;
#pragma pack(pop)
// 收到完整一帧后,直接投射过去
frame_t *f = (frame_t *)rx_buf;
if (f->header == 0xAA && check_crc(f)) {
dispatch(f->cmd, f->payload, f->length);
}
对比一下“手动解析”就知道省了多少事:
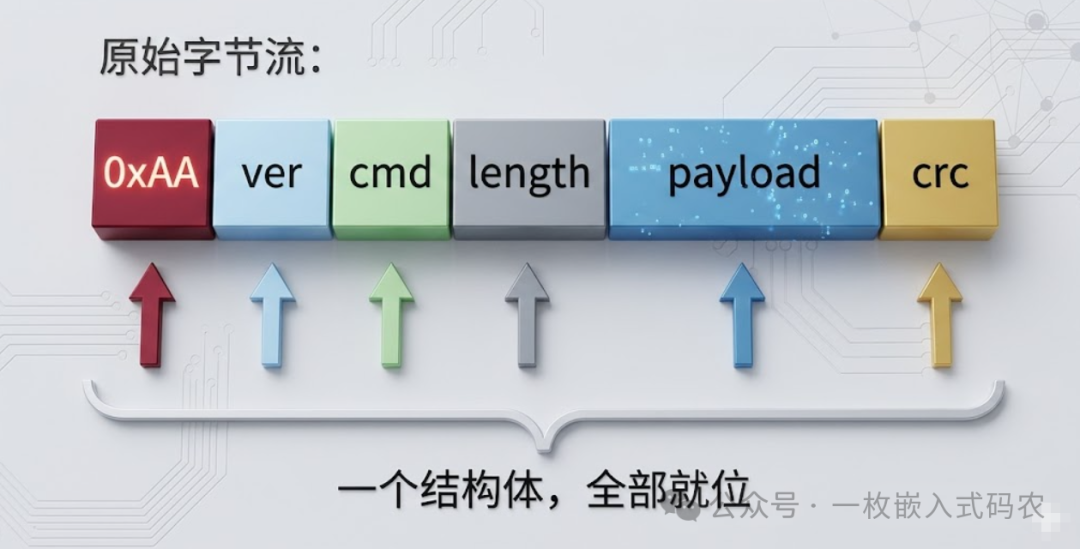
这里有两个坑必须提醒:一是 #pragma pack(1) 或 __attribute__((packed)) 不能省,否则字段之间会被编译器插填充字节;二是跨设备通信要注意大小端,多字节字段建议走一层 htons/htonl 宏显式转换,比事后改 bug 便宜多了。
我见过不止一个项目在这一点上翻车:开发板和仿真器都是小端,代码写得很顺,一切正常;等上了真实产品线,对端换成了大端 MCU,整个协议瞬间解析错位。排查了两天才定位到是结构体字段在传输时没做字节序约定。所以——协议类结构体一旦定义下来,大小端和字节对齐这两件事必须在注释里写清楚,比 crc 算法都重要。
七、配置表:让“新增功能”只改表不改代码
最后一种写法,也是我个人最喜欢的一种——把行为压进数据。以 GPIO 初始化为例,新手常见的写法是写一大段一大段的 HAL_GPIO_Init(...),每多一路设备就多复制十几行。而老手会这样写:
typedef struct {
GPIO_TypeDef *port;
uint16_t pin;
uint8_t mode;
uint8_t pull;
uint8_t speed;
const char *name; // 顺便留给调试打印用
} gpio_cfg_t;
static const gpio_cfg_t g_gpio_table[] = {
{ GPIOA, GPIO_PIN_0, MODE_OUT, PULL_NONE, SPEED_HIGH, "LED_RUN" },
{ GPIOA, GPIO_PIN_1, MODE_IN, PULL_UP, SPEED_LOW, "KEY_BOOT" },
{ GPIOB, GPIO_PIN_5, MODE_OUT, PULL_NONE, SPEED_HIGH, "BUZZER" },
// 新增一路:加一行,仅此而已
};
void gpio_init_all(void)
{
for (size_t i = 0; i < ARRAY_SIZE(g_gpio_table); i++) {
hw_gpio_setup(&g_gpio_table[i]);
}
}
代码结构从“每路一段流程”变成了“一段流程 + 一张表”:
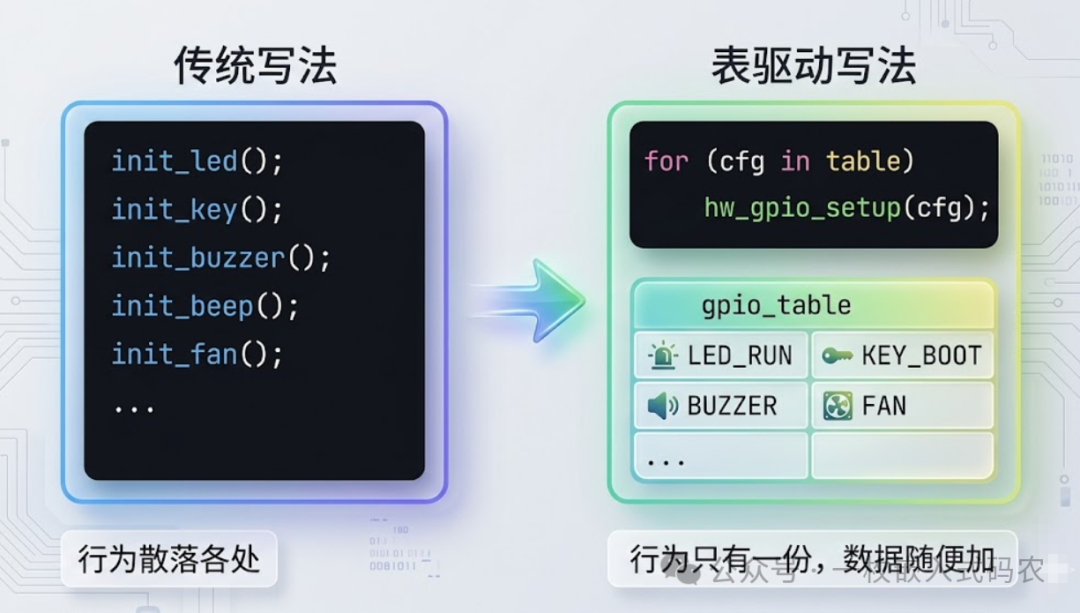
只要把流程写稳,后面新增、删减、修改,都是改数据的事情,出错概率肉眼可见地下降。按键映射、菜单、命令表、中断向量、任务表……几乎所有“一堆相似对象要同样处理一遍”的场景,都可以套这个模式。
这张配置表还有一个隐藏福利:因为是 const 数组,它会被编译器放到 Flash 里,不占一个字节的 RAM。对那些 RAM 只有几 KB 的小 MCU 来说,这个省法常常是决定性的。再搭配 ARRAY_SIZE 这种宏自动推算条目数,整份代码连“新增后忘了改循环上限”的低级 bug 都一并解决了——工程里最怕的从来不是复杂逻辑,是那种“看起来一定没问题”的小疏忽。
写到这里,你有没有发现一件事
回头把上面 7 种写法摆在一起看:
- 寄存器映射,是在给硬件建模;
- 函数指针驱动,是在做“多态”和“接口隔离”;
- 状态机结构体,对应的是“状态模式”;
- 消息封装 + 柔性数组,本质是“数据传输对象 (DTO)”;
- 侵入式链表,是一种通用容器抽象;
- 协议帧结构体,是“解析器”的对象化;
- 配置表驱动,直接对应“表驱动 / 策略模式”。
——每一种嵌入式老工程师天天在用的写法,其实都能在设计模式里找到它的名字。这也解释了为什么那些复杂的 算法与数据结构 思维,如动态规划和图论中的状态管理,能在此处映射得如此清晰。
结构体能走这么远,不是因为 C 语言有多强,而是因为它后面站着的那些设计思想足够强。嵌入式里资源紧、节拍快、调试难,代码一旦组织得不好,后期每加一个功能都会像在危楼上盖新层。设计模式不是 Java 程序员的专利,恰恰相反——越是资源受限、越是需要长期维护的嵌入式项目,越需要把“思路”沉淀下来。
很多做了几年的嵌入式同学,最大的瓶颈不是不会写代码,而是凭感觉写代码:每次遇到复杂逻辑,都要重新设计一遍,写完自己都怕改。把设计模式这套“前人整理好的最佳实践”吃透,你会发现从状态机到驱动框架,从通信协议到菜单系统,很多过去让你头疼的结构,都有现成的解法。
在云栈社区,我们常说嵌入式开发不仅仅是堆代码,更是在有限资源下解决问题的艺术。愿你写的下一版固件,不再只是“能跑”,而是“好改、好扩、好交接”。
 发表于 2026-4-28 00:10:45
|
查看: 172|
回复: 0
发表于 2026-4-28 00:10:45
|
查看: 172|
回复: 0
