一年一度的公司风向标会议,各个部门都在提AI,但我今天不谈AI,想聊聊嵌入式开发中的一个小思考:堆栈分析。
玩 C 或 C++ 都离不开对堆栈的深刻理解。堆栈到底该配置多大?这是个经验性问题——配小了容易“爆栈”引发 HardFault、随机死机;配大了又会浪费资源、增加成本。你当然想知道,你的嵌入式程序每个任务所需的最大堆栈是多少,然后在那个基础上预留一点安全余量就完美了。
然而,大部分工具只能分析编译后的静态堆栈使用数据,无法知晓程序真正跑起来时的堆栈消耗。既然这样,静态分析岂不是多此一举?别急,我们一步步来,先看看静态分析都干了啥。
静态堆栈分析做了什么?
在程序还没运行时,我们能拿到的只有源码、函数调用关系和编译后的二进制文件,当然这里面也包含对堆栈的操作。
有了这些信息,静态堆栈分析就能派上用场了。最直接的就是单函数栈帧的计算。编译器可以精确算出每个独立函数的栈帧大小,这部分是完全确定的:
- 函数内的局部变量、数组、结构体的总大小
- 函数调用时需要保存的 CPU 寄存器(如 ARM Cortex-M 的 R4-R11 等)
- 函数参数、返回地址的存储开销
- 栈对齐所需的填充字节
例如,GCC 编译器提供的 -fstack-usage 选项,会为每个编译单元(.c / .cpp)生成一个对应的 .su 文件(Stack Usage 文件)。该文件记录了每一个函数的堆栈帧大小信息,格式大致像这样:

这里的 static 表示函数的堆栈帧大小完全在编译时确定,全部来自静态分配的局部变量、保存的寄存器、参数区域等。dynamic 则表示函数中使用了运行时动态栈分配,比如 alloca 或可变长度数组(VLA),因此报告中的数值只包含静态部分,运行时还会动态增加。
当然,单函数分析只是第一步。更全面的做法是进行静态调用图的理论栈深估算。
静态分析工具会扫描所有确定的函数调用关系,构建调用树(Call Graph),然后找到最深的那条调用路径,将路径上所有函数的栈帧大小累加起来,得出一个理论最大栈深。
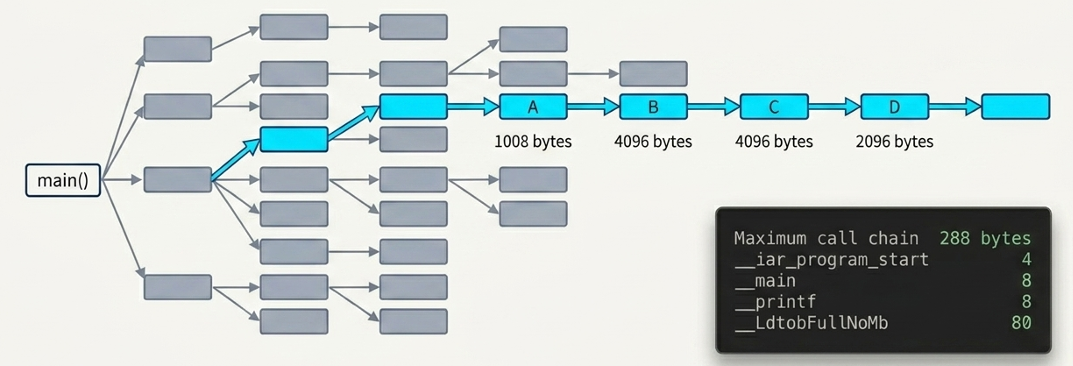
像 IAR、Keil 等 IDE 的静态栈分析功能,就是基于这个逻辑,在 map 文件中输出类似下面的报告:
*************************************************************************
*** STACK USAGE
***
Call Graph Root Category Max Use Total Use
------------------------ ------- ---------
Program entry 288 288
Maximum call chain 288 bytes
"__iar_program_start" 4
"_main" 8
"_printf" 8
"__PrintfFullNoMb" 152
"__LdtobFullNoMb" 80
为什么必须做动态分析?
没办法,动态堆栈信息必须让程序跑起来才能获取。因为静态分析的所有结论,都建立在一个假设上:程序的执行路径、调用关系、触发时机都是编译期可预测的。但在 C/C++ 嵌入式系统实际运行中,这个前提往往不成立。
1. 动态调用:编译期根本不知道你会调用谁
嵌入式代码中充满了大量的间接调用:
- 函数指针:比如状态机的跳转表、驱动的回调函数,编译期根本不知道这个指针最终会指向哪个函数。
- 回调函数:比如外设中断的回调、RTOS 的定时器回调,调用关系是在运行时注册的。
这就导致静态分析的调用图无法一层层往下追踪,也就是常说的“断链”。即使编译器足够聪明,尝试把所有路径的栈开销都加起来找到最深栈,当程序规模一大,这种分析也会变得非常吃力。
2. 递归调用:爆栈的头号元凶
递归的深度完全取决于输入数据。比如快速排序的递归深度,就取决于输入数组的有序程度。静态分析通常直接忽略递归,或者需要你手动指定一个最大递归深度,这显然不够准确。
3. 中断的隐形栈开销
中断是异步的,它随时可能打断当前正在执行的代码,不管你的函数调用到了哪一层。
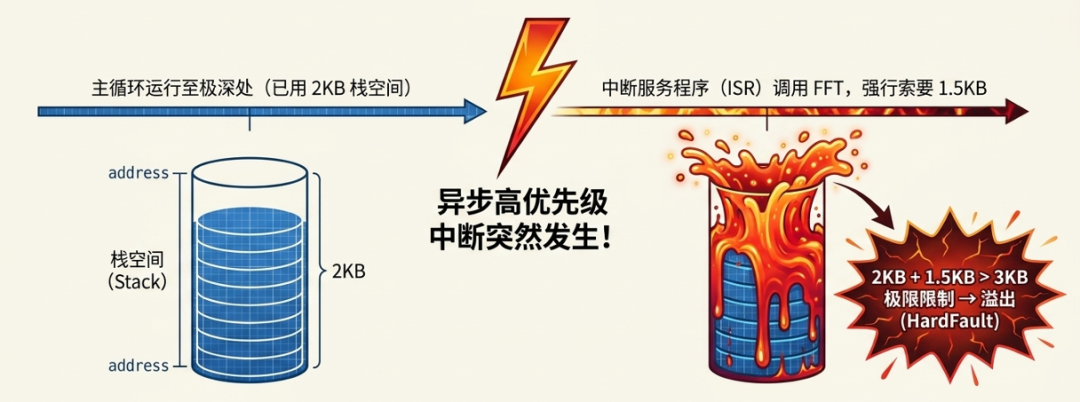
想象一下:主程序正在执行最深的调用链,已用掉 2KB 栈空间;这时一个高优先级中断突然触发,CPU 立即跳转到中断服务程序(ISR);ISR 自己又调用了 FFT 函数,额外需要 1.5KB 栈。如果你的总栈空间只有 3KB,直接溢出,触发 HardFault。
所以,中断随时可能“插队”,将两个栈开销叠加起来。这种叠加效应,只有运行时才能测到。更何况,如果你的系统支持中断嵌套,可能一个中断里又来另一个中断,栈开销会层层加码,风险更高。
4. RTOS 多任务更复杂

RTOS 任务的栈都是独立且动态的。高优先级任务随时可以抢占低优先级任务。而且对于单堆栈的 CPU 而言,中断的栈开销是随机扣在某个任务的栈上的!这无疑让问题变得更加棘手。
总的来说,动态堆栈分析,还是得在程序跑起来的复杂工况下进行。
运行时堆栈检测:“栈水印”方法
堆栈的静态分析有其局限,因此进行动态分析——也就是我们常说的“栈水印”(High Watermark)方法——就显得尤为重要。

以前的文章有详细介绍,这里再列举几篇:
其大致流程就是:做栈标记 → 暴力测试 → 看水位。像 IAR 的 C-SPY 调试器、FreeRTOS 的 uxTaskGetStackHighWaterMark() 函数,基本都是这个原理。
我在做稳定性、可靠性要求较高的产品时,遵循的流程基本是三步走:
- 先用静态分析做第一轮评估,设置初始堆栈大小。
- 然后在各种工况下做长时间的压力测试,用动态分析拿到真实的栈峰值。
- 最后,预留至少 20%~40% 的安全余量,确保极端情况下也不会溢出。
没错,我们就得这么稳。
最后,聊点题外话。在 云栈社区 经常能看到关于底层调试技巧和内存管理的讨论,很多坑只有真正在板子上调过才能体会。如果你也有类似的经历或疑问,不妨到社区里一起聊聊,这种避坑经验,多交流才能成长得更快。
 发表于 2026-4-24 18:34:42
|
查看: 156|
回复: 0
发表于 2026-4-24 18:34:42
|
查看: 156|
回复: 0
