
本文将详细介绍一个完整的嵌入式机器学习项目流程:使用 MATLAB 对开源手写字母数据集进行处理、训练,并最终将模型部署到 Rockchip RK3588 边缘设备上,旨在实现微秒级识别延迟,以提升人机交互体验。
本篇作为“数据工程与模型训练篇”,将重点解析数据集获取、可视化探索、数据清洗、特征工程、模型训练与评估优化的全链路。后续篇章将涉及模型转换与硬件在环(HIL)测试。
一、项目概述
1.1 选题背景
在面向消费电子的嵌入式系统工程中,子系统与应用繁多。某些辅助功能(例如基于主动笔的手写字符输入)对即时性要求极高,同时不应占用过多系统资源。本项目基于 TL3588F-EVM 评估平台及其 SDK,利用 MATLAB R2025b 对官方开放数据集进行样本处理、模型训练与优化,目标是在 RK3588 上实现微秒级手写字符识别,降低延迟与资源开销。
1.2 模型选择
针对嵌入式 HIL 工程场景,手写识别模型不仅需要较高精度,更要满足嵌入式系统对实时性和资源的严苛约束。在非神经网络的机器学习算法中,我们重点考察了 K-最近邻(KNN)与支持向量机(SVM)两种方案。
1.2.1 KNN 与 SVM 对比
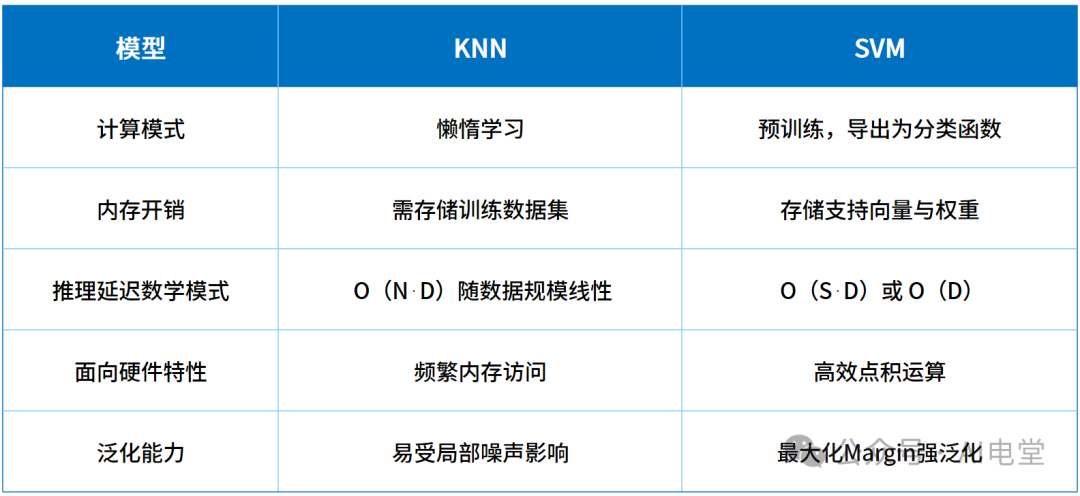
▲ 表 1 KNN与SVM的特性对比
手写识别的用户体验极度依赖即时响应。KNN 的推理速度与训练样本数量 N 线性相关,当字符库扩大时,计算距离与排序的开销会显著增加,导致识别延迟出现波动。而 SVM 在训练完成后计算量固定,能在嵌入式 CPU 上实现稳定推理,避免因计算拥塞导致的输入卡顿。
尽管 RK3588 内存资源较强,但作为多任务消费电子系统,子应用应尽量减少对总线与内存的占用。KNN 需要将大量训练样本常驻内存,这对内存带宽和容量是种浪费。相比之下,SVM 通过寻找最优超平面,将分类决策转化为少数支持向量的运算。经过 MATLAB 优化后,模型参数量可极大缩减,这不仅利于导出为 C 语言库,也显著降低了端侧部署时的存储与 RAM 占用。
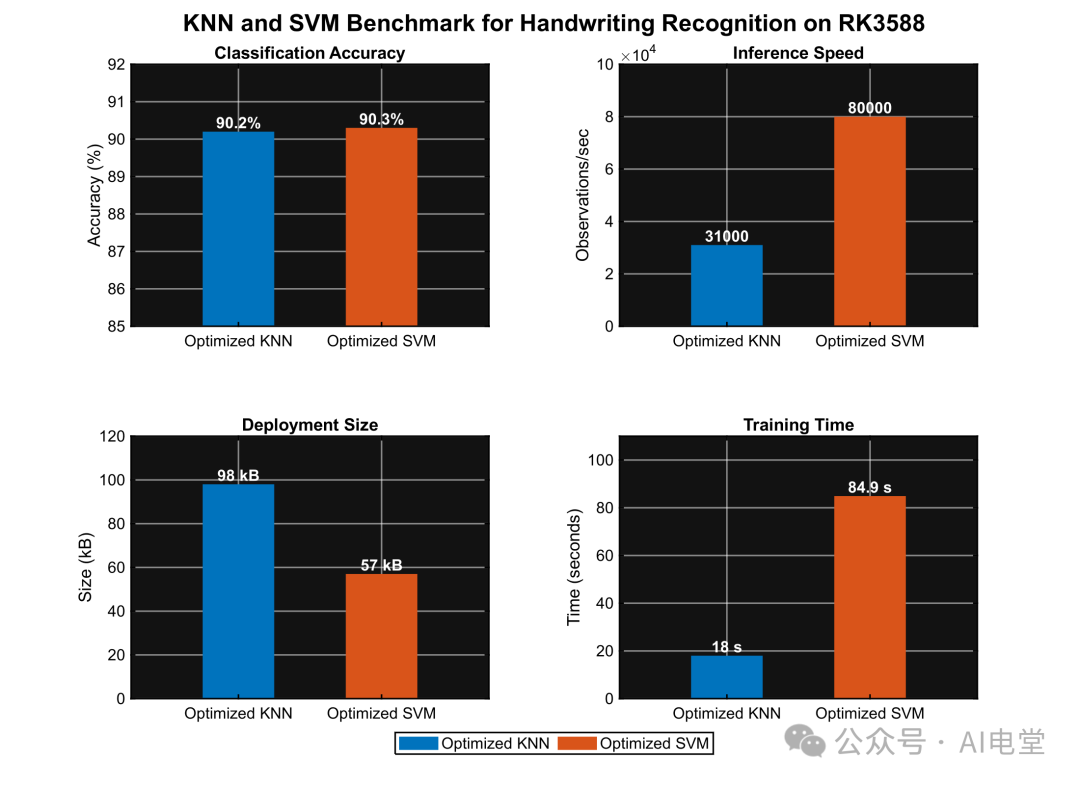
▲ 图 1 未清洗数据时,可优化KNN与可优化SVM的性能概要对比
1.3 项目目标
本项目旨在使用 MATLAB 对包含 87 位用户书写的 9 个字母(共 1341 个样本)的笔画数据进行预处理和特征提取。利用 classificationLearner 进行三折交叉验证,并保留 5% 数据作为验证集,分别训练精细 KNN、加权 KNN、高效线性 SVM、可优化 SVM 以及可优化 KNN。通过对比混淆矩阵和模型概要,选取综合最优模型。
随后,使用 MATLAB Coder 将模型转换为适用于 ARM Cortex-A 处理器的 C 语言静态库,在 Ubuntu 22.04 虚拟机环境中构建嵌入式工程,并通过交叉编译工具链生成可执行文件进行 HIL 测试。HIL 测试将使用完整数据集在目标板上评估模型,输出总推理时间、单次推理时间及混淆矩阵,以验证跨平台转换后的推理效果,为后续应用集成做准备。
二、数据集介绍
2.1 数据集来源
数据集来源于 MATLAB 官网的示例数据集。
2.2 数据集规模
数据包含了 87 位用户使用主动式电容笔书写的 9 个字母(a, h, k, m, o, r, s, t, w)的笔画数据,共计 1341 个独立样本。每个样本存储为一个 .txt 文件,总大小约 1.92MB。
2.3 字段说明
每个样本的 .txt 文件基本格式如下:
Time,X,Y,P
0,-0.0296747457290869,0.117938092000219,0.028
0.008,-0.0296747457290869,0.117938092000219,0.161
...
0.524,0.389766371787818,-0.641050596839895,0.271
0.535,0.409739758336242,-0.654366187872178,0.104
0.536,NaN,NaN,NaN
▲ Listing 1 单样本数据格式

▲ 表 2 数据集字段含义
2.4 数据可视化
将完整数据集导入 MATLAB 工作区并新建脚本。
可视化单样本:
letter = readtable("user016_w_1.txt")
plot(letter.X, letter.Y)
axis([-1 1 -1 1])
▲ Listing 2 单样本可视化脚本
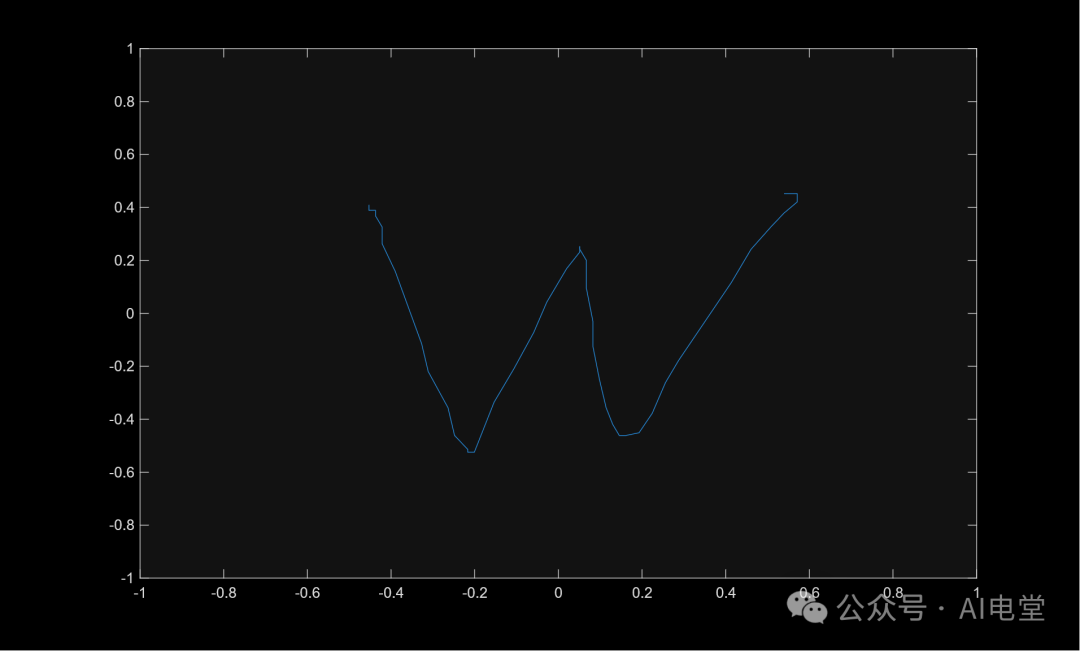
▲ 图 2 可视化后的 user016_w_1.txt(字母‘w’)
可视化某一类样本(例如,在同一张图上可视化所有 *_r_*.txt 文件):
letterds = datastore("*_r_*.txt")
data = readall(letterds)
plot(data.X, data.Y)
axis([-1 1 -1 1])
▲ Listing 3 类样本可视化脚本
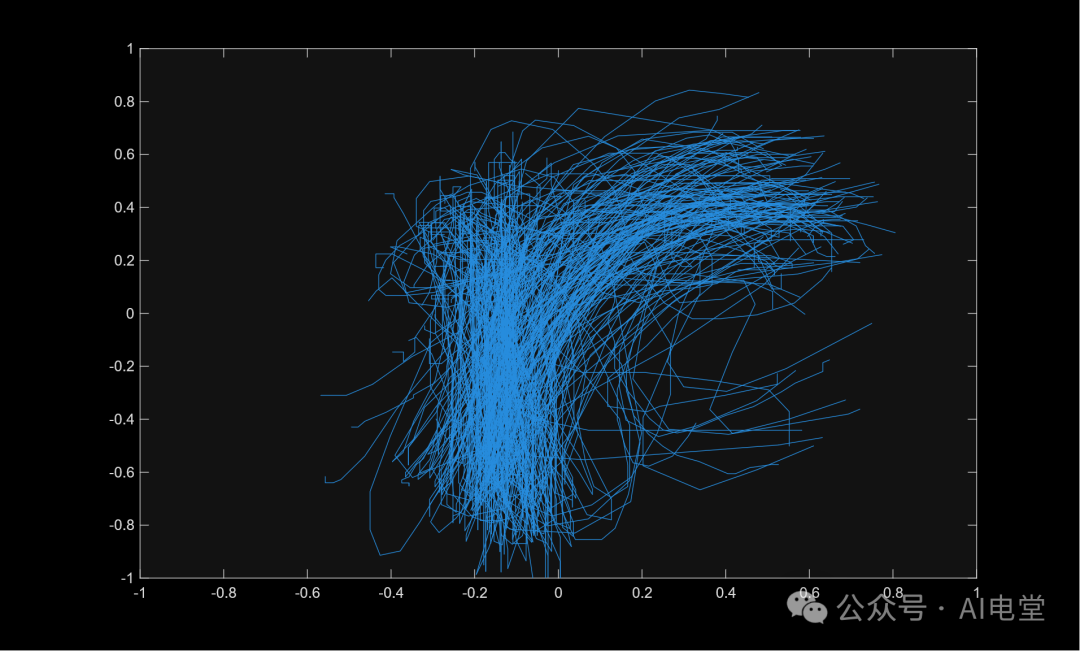
▲ 图 3 可视化后的字母‘r’类样本
三、提取特征后的数据预处理
由于本工程处理的数据较为特殊,需要先提取特征,再基于特征绘制箱型图进行分析和处理。
导入完整原始数据集并提取特征(特征工程细节见第四节)后,绘制箱型图进行分析。
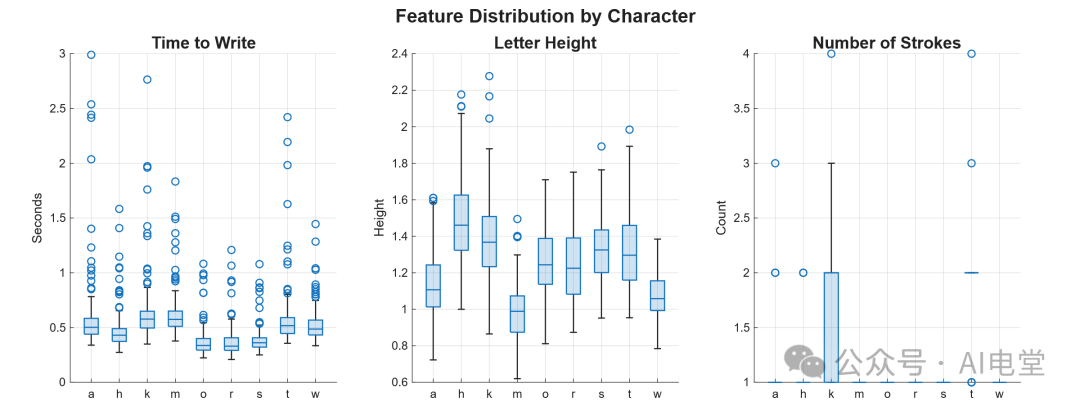
▲ 图 4 针对三个关键特征的箱型图(清洗前)
从箱型图不难看出,timeToWrite(书写时间)、letterHeight(字母高度)和 numStrokes(笔画数)三个特征均存在明显的离群点。为此,设计以下脚本进行数据清洗:
%% Clean
% Clean timeToWrite
data(data.timeToWrite > 0.8, :) = [];
% Clean letterHeight
data(data.letterHeight > 2.5 | data.letterHeight < 0.2, :) = [];
% Clean numStrokes
data(data.numStrokes > 3, :) = [];
▲ Listing 4 数据清洗脚本
该脚本清除了极端异常的离群数据,同时保留了一部分轻度离群数据用于模型训练,以保持一定的数据多样性。使用清洗后的数据重新绘制箱型图。
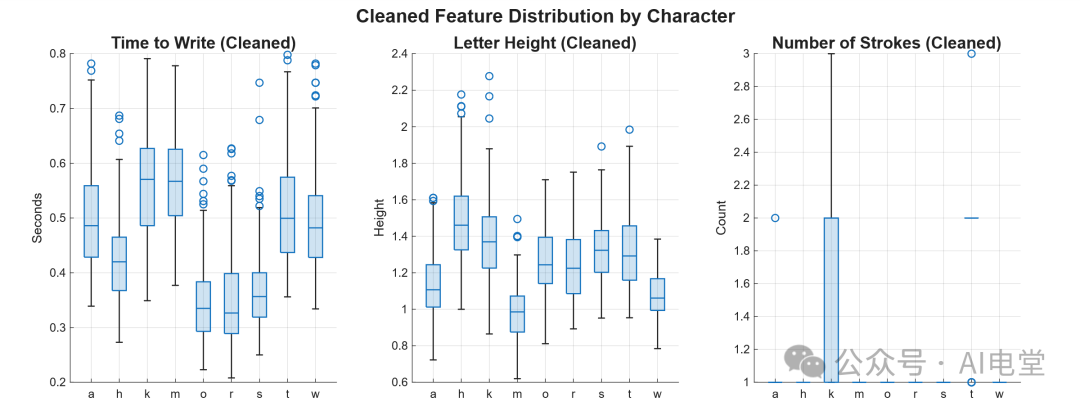
▲ 图 5 数据清洗后的箱型图
四、特征工程
根据数据可视化结果和领域知识,我们从原始笔画坐标时间序列中提取了以下8个特征:
- 起始点 X 坐标 (
firstXpos)
- 起始点 Y 坐标 (
firstYpos)
- 结束点 X 坐标 (
lastXpos)
- 结束点 Y 坐标 (
lastYpos)
- 书写总时间 (
timeToWrite)
- 字母高度 (
letterHeight)
- 字母宽度 (
letterWidth)
- 笔画数量 (
numStrokes)
具体实现代码如下:
% Create a function that extracts the letter features
function features = extractLetterFeatures(letter)
% Extract features
firstXpos = letter.X(1);
lastXpos = letter.X(end-1);
firstYpos = letter.Y(1);
lastYpos = letter.Y(end-1);
timeToWrite = letter.Time(end);
letterHeight = range(letter.Y);
letterWidth = range(letter.X);
numStrokes = sum(ismissing(letter.P));
% Combine features into a table
features = table(timeToWrite, letterHeight, letterWidth, ...
firstXpos, lastXpos, firstYpos, lastYpos, numStrokes);
end
% Use a transformed datastore to extract all letter features into a
% variable named data
letterds = datastore("letterFiles\*.txt");
featds = transform(letterds, @extractLetterFeatures);
data = readall(featds)
▲ Listing 5 特征提取函数及特征集成脚本
五、模型训练与评估
打开 MATLAB 的 classificationLearner App,我们创建两个会话,分别使用原始数据集和清洗后的数据集。均设置为 3 折交叉验证。
考虑到最终是嵌入式工程部署,为了达到最佳训练效果,我们使用 95% 的数据作为训练集,5% 作为测试集。在两个会话中,我们均训练迭代次数为 40 的“可优化 KNN”和“可优化 SVM”。为了高效优化超参数,采用贝叶斯优化(Bayesian Optimization)算法进行自动优化。
以下是使用不同数据集训练出的模型混淆矩阵对比:
使用未清洗数据训练:
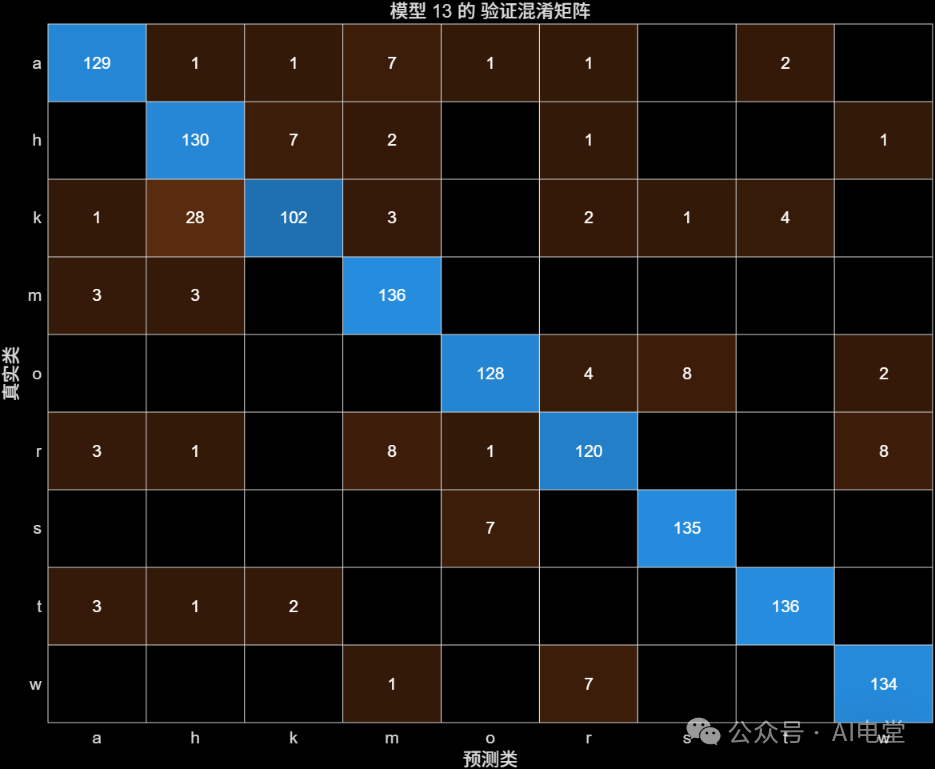
▲ 图 6 数据未清洗前,可优化KNN的验证混淆矩阵
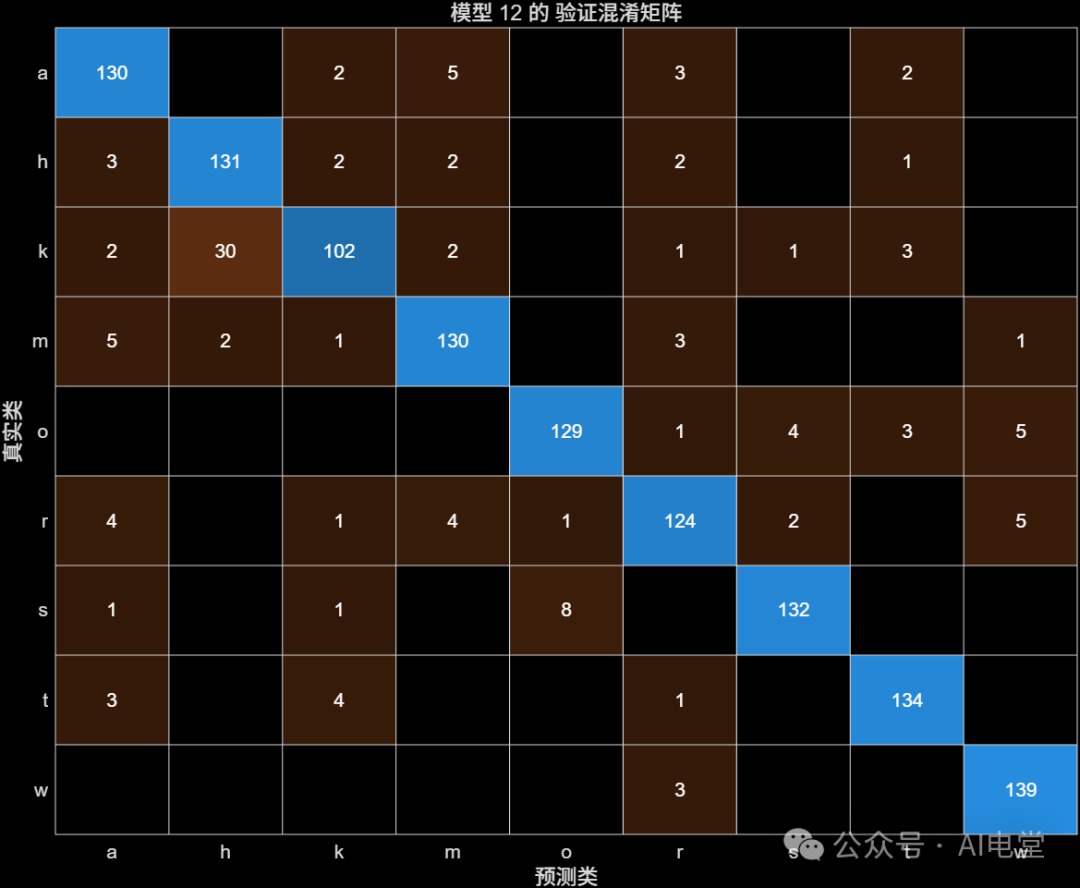
▲ 图 7 数据未清洗前,可优化SVM的验证混淆矩阵
使用清洗后数据训练:
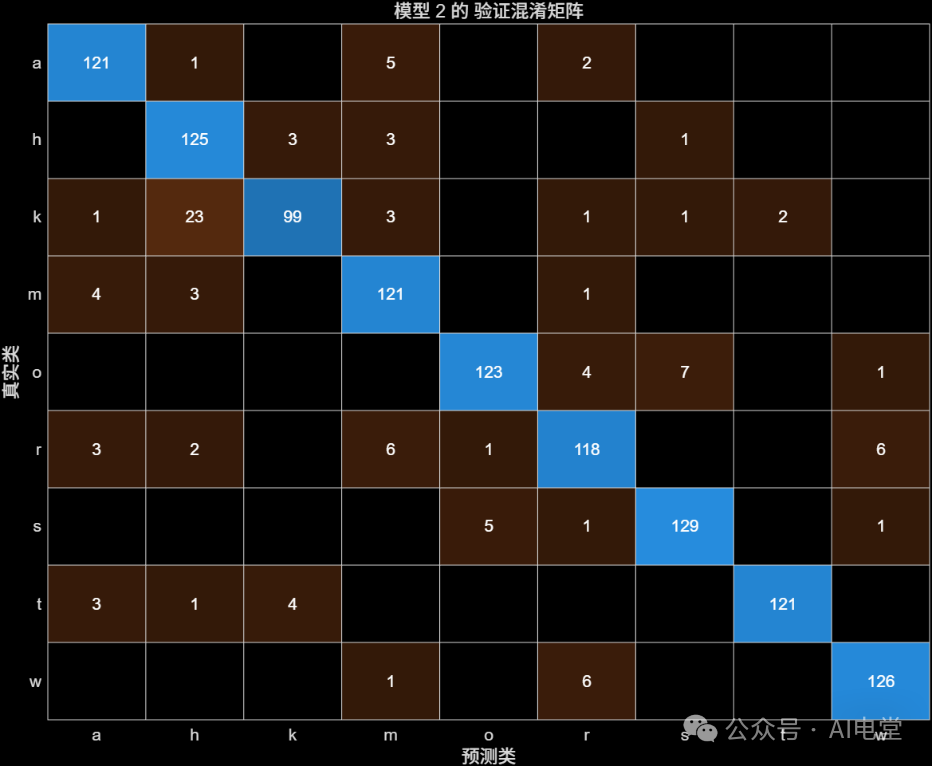
▲ 图 8 数据清洗后,可优化KNN的验证混淆矩阵
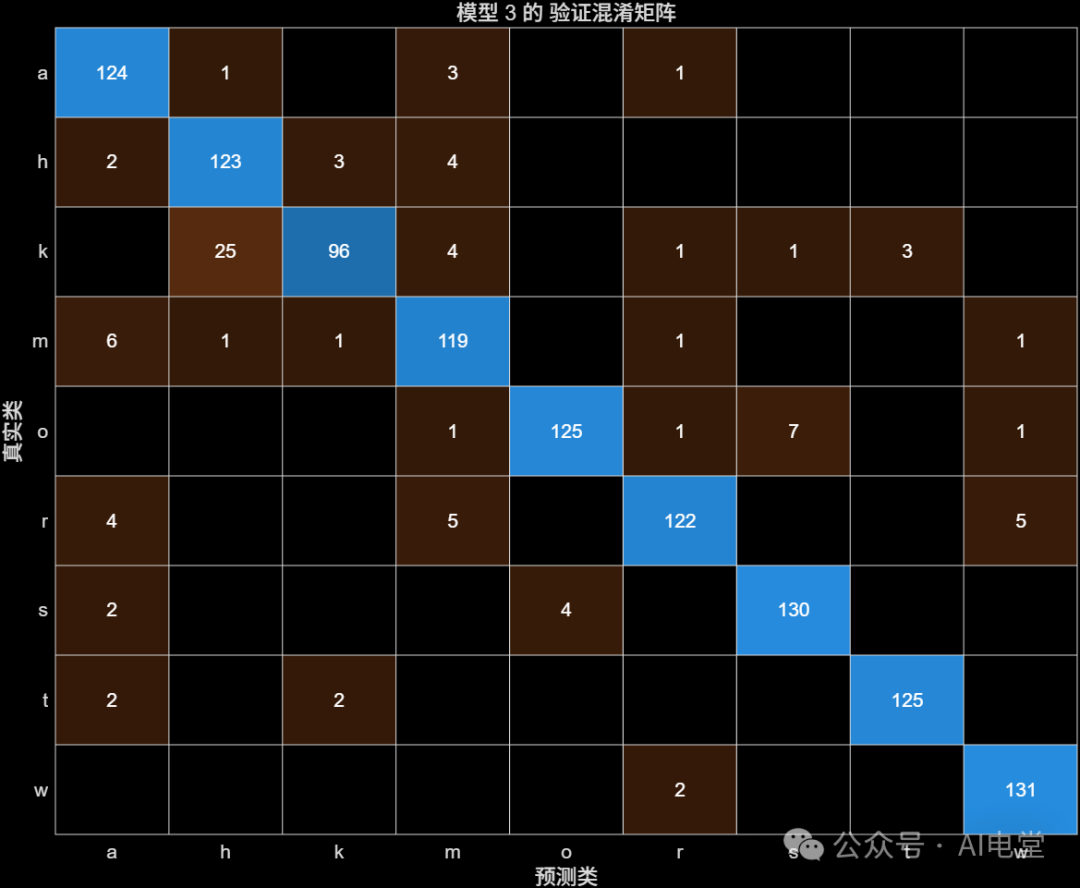
▲ 图 9 数据清洗后,可优化SVM的验证混淆矩阵
通过混淆矩阵可以直观看出,数据清洗后,两类模型的分类准确性均有提升,对角线上的数值(正确分类的样本数)更加集中和突出。
关键性能指标对比
下图综合对比了数据清洗后,可优化 KNN 与可优化 SVM 在验证准确率、测试准确率、验证成本、推理速度、部署大小和训练时间上的表现。
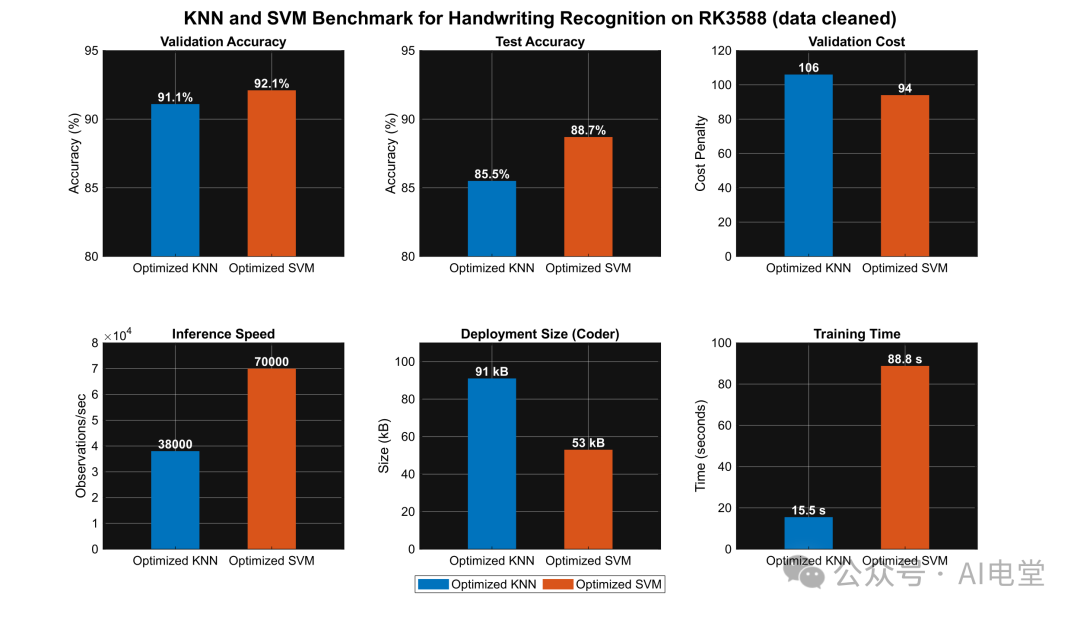
▲ 图 10 数据清洗后,可优化KNN与可优化SVM的评估指标对比
从对比结果可知,在 模型训练 这一关键环节,经过优化的 SVM 模型在验证准确率(92.1% vs 91.1%)、测试准确率(88.7% vs 85.5%)、推理速度(70000 obs/s vs 38000 obs/s)和部署大小(53 kB vs 91 kB)上均优于 KNN 模型,虽然其训练时间更长。这为后续选择 SVM 模型进行 嵌入式端侧部署 提供了数据支撑。
总结与展望
本文详细记录了利用 MATLAB 完成手写字母识别项目的数据工程与模型训练阶段。通过数据可视化、清洗、特征提取到最终的模型训练与评估,我们对比了 KNN 与 SVM 在嵌入式场景下的潜力。结果表明,经过数据清洗和超参数优化后,SVM 模型在精度和效率上更符合嵌入式端侧部署的要求。
当然,这只是整个 人工智能 项目链的第一步。模型训练完成后,下一步将是利用 MATLAB Coder 将精选的模型转换为 C 代码,并集成到 RK3588 的嵌入式工程中进行硬件在环(HIL)测试,验证其在真实硬件上的微秒级推理性能。整个流程体现了从算法原型到嵌入式产品落地的完整思路,希望对各位开发者的项目实践有所启发。欢迎在 云栈社区 交流更多关于嵌入式 AI 部署的经验与问题。
 发表于 2026-4-20 09:38:15
|
查看: 223|
回复: 0
发表于 2026-4-20 09:38:15
|
查看: 223|
回复: 0
