作为C/C++开发人员,内存泄漏大概是我们最常打交道的问题之一。这归根结底是由语言的特性决定的:C/C++要求开发者自行管理内存的申请与释放。一旦使用不当,就很容易触发 segment fault 或者 memory leak。
今天这篇文章,就来系统地聊聊项目中常见的内存泄漏原因,以及如何有效避免和精准定位这些顽疾。
在深入细节之前,不妨先在 云栈社区 和同行们交流一下,看看大家在实战中都用过哪些“土办法”来排查这些头疼的问题。
背景
在C/C++中,内存的分配与回收完全由编写代码的开发者主动完成。这样做的好处是内存管理开销小,程序执行效率更高;但弊端也很明显:它极度依赖开发者的水平。随着代码规模膨胀,稍不留神就可能忘记释放内存,或因为一些不规范的编程习惯埋下安全隐患。如果对内存管理不当,程序中就可能潜伏内存缺陷,甚至会在运行时突然爆发内存故障。
在各种缺陷里,内存泄漏尤为棘手,对系统稳定运行的威胁极大。所谓内存泄漏,就是指动态分配的内存在程序结束前始终未被回收。由于操作系统、编译器、开发环境等系统软件大多由C/C++实现,它们也天然携带着内存泄漏的风险。对那些需要在服务器上长期运行的软件来说,内存泄漏会带来灾难性的后果,比如 性能下降、程序终止、系统崩溃甚至无法提供服务。
所以,本文将从 原因、避免 以及 定位 几个维度进行深入剖析,希望能给你带来真正的帮助。
概念
内存泄漏,通俗来说,就是程序中已动态分配的堆内存,因为某些原因在程序不再需要时却未释放或无法释放。这不仅造成系统内存的浪费,还会拖慢程序运行速度,严重时直接导致系统崩溃。
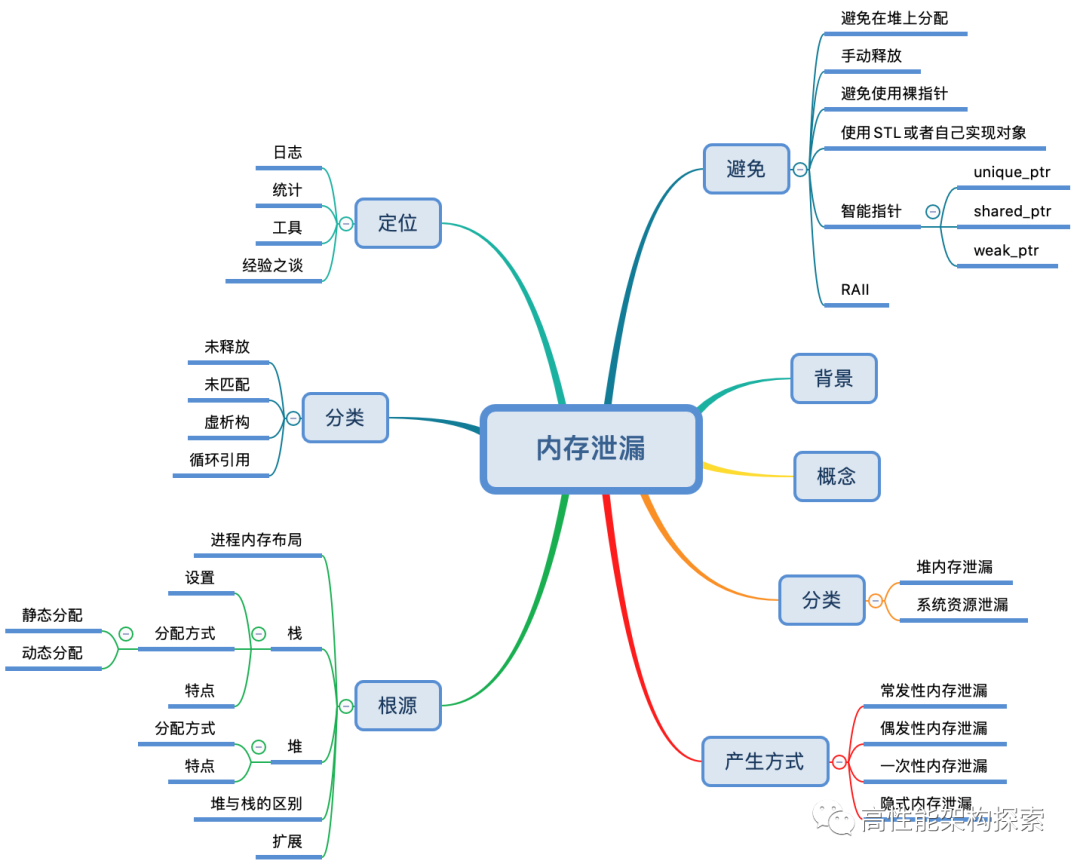
当我们在程序中使用 new 操作符或者 free 函数对原始指针进行操作时,实际上是在堆上为其分配内存,这块内存指的是RAM,而非硬盘等永久存储。一个持续申请而不释放(或极少释放)内存的应用,最终会因为内存耗尽而触发 OOM(out of memory)。
为了方便理解内存泄漏的危害,不妨打个比方。有一家宾馆,共100间客房,顾客每次都到前台登记并拿到房间钥匙。如果有些顾客不住之后,既不去前台退房,也不归还钥匙,久而久之,前台可用的房间就会越来越少,收入骤降,最终濒临倒闭。程序申请内存后却不归还,情况类似:可用内存越来越少,最终操作系统会启动自我保护,直接杀掉那个进程,也就是我们常说的 OOM。
分类
内存泄漏主要分为两类:
- 堆内存泄漏:我们通常口中说的内存泄漏,就是指堆内存泄漏。在堆上申请了资源,使用完毕后却没有释放并归还给操作系统,导致该块内存永远无法被再次利用。
- 资源泄漏:这通常指系统资源,比如 socket、文件描述符等。这些东西在操作系统层面都是有限额的,如果只创建不归还,久而久之,资源便会耗尽,导致其他程序无法正常工作。
本文的核心是分析堆内存泄漏,所以下文提到的“内存泄漏”,都特指 堆内存泄漏。
根源
内存泄漏,主要就是指在堆上申请的动态内存泄漏,更确切地说,是指针指向的内存块被遗忘释放,导致该块内存再也无法被重新申请使用。
之前看过一句话:“指针是C的精髓,也是初学者的一个坎。” 换种角度看,内存管理就是C的精髓。C/C++可以直接与操作系统打交道,从性能角度出发,开发者能根据实际场景灵活地分配和释放内存。尽管自 C++11 起引入了 Smart Pointers 体系,能在很大程度上避免使用裸指针,但依然无法完全杜绝。一个重要的原因是,你无法保证团队内的其他成员不使用指针,更无法保证合作的第三方部门也遵循同样的规范。
那么,为什么C/C++中会有指针的存在呢?
这得从进程的内存布局说起。
进程内存布局
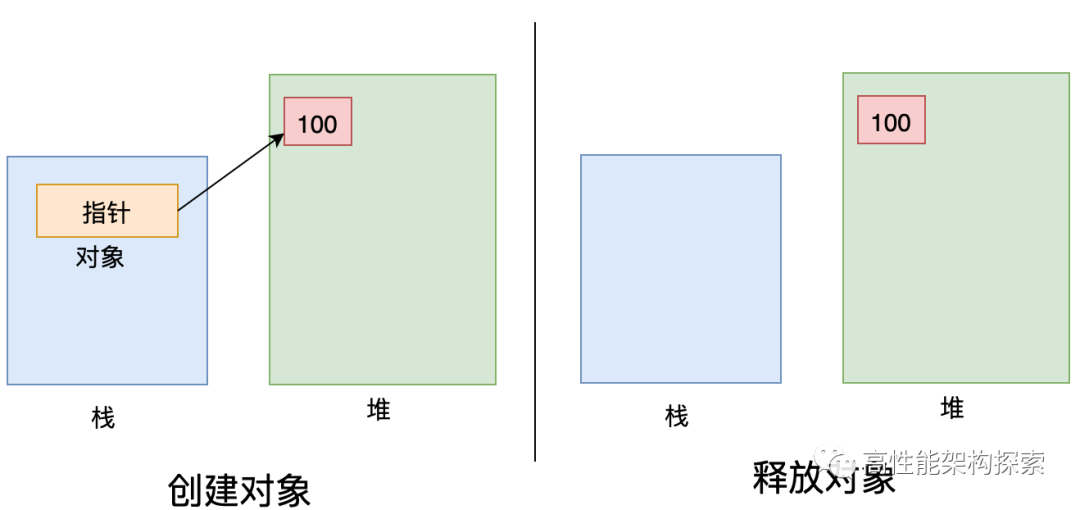
上图是32位进程的内存布局,主要包含以下几个区块:
- 内核空间:供内核使用,存放内核代码和数据。
- stack:这就是我们常说的栈,用来存储自动变量。
- mmap:即内存映射,用于在进程虚拟内存地址空间中分配地址空间,并创建与物理内存的映射关系。
- heap:就是我们常说的堆,动态内存的分配都在这个区域进行。
- bss:存放所有未初始化的全局变量和静态变量。此段中的所有变量都由0或空指针初始化,程序加载器在加载程序时会为BSS段分配内存。
- data:已初始化的数据段。
- 包含显式初始化的全局变量和静态变量。
- 此段的大小在编译时就由源代码决定,运行时不会改变。
- 它具有读写权限,因此变量值可在运行时修改。
- 该段可进一步细分为初始化只读区和初始化读写区。
- text:也叫文本段。
- 该段包含已编译程序的二进制机器码。
- 它是一个只读段,用于防止程序被意外篡改。
- 该段是可共享的,因此对于文本编辑器这类会被频繁执行的程序,内存中只需保留一个副本。
由于本文聚焦于内存分配,接下来的内容将只涉及栈(stack)和堆(heap)。
栈
栈是一块连续的内存区域,其上的内存分配就是在这块连续空间上操作。编译器在编译阶段就已经确定了需要分配的内存大小。当函数被调用时,其内部变量都会在栈上分配内存;函数调用结束,内部变量便会被释放,内存也随之归还。
class Object {
public:
Object() = default;
// ....
};
void fun() {
Object obj;
// do sth
}
在上述代码中,obj 对象就是在栈上分配的。当执行流离开 fun 的作用域时,会自动调用 Object 的析构函数进行释放。
前面提到,局部变量会在其作用域结束后被析构并释放内存。由于分配和释放的顺序完全相反,正好符合堆栈“先进后出”的特性,C++语言的实现通常也会借助调用堆栈来分配局部变量(尽管这并非标准的硬性要求)。
因为栈上的内存分配与释放,就是一个进栈和出栈的过程(对编译器而言可能只是一条指令),所以相较于堆上的分配,栈要快得多。
虽然栈的访问速度远快于堆,但每个线程都拥有自己独立的栈,且栈上的对象不能跨线程访问。这决定了其空间大小是有限制的。如果栈空间开得太大,在一个拥有几十甚至上百个线程的大型程序中,光栈空间就可能消耗掉大量RAM,进而挤压 heap 的可用空间,影响程序整体运行。
设置
在 Linux 系统中,可以通过以下命令查看当前的栈大小限制:
ulimit -s
10240
在笔者的机器上,输出结果是 10240 (KB),即 10MB。我们也可以通过 shell 命令临时修改栈大小。
ulimit -s 102400
这条命令会将栈空间临时修改为 100MB。而永久性修改则需要编辑这个文件:
/etc/security/limits.conf
分配方式
静态分配
静态分配由编译器在编译期完成,例如局部变量和函数参数。
void fun() {
int a[10];
}
上述代码中,数组 a 占据 10 * sizeof(int) 个字节,在编译时就直接计算好了,运行时只需直接进行进栈、出栈操作。
动态分配
很多人可能误以为只有堆上才存在动态分配,栈上只能是静态分配。其实不然,栈同样 支持动态分配,这种动态分配由 alloca() 函数实现。栈的动态分配和堆不同,通过 alloca() 分配的内存由编译器负责释放,完全无需手动干预。
特点
- 分配速度快:分配大小由编译器在编译期完成。
- 不会产生内存碎片:栈内存分配是连续的,遵循先进后出。
- 大小受限:栈的大小受限于操作系统设置。
- 访问受限:只能在当前函数或作用域内进行访问。
堆
堆是另一种内存管理方式。内存管理对操作系统来说相当复杂,一方面是因为内存容量本身很大,另一方面,内存需求在时间和大小上毫无规律。操作系统中运行着大量进程,它们随时可能申请或释放任意大小的内存块。
堆这种管理方式的特点就是“自由”:随时申请、随时释放、大小随意。堆内存被操作系统划归给堆管理器管理,堆管理器提供了底层的接口(如 _sbrk, _mmap),这些接口通常由运行时库(如 Linux 下的 glibc)进行封装和调用。换句话说,运行时库负责堆内存管理,它向开发者提供 malloc/free 等函数来间接使用堆内存。
分配方式
正如我们的理解,由于内存分配发生在运行期,分配的大小也要等到运行期才知道,所以堆只支持 动态分配。内存的申请和释放行为完全交由开发者自行操作,这也就极易引发我们所说的内存泄漏。
特点
- 变量可在进程范围内访问,即进程内的所有线程都可以访问该变量。
- 没有严格的内存大小限制。这其实是相对栈而言的,最终还是会受限于物理内存(RAM)的大小。
- 相对于栈,访问速度较慢。
- 会产生内存碎片。
- 完全由开发者管理内存,即内存的申请和释放全由人来控制。
堆与栈区别
理解堆和栈的区别,对我们的开发工作裨益极大。结合上文,我们来总结一下它们的不同点。
对于栈,它由编译器自动管理,无需我们手工控制;而对于堆,释放工作由程序员掌控,也因此更容易产生内存泄漏。
- 空间大小不同
- 一般来讲,在32位系统下,堆内存可以达到3GB的空间,从这点来看,堆内存几乎没有限制。
- 栈通常都有一定的空间上限,一般依赖于操作系统(也可以人工设置)。
- 能否产生碎片不同
- 对于堆,频繁的内存分配和释放势必会造成内存空间的不连续,产生大量碎片,降低程序效率。
- 对于栈,内存是连续的,申请和释放都是指令移动,类似数据结构中的
进栈和出栈。
- 增长方向不同
- 堆的生长方向是向上的,即向着内存地址增大的方向。
- 栈的生长方向是向下的,即向着内存地址减小的方向。
- 分配方式不同
- 堆都是动态分配的,例如我们常用的
malloc/new;而栈则同时支持静态分配和动态分配两种。
- 静态分配由编译器完成,比如局部变量的分配;栈的动态分配则通过
alloca() 函数完成。
- 两者的动态分配截然不同:栈动态分配的内存由编译器去释放,而堆动态分配的内存则必须由开发者自行释放。
- 分配效率不同
- 操作系统会分配专门的寄存器来存放栈的地址,压栈出栈都有专门的指令执行,这决定了栈的效率极高。
- 堆内存的申请和释放,则依靠运行时库提供的函数,内部逻辑复杂,申请和释放效率都低于栈。
讲到这里,栈和堆的基本特性、优缺点以及使用场景已分析完毕。在此给开发者一个建议:能使用栈的时候,就尽量使用栈。一方面是因为效率高于堆;另一方面,内存的申请和释放全权由编译器完成,能避免大量人为导致的问题。
扩展
说了这么多,其实都在为这一小节做铺垫。前面我们对比了栈和堆,虽然栈效率高,且不存在内存泄漏、内存碎片等问题,但它自身的局限性(无法跨线程共享、大小受限),使得在很多场景下,我们仍不得不在堆上分配内存。
先来看一段简单的代码:
#include <stdio.h>
#include <stdlib.h>
int main() {
int a;
int *p;
p = (int *)malloc(sizeof(int));
free(p);
return 0;
}
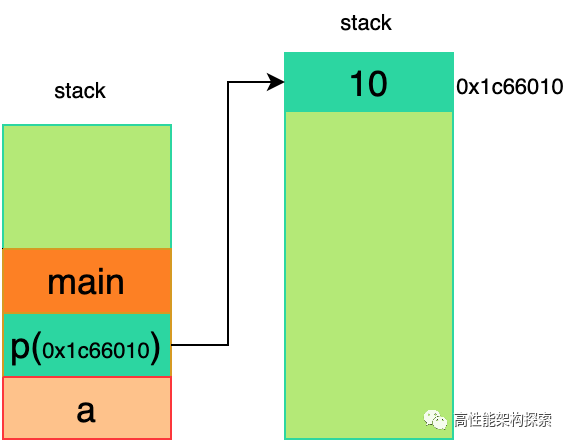
代码很简单,两个变量 a 和 p,类型分别是 int 和 int *。其中,a 和 p 都存储在栈上,而 p 的值是堆上的某块地址(例如 0x1c66010)。上述代码的内存布局如下图所示:
产生方式
按照产生的模式来分类,内存泄漏大致可以分为以下四类:
- 常发性内存泄漏
- 偶发性内存泄漏
- 一次性内存泄漏
- 隐式内存泄漏
常发性内存泄漏
产生泄漏的代码或函数会被多次执行到,每次执行的时候,都忠实地产生一次内存泄漏。
偶发性内存泄漏
与 常发性内存泄漏 不同,偶发性泄漏的函数只在某些特定场景下才会被执行。
笔者在19年就曾遇到过这样一个棘手的案例。有一个函数专门负责价格加密,每次调用会泄漏3个字节的内存。更要命的是,它只在竞价成功的场景下才会被调用,因此泄漏得非常隐蔽。发现这个问题是在上线的第二天,当时帮忙排查线上问题,注意到内存相比上线前上涨了几百兆。了解 glibc 内存分配原理的人都清楚,调用 delete 后,内存不一定会立刻归还给操作系统。但本着“宁可信其有,不可信其无”的态度,我们决定深入分析是否存在真实的内存泄漏。
当时采用了一个比较“土”的方法:写脚本用 top 命令定时将该进程的内存占用输出到本地文件。大概几个小时后,将这些数据导入 Excel 生成图表,发现内存占用基本呈一条稳定上升的斜线。这基本能确定代码存在内存泄漏。于是,我们立刻对新上线的这部分代码进行重新 review,最终定位到泄漏点,修复后重新上线。
一次性内存泄漏
这种内存泄漏在程序的生命周期内只会发生一次,或者说,造成泄漏的代码只会被执行一次。
严格来说,有些情况可能不算内存泄漏,而是“设计如此”。以笔者现在线上运行的服务为例,模式类似于这样:
int main() {
auto *service = new Service;
// do sth
service->Run();// 服务启动
service->Loop(); // 可以理解为一个sleep,目的是使得程序不退出
return 0;
}
从最严格的意义上讲,这不算内存泄漏,因为程序就是这么设计的。即使程序异常退出,整个服务进程也会跟着退出。当然,在 Loop() 后面加上一句 delete service 会更好。
隐式内存泄漏
程序在运行过程中不停地分配内存,但直到程序结束才统一释放。严格来说,这并没有发生内存泄漏,因为程序最终释放了所有申请的内存。但是,对于一个需要运行几天、几周甚至几个月的服务端程序来说,不及时释放内存很可能最终耗尽系统所有内存。因此,我们称这类现象为隐式内存泄漏。
比较常见的隐式内存泄漏有以下几种:
- 内存碎片:程序跑了几天后,进程可能就因为 OOM 退出了。原因正是内存碎片导致剩余的空闲内存无法被有效分配。
- 运行时库未归还内存:即使我们调用了
free/delete,运行时库也不一定会立刻将内存归还给操作系统。
- STL 的 Allocator 机制:用过 STL 的同学都知道,其内部有自己的 allocator,可以理解为一个 memory pool。当调用
vector.clear() 时,内存并不会直接归还操作系统,而是先回收到 allocator 中。allocator 内部会根据一定的策略,在特定时机才将内存归还给 OS。这套路是不是跟 glibc 的原理很像?😁
分类(常见原因)
上一节按产生模式分了类,这一节我们聚焦于产生内存泄漏的具体技术原因。
未释放
这是最常见的一种,例如下面这段代码:
int fun() {
char * pBuffer = malloc(sizeof(char));
/* Do some work */
return 0;
}
我们在 fun 函数内申请了一块内存,但在函数结束时却忘了调用 free 进行释放。(使用 new 分配同理)
在 C++ 开发中,还有另一种常见的泄漏场景:
class Obj {
public:
Obj(int size) {
buffer_ = new char;
}
~Obj(){}
private:
char *buffer_;
};
int fun() {
Object obj;
// do sth
return 0;
}
这段代码中,析构函数完全没有释放成员变量 buffer_ 指向的内存。所以,在编写析构函数时,务必要仔细分析成员变量是否申请了动态内存。如果有,则必须手动释放。我们重新编写一下析构函数:
~Object() {
delete buffer_;
}
在C/C++中,无论是普通函数还是类,只要申请了堆资源,就请务必根据代码场景,调用 free/delete 进行释放。
未匹配
在C++中,我们常用 new 操作符进行内存分配,其内部主要做两件事:
- 通过
operator new 从堆上申请内存(在 glibc 下,operator new 底层调用的正是 malloc)。
- 调用构造函数(如果操作对象是一个类的话)。
相应地,使用 delete 操作符来释放内存,其顺序正好与 new 相反:
- 调用对象的析构函数(如果操作对象是一个类的话)。
- 通过
operator delete 释放内存。
void* operator new(std::size_t size) {
void* p = malloc(size);
if (p == nullptr) {
throw("new failed to allocate %zu bytes", size);
}
return p;
}
void* operator new[](std::size_t size) {
void* p = malloc(size);
if (p == nullptr) {
throw("new[] failed to allocate %zu bytes", size);
}
return p;
}
void operator delete(void* ptr) throw() {
free(ptr);
}
void operator delete[](void* ptr) throw() {
free(ptr);
}
为了加深理解,再看个例子:
class Test {
public:
Test() {
std::cout << "in Test" << std::endl;
}
// other
~Test() {
std::cout << "in ~Test" << std::endl;
}
};
int main() {
Test *t = new Test;
// do sth
delete t;
return 0;
}
在 main 函数中,当我们 new 一个对象时,过程如下:先通过 operator new 申请内存,再通过 placement new 在这块内存上调用构造函数。而 delete 一个对象时,过程正好相反:先调用其析构函数,再通过 operator delete 释放内存。
这个逻辑可以简化理解为:
// new
void *ptr = malloc(sizeof(Test));
t = new(ptr)Test
// delete
ptr->~Test();
free(ptr);
new 和 free
还是以上面的 Test 对象为例:
Test *t = new Test;
free(t)
这会产生内存泄漏。因为 free 只释放了内存,却没有调用 Test 的析构函数,从而导致 Test 内部的成员变量(如果有堆资源)无法释放,引发 内存泄漏。
new[] 和 delete
int main() {
Test *t = new Test [10];
// do sth
delete t;
return 0;
}
这段代码中,我们通过 new[] 创建了一个 Test 类型的数组,却用 delete 去释放。编译并执行后,你会看到调用了10次构造函数,但只调用了1次析构函数。这是因为 delete t 只调用了 t[0] 的析构函数,t[1..9] 的析构函数完全没被调用,从而引起 内存泄漏。
虚析构
这个问题非常经典。记得08年面谷歌时,有一道题;面试官问:std::string 能否被继承?为什么?
当时没答出来,后来复盘时才恍然大悟,考察点在于,继承要求父类的析构函数必须是 virtual 的。
看看 std::string 的析构函数定义:
~basic_string() {
_M_rep()->_M_dispose(this->get_allocator());
}
需要说明一下,std::basic_string 是一个 Templates,而 std::string 是它的一个特化。
typedef std::basic_string<char> string;
现在可以给出答案了:不能。 因为 std::string 的析构函数不是虚函数,这会导致 内存泄漏。
用一个例子来证明:
class Base {
public:
Base(){
buffer_ = new char[10];
}
~Base() {
std::cout << "in Base::~Base" << std::endl;
delete []buffer_;
}
private:
char *buffer_;
};
class Derived : public Base {
public:
Derived(){}
~Derived() {
std::cout << "int Derived::~Derived" << std::endl;
}
};
int main() {
Base *base = new Derived;
delete base;
return 0;
}
上面代码的输出是:
in Base::~Base
可见,它并没有调用派生类 Derived 的析构函数。如果派生类中在堆上申请了资源,就会产生 内存泄漏。
解决方法很简单,将父类的析构函数声明为 virtual:
virtual ~Base() {
std::cout << "in Base::~Base" << std::endl;
delete []buffer_;
}
重新执行后,结果正常:
int Derived::~Derived
in Base::~Base
借此,我们再次总结存在继承关系时,构造和析构的调用顺序。
派生类对象创建时,构造函数调用顺序为:先父类,再父类成员变量,最后派生类自身。
派生类对象析构时,析构函数调用顺序为:先派生类自身,再派生类成员变量,最后父类。
为了避免继承导致的内存泄漏,请遵守一条铁律:无论派生类有没有申请堆资源,请务必将父类的 析构函数声明为virtual。
循环引用
为了尽可能避免内存泄漏,C++11 起引入了 smart pointer 体系,常见的包括 unique_ptr、shared_ptr 和 weak_ptr。其中,weak_ptr 正是为了打破循环引用而生的,它通常与 shared_ptr 配合使用。
看一段典型的循环引用代码:
class Controller {
public:
Controller() = default;
~Controller() {
std::cout << "in ~Controller" << std::endl;
}
class SubController {
public:
SubController() = default;
~SubController() {
std::cout << "in ~SubController" << std::endl;
}
std::shared_ptr<Controller> controller_;
};
std::shared_ptr<SubController> sub_controller_;
};
int main() {
auto controller = std::make_shared<Controller>();
auto sub_controller = std::make_shared<Controller::SubController>();
controller->sub_controller_ = sub_controller;
sub_controller->controller_ = controller;
return 0;
}
编译执行这段代码,你会发现 Controller 和 SubController 的析构函数都没有被调用。打印一下引用计数就能明白原因:
int main() {
auto controller = std::make_shared<Controller>();
auto sub_controller = std::make_shared<Controller::SubController>();
controller->sub_controller_ = sub_controller;
sub_controller->controller_ = controller;
std::cout << "controller use_count: " << controller.use_count() << std::endl;
std::cout << "sub_controller use_count: " << sub_controller.use_count() << std::endl;
return 0;
}
输出为:
controller use_count: 2
sub_controller use_count: 2
两者的引用计数均为2,所以在 main 函数结束时,计数无法归零,它们的析构函数自然不会被调用,这就造成了典型的 内存泄漏。
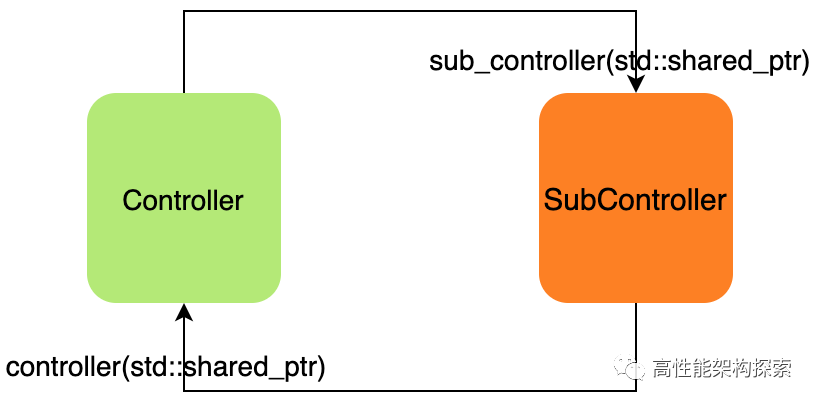
这种由 循环引用 引起的泄漏,解决方案是使用 std::weak_ptr 来切断图中的循环回路。
class Controller {
public:
Controller() = default;
// ... 其他代码
class SubController {
public:
// ... 其他代码
std::weak_ptr<Controller> controller_; // 改为weak_ptr
};
std::shared_ptr<SubController> sub_controller_;
};
这里我们将 SubController 中 controller_ 的类型从 shared_ptr 改为了 weak_ptr。重新编译执行,结果变为:
controller use_count: 1
sub_controller use_count: 2
in ~Controller
in ~SubController
可以看到,对象已能正常释放,循环引用 导致的内存泄漏问题得以解决。
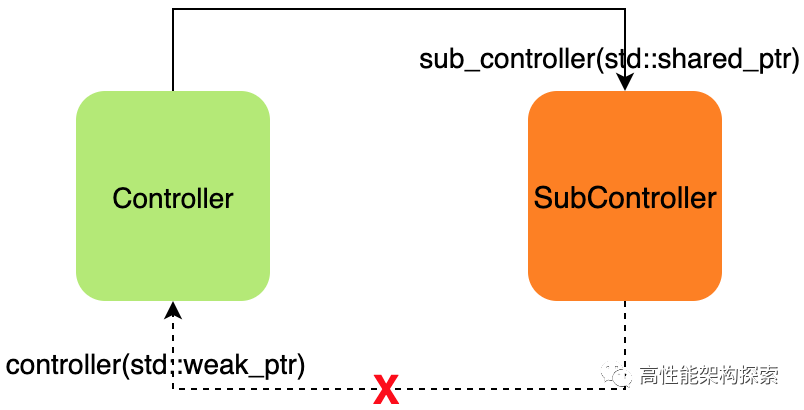
你可能会问,用 shared_ptr 能直接访问成员函数,换成 weak_ptr 后怎么访问呢?很简单,像下面这样:
std::shared_ptr controller = controller_.lock();
在 SubController 内部,如果想通过 controller 变量调用其相关函数,先用 lock() 方法获取一个临时的 shared_ptr 即可。
避免
避免在堆上分配
不夸张地说,绝大部分内存泄漏都源于堆分配。但反过来说,如果我们能不在堆上分配,内存泄漏自然就不复存在了。这听起来像句废话,但确实是最根本的原则。只要使用场景允许,应尽量在栈上创建对象。一方面栈的效率远高于堆,另一方面,它还能天然规避内存泄漏,何乐而不为呢?
手动释放
- 对于用
malloc 分配的内存,结束时务必用 free 进行释放。
- 对于用
new 操作符创建的对象,切记用 delete 释放。
- 对于用
new[] 创建的对象,必须用 delete[] 释放,使用 free 或 delete 都会造成内存泄漏。
避免使用裸指针
应尽量避免使用裸指针,除非不得不调用那些只接受裸指针的第三方库或合作部门接口。
int fun(int *ptr) {// fun 是一个接口或lib函数
// do sth
return 0;
}
int main() {
int a = 1000;
int *ptr = &a;
// ...
fun(ptr);
return 0;
}
在上面的 fun 函数中,参数是一个 int *,我们需要根据上下文去猜测这个指针是否需要被释放。这无疑是一种 很不好的设计。
使用STL中或者自己实现对象
C++ 提供了相对完善且可靠的标准库。能用 STL 的地方,就尽量摒弃 C 风格的编程方式。比如:
- 使用
std::string 替代 char*。string 类自己会进行卓越的内存管理。
- 使用
std::vector 或者 std::array 来替代传统数组。
- 其他任何适合你使用场景的标准库对象。
智能指针
自 C++11 起,标准库引入了智能指针来动态管理资源,并针对不同场景提供了三种主要的智能指针。
unique_ptr
unique_ptr 是限制最严格的一种,它独享所管理对象指针的所有权。当 unique_ptr 对象销毁时,它会在自己的析构函数内自动删除关联的原始指针。
它大致分为两类:
它不可被复制,但能通过移动语义转移所有权。
unique_ptr<int> a(new int(0));
unique_ptr<int> b = a; // 编译错误
unique_ptr<int> b = std::move(a); // 可以通过move语义进行所有权转移
利用它可以很优雅地避免内存泄漏:
void fun() {
unique_ptr<int> a(new int(0));
// use a
}
当 fun 函数结束时,a 的析构函数会被自动调用,从而释放其关联的指针。
shared_ptr
与 unique_ptr 的“独占”不同,shared_ptr 是“共享”管理权。多个 shared_ptr 可以共用同一块关联对象。其内部采用引用计数机制:每当一个 shared_ptr 被拷贝,引用计数就加1;每当一个 shared_ptr 退出作用域或被释放,引用计数就减1。当计数降为0时,它便会自动释放其所管理的对象。
void fun() {
std::shared_ptr<Type> a; // a是一个空对象
{
std::shared_ptr<Type> b = std::make_shared<Type>(); // 分配资源
a = b; // 此时引用计数为2
{
std::shared_ptr<Type> c = a; // 此时引用计数为3
} // c退出作用域,此时引用计数为2
} // b 退出作用域,此时引用计数为1
} // a 退出作用域,引用计数为0,释放对象
weak_ptr
weak_ptr 的出现,正是为了解决 shared_ptr 的 循环引用 难题,它总是与 shared_ptr 搭档使用。与 shared_ptr 不同,weak_ptr 并不拥有资源的所有权,因此它不能直接访问对象提供的成员函数。不过,正如前文所述,可以通过 weak_ptr.lock() 方法来产生一个临时的、拥有访问权的 shared_ptr。
std::weak_ptr<Type> a;
{
std::shared_ptr<Type> b = std::make_shared<Type>();
a = b
} // b所对应的资源释放
RAII
RAII 是 Resource Acquisition Is Initialization 的缩写,是 C++ 语言中一种极具代表性的资源管理技术,用于规避泄漏风险。
它的核心理念是利用 C++ 对象的生命周期。做法就是使用一个对象,在其构造时获取相应的资源,在对象的生命周期内控制对资源的访问并始终保证其有效,最后在对象析构的时候,自动释放所获取的资源。
简单说,就是把资源的使用范围牢牢锁定在对象的生命周期之中,实现自动释放。
举个多线程编程中常见的例子,使用 std::mutex:
std::mutex mutex_;
void fun() {
mutex_.lock();
if (...) {
mutex_.unlock();
return;
}
mutex_.unlock()
}
如果分支很多,很容易在某处忘记释放锁,从而造成死锁。用 RAII 技术来解决这个问题就清爽多了:
std::mutex mutex_;
void fun() {
std::lock_guard<std::mutex> guard(mutex_);
if (...) {
return;
}
}
当 guard 对象离开 fun 作用域时,其析构函数会自动调用 mutex_.unlock() 进行释放,从而避免了大量潜在问题。
定位
发现内存泄漏之后,定位泄漏点往往才是最困难的一步。为了定位,大家都会采取各种各样的方案,甭管方案优雅不优雅,毕竟,“管他白猫黑猫,抓住老鼠才是好猫”。这一节,就简单分享下笔者这些年用过的定位方法,有些路子可能比较野,权当参考。
日志
这种方案的核心思想是:在每次分配内存时,打印出指针的地址;在每次释放内存时,也打印出指针地址。在程序运行结束前,通过对比分配和释放的匹配情况,如果分配次数大于释放次数,基本就能断定存在内存泄漏,再根据日志进行详细定位。
char * fun() {
char *p = (char*)malloc(20);
printf("%s, %d, address is: %p", __FILE__, __LINE__, p);
// do sth
return p;
}
int main() {
fun();
return 0;
}
统计
统计法可以被看作是日志法的一种特殊实现。它的主要原理是:在分配时,对一个全局计数器进行递增操作;在释放时,进行递减操作。在程序结束前检查这两个值是否一致,即可判断是否存在内存泄漏。
static unsigned int allocated = 0;
static unsigned int deallocated = 0;
void *Memory_Allocate (size_t size)
{
void *ptr = NULL;
ptr = malloc(size);
if (NULL != ptr) {
++allocated;
} else {
//Log error
}
return ptr;
}
void Memory_Deallocate (void *ptr) {
if(pvHandle != NULL) {
free(ptr);
++deallocated;
}
}
int Check_Memory_Leak(void) {
int ret = 0;
if (allocated != deallocated) {
//Log error
ret = MEMORY_LEAK;
} else {
ret = OK;
}
return ret;
}
工具
在 Linux 平台下,最常用的内存泄漏检测工具莫过于 valgrind 了。我们就用它来进行演示。
先准备一段有泄漏的代码:
#include <stdlib.h>
void func (void){
char *buff = (char*)malloc(10);
}
int main (void){
func(); // 产生内存泄漏
return 0;
}
- 首先,通过
gcc -g leak.c -o leak 命令进行编译。
- 然后,执行
valgrind --leak-check=full ./leak。
执行后,会输出类似以下的内容:
==9652== Memcheck, a memory error detector
==9652== Copyright (C) 2002-2017, and GNU GPL'd, by Julian Seward et al.
==9652== Using Valgrind-3.15.0 and LibVEX; rerun with -h for copyright info
==9652== Command: ./leak
==9652==
==9652==
==9652== HEAP SUMMARY:
==9652== in use at exit: 10 bytes in 1 blocks
==9652== total heap usage: 1 allocs, 0 frees, 10 bytes allocated
==9652==
==9652== 10 bytes in 1 blocks are definitely lost in loss record 1 of 1
==9652== at 0x4C29F73: malloc (vg_replace_malloc.c:309)
==9652== by 0x40052E: func (leak.c:4)
==9652== by 0x40053D: main (leak.c:8)
==9652==
==9652== LEAK SUMMARY:
==9652== definitely lost: 10 bytes in 1 blocks
==9652== indirectly lost: 0 bytes in 0 blocks
==9652== possibly lost: 0 bytes in 0 blocks
==9652== still reachable: 0 bytes in 0 blocks
==9652== suppressed: 0 bytes in 0 blocks
==9652==
==9652== For lists of detected and suppressed errors, rerun with: -s
==9652== ERROR SUMMARY: 1 errors from 1 contexts (suppressed: 0 from 0)
valgrind 把内存泄漏分成了几类:
definitely lost: 确定产生了内存泄漏。indirectly lost: 间接产生内存泄漏。possibly lost: 可能存在内存泄漏。still reachable: 程序结束时仍有指针指向该内存块,常见于全局变量。
我们最关注的是这几行输出:
==9652== by 0x40052E: func (leak.c:4)
==9652== by 0x40053D: main (leak.c:8)
它清晰地提示了 main 函数(leak.c第8行)调用的 func 函数(leak.c第4行)产生了内存泄漏。分析代码后,问题就能迅速定位并解决。
Valgrind 的功能远不止于此,因为本文聚焦内存泄漏,其它功能就不再赘述了,有兴趣的话可以通过 valgrind --help 来查阅。
对于 Windows 下的内存泄漏检测工具,我特别想推荐一款轻量级但功能异常强大的工具 UMDH。十几年前,我曾在一家外企负责排查一个数百万行代码项目的内存泄漏,光编译就要两个小时,尝试了各种收费的、免费的工具后,最终发现了UMDH这个神器。如果你在 Windows 平台上搞开发,强烈推荐用它试试。
经验之谈
在C/C++的开发旅程中,内存泄漏几乎是难以绕开的常客。见到它不用过于焦虑,毕竟它的即时破坏性远低于 coredump 之类的问题,大不了,重启一下嘛😁。
不过,养成良好的开发习惯,足以帮你规避掉 90% 以上的此类问题:
- 养成良好的编程习惯,只要写了
malloc/new,就要立刻想好它的 free/delete 该放在哪里。
- 尽可能使用智能指针,它们正是为了解决内存泄漏而生。
- 善用 log 进行关键点记录。
- 最重要的一点,
谁申请,谁释放。
最后再补充一点,对于 malloc 分配失败,返回值是 NULL,程序可以直接退出处理了。而对于 new 分配失败,它会抛出一个 std::bad_alloc 异常。为了能第一时间暴露问题,建议不要对此类异常进行 catch。毕竟,内存都已经分配失败了,程序也失去了继续运行的意义。
如果上线后才发现内存泄漏,如果情况不严重,可以先稳住线上服务,同时紧锣密鼓地排查;如果泄漏很严重,那就需要根据情况第一时间决定是否回滚。在定位问题时,可以采用 缩小范围法,重点审视这次变更新增的代码,这能显著缩短问题解决的时间。
结语
C/C++ 之所以复杂且高效,核心就在于其灵活性,允许开发者直接与操作系统的 API 交互。但成也萧何,败也萧何,正是这份灵活性,让它更容易出问题。团队成员必须愿意遵循一定的开发规范,并建立起完整的 code review 机制,力争将问题消灭在上线之前。只有这样,我们才能把宝贵的精力放在业务本身,而不是耗费大量时间去定位排查这些本可避免的疑难杂症。
好了,本期的分享就到这里,我们下期见!
参考
 发表于 2026-4-24 18:54:05
|
查看: 140|
回复: 0
发表于 2026-4-24 18:54:05
|
查看: 140|
回复: 0
