书接上文内存排查第一步:停止迷信 free。
在上一篇文章中,我们提到了几种检测内存问题的手段。如果到了这一步还没能解决内存增长,那么本文的主角——OOM就该登场了。
当 OOM killer 被触发,它的行为绝不是随机抽奖;这是内核最后的“保命机制”。
我们可以通过下面这条命令查看完整的内核日志细节:
journalctl -k | grep -A 30 "Out of memory"
这条命令会输出三大关键信息,相当于内核决策前的“现场取证快照”:
- 故障发生时的系统内存状态
- 每个进程的内存使用情况
- 内核选择杀死某个进程的底层逻辑
比如,我本机的输出是这样的:
Out of memory: Kill process 30449 (xxx) score 435 or sacrifice child
kernel: Killed process 30449 (xxx), UID 0, total-vm:4907316kB, anon-rss:3589616kB, file-rss:788kB, shmem-rss:0kB
kernel: brand_bmss_serv invoked oom-killer: gfp_mask=0x201da, order=0, oom_score_adj=0
kernel: brand_bmss_serv cpuset=/ mems_allowed=0
kernel: CPU: 3 PID: 14357 Comm: brand_bmss_serv Kdump: loaded Not tainted 3.10.0-1160.6.1.el7.x86_64 #1
kernel: Hardware name: OpenStack Foundation OpenStack Nova, BIOS rel-1.10.2-0-g5f4c7b1-20240428_141054-szxrtosci10000 04/01/2014
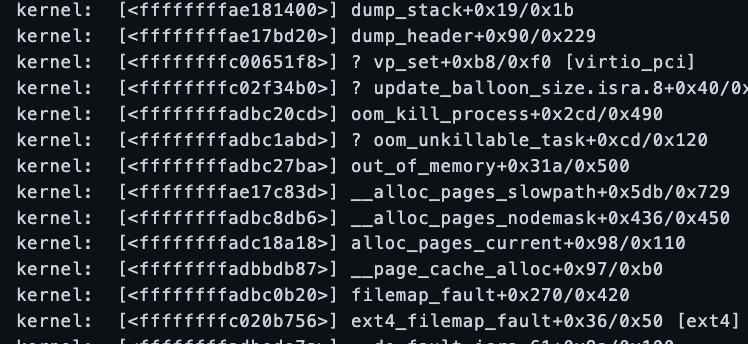
kernel: Call Trace:
kernel: [<ffffffffae181400>] dump_stack+0x19/0x1b
kernel: [<ffffffffae17bd20>] dump_header+0x90/0x229
kernel: [<ffffffffc00651f8>] ? vp_set+0xb8/0xf0 [virtio_pci]
kernel: [<ffffffffc02f34b0>] ? update_balloon_size.isra.8+0x40/0x60 [virtio_balloon]
kernel: [<ffffffffadbc20cd>] oom_kill_process+0x2cd/0x490
kernel: [<ffffffffadbc1abd>] ? oom_unkillable_task+0xcd/0x120
kernel: [<ffffffffadbc27ba>] out_of_memory+0x31a/0x500
kernel: [<ffffffffae17c83d>] __alloc_pages_slowpath+0x5db/0x729
kernel: [<ffffffffadbc8db6>] __alloc_pages_nodemask+0x436/0x450
kernel: [<ffffffffadc18a18>] alloc_pages_current+0x98/0x110
kernel: [<ffffffffadbbdb87>] __page_cache_alloc+0x97/0xb0
kernel: [<ffffffffadbc0b20>] filemap_fault+0x270/0x420
kernel: [<ffffffffc020b756>] ext4_filemap_fault+0x36/0x50 [ext4]
kernel: [<ffffffffadbede7a>] __do_fault.isra.61+0x8a/0x100
kernel: [<ffffffffadbee42c>] do_read_fault.isra.63+0x4c/0x1b0
kernel: [<ffffffffadbf5c70>] handle_mm_fault+0xa20/0xfb0
kernel: [<ffffffffae18f653>] __do_page_fault+0x213/0x500
kernel: [<ffffffffae18fa26>] trace_do_page_fault+0x56/0x150
kernel: [<ffffffffae18efa2>] do_async_page_fault+0x22/0xf0
kernel: [<ffffffffae18b7a8>] async_page_fault+0x28/0x30
kernel: Mem-Info:
kernel: active_anon:1788752 inactive_anon:45648 isolated_anon:0
active_file:4635 inactive_file:4633 isolated_file:0
unevictable:0 dirty:932 writeback:135 unstable:0
kernel: Out of memory: Kill process 30450 (xxx) score 436 or sacrifice child
kernel: Killed process 30450 (xxx), UID 0, total-vm:4907316kB, anon-rss:3592852kB, file-rss:1096kB, shmem-rss:0kB
可能有人会问:我如何知道哪个进程更可能触发 OOM?
可以用下面这个脚本,遍历所有进程并打印它们的 OOM 分数:
for pid in /proc/[0-9]*; do
score=$(cat $pid/oom_score 2>/dev/null)
name=$(cat $pid/comm 2>/dev/null)
echo "$score $name $pid"
done | sort -rn | head -15
内核会给每个进程分配一个 oom_score,分数越高,被杀死的几率就越大。
输出示例:
254 xxx /proc/28758
202 yyy /proc/20387
13 xxx /proc/4932
12 java /proc/726
12 aaa /proc/4830
8 gunicorn /proc/18002
8 gunicorn /proc/18001
8 gunicorn /proc/18000
8 gunicorn /proc/17999
可见进程 28758 对 OOM 的风险最高。
如果你有绝对不能被杀的核心服务,可以通过 oom_score_adj 调整权重,让内核“放它一马”或反过来让它成为优先目标:
# 保护核心进程,使其永远不会被 OOM killer 杀死(-1000 = 永不杀死)
echo -1000 > /proc/<PID>/oom_score_adj
# 让非核心进程成为 OOM 优先杀死目标(+1000 = 优先杀死)
echo 1000 > /proc/<PID>/oom_score_adj
取值范围很直观:
-1000 —— 永不杀死 0 —— 默认行为 +1000 —— 优先被牺牲
如果保护过多进程,内核可能会被迫杀死更关键的进程(比如系统核心服务),反而加剧故障。
除了加权护航,我们还能通过调整 vm.overcommit 来从根源上防止内存溢出。
Linux 允许进程申请的内存超过系统实际可用的物理内存,这种行为称为“内存过度提交(memory overcommit)”。有时候它能正常工作,有时却会把雷埋到最后一起炸。我们可以用 vm.overcommit_memory 收紧这个策略:
cat /proc/sys/vm/overcommit_memory
有三种取值:
0:启发式(默认)—— 内核会估算内存分配是否安全,倾向放行 1:始终过度提交 —— 什么申请都答应(风险极高,容易触发 OOM) 2:严格过度提交 —— 超过设定上限的申请一律拒绝(最可控)
推荐改成严格模式,并设置一个合理的比例:
sysctl vm.overcommit_memory=2
sysctl vm.overcommit_ratio=80
在 mode=2 下,Linux 会强制执行硬上限,计算公式为:
CommitLimit(分配上限)=(物理内存 × 过度提交比例 / 100)+ 交换分区(Swap)
举个例子:假设机器配置 32GB 物理内存 + 8GB Swap,过度提交比例设为 80,则:
可分配内存上限 ≈(32 × 0.8)+ 8 = 33.6GB
超过这个数,新的内存请求会直接失败,而不是等天长日久再触发 OOM 杀进程,更利于提前排查。
可以用这条命令随时查看内存提交是否逼近红线:
grep Commit /proc/meminfo
示例输出:
CommitLimit: 33423360 kB
Committed_AS: 22020096 kB
其中:
CommitLimit:系统允许分配的最大内存(也就是上面的上限) Committed_AS:所有进程已经伸手要过的内存总量(内核承诺拨付的部分)
在严格模式下,一旦 Committed_AS 超过 CommitLimit,新的分配请求会被果断拒绝。
但有时内存压力并不来自泄漏或峰值,而是透明大页(Transparent Huge Pages,THP)。THP 是内核的一项特性,用更大的内存页(2MB 而非默认的 4KB)来减少 TLB 未命中,提升性能。多数发行版默认开启,但它经常给数据库类应用(Redis、PostgreSQL、MongoDB 都建议禁用)带来莫名其妙的延迟飙升和内存膨胀,甚至导致难以追踪的异常内存使用模式。
cat /sys/kernel/mm/transparent_hugepage/enabled
# Output:
[always] madvise never
三种选项:
always:所有进程都已启用 THP madvise:只有应用程序主动申请时才启用 never:完全禁用 THP
对性能要求高的系统应避开 always。可通过下面命令查看大页的实际占用状况:
grep -E "AnonHugePages|HugePages" /proc/meminfo
输出示例:
AnonHugePages: 446464 kB
HugePages_Total: 0
HugePages_Free: 0
HugePages_Rsvd: 0
HugePages_Surp: 0
AnonHugePages:当前由 THP 占据的内存,数值大说明 THP 正在积极使用 HugePages_Total:手动预留的静态 HugeTLB 大页数量 HugePages_Free:剩余未被使用的预留大页 HugePages_Rsvd:已经预约但尚未实际占用的大页 HugePages_Surp:超出配置数量的额外大页
最后来说说交换分区。Swap 是内存不足时的最后底牌,但和所有安全网一样,如果自己整天往下掉,说明上面一定有坑。我们的目标不是“零 Swap 使用”,而是可控、可预测的 Swap 行为。健康的 Swap 应该是“安静且无波澜”的,如果它变得活跃且频繁读写,上游一定有问题:
- Swap 使用量稳定 —— 正常
- Swap 持续增长 —— 存在内存压力
- 系统频繁换入换出 —— 内存配置不足或有泄漏
下面这个脚本可以揪出哪些进程正在大量使用 Swap:
for pid in /proc/[0-9]*/status; do
name=$(awk '/^Name:/{print $2}' $pid)
swap=$(awk '/^VmSwap:/{print $2}' $pid)
[ "${swap:-0}" -gt 1024 ] && echo "${swap} kB $name"
done 2>/dev/null | sort -rn | head -10
输出可能长这样:
2097152 kB java
524288 kB python3
65536 kB postgres
真正的线上稳定性,从来不是等 OOM 发生后再救火,而是提前看懂内核的信号、管好内存的边界、避开那些看不见的坑。在云栈社区,许多运维同行都在分享这类生产环境的排障经验。
看懂日志、预判风险、守住底线、保护核心——这才是一个成熟工程师面对内存危机时最该有的底气。愿我们的服务永远稳定运行,再无突如其来的 OOM。
 发表于 2026-4-24 18:58:39
|
查看: 186|
回复: 0
发表于 2026-4-24 18:58:39
|
查看: 186|
回复: 0
