同样是查东西,为什么有人1秒,有人要1小时?
今天想和大家聊一个所有程序员都绕不开,但初学者往往一脸懵的概念——时间复杂度。别被这个名词吓到,其实它就在我们身边。看完今天这篇文章,你不仅能看懂这些“天书”符号,还能在下次讨论技术方案时,清晰地分析出不同做法的效率差异。
一、先搞懂:O() 到底是什么?
想象你要在一个书架上找一本书。我们找书的具体方法(比如一本本找,或者先分类再找),其实就是算法。而 O(),就是用来评价这个算法效率高低的评分标准。
这个评分标准看的不是“具体耗时几秒”,而是随着书的数量变多,你找书的时间会怎么变化。如果书架上只有10本书,什么方法都快。但如果有10万本书,有的方法还是很快,有的方法就会慢到让你怀疑人生。O() 就是用来描述这种“抗压能力”的数学符号。
下面我们用找东西的场景,把这四种效率挨个讲明白。
二、O(1) —— 效率之王,“瞬间移动”
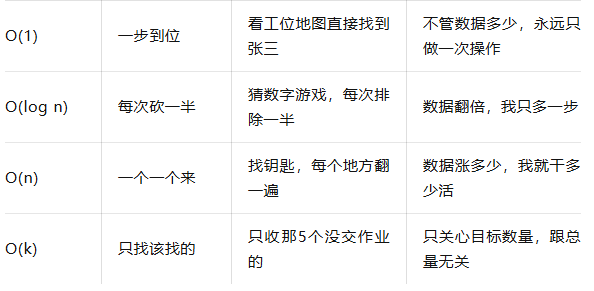
O(1) 的意思是:不管数据有多少,我都能一步到位。
生活场景
假设公司有1000个工位,每个工位上都贴着员工的名字。你想找张三。最高效的方法是什么?公司发了一张工位地图,地图上直接标着“张三 → 工位号 3-205”。你看一眼地图,一步到位,直接走到那个工位。
计算机场景:哈希查找
在代码里,有一种数据结构叫哈希表(比如 JavaScript 里的对象、C# 里的字典)。
# 假设我们存了员工信息
staff = {
"张三": "工位 3-205",
"李四": "工位 2-101",
# ... 还有998个人
}
# 找张三
position = staff["张三"] # 瞬间拿到结果,不管staff有多大
这就是 O(1):数据量从1000变成100万,查找时间完全不变,永远是瞬间。
三、O(log n) —— 效率亚军,“每次排除一半”
O(log n) 的意思是:每次操作都排除一半,数据翻倍我也不怕。
生活场景
朋友说:“我心里想了一个1到100之间的数字,你来猜,我告诉你‘大了’还是‘小了’。”
普通人的笨办法是从1开始猜:1?小了。2?小了。3?小了……这是 O(n)。
聪明人的办法是:50?大了。25?小了。37?小了。43?大了。40?对了!
每次猜完,剩下的范围就减少一半。100个数最多猜7次,1000个数最多猜10次,100万个数最多猜20次。这就是 O(log n)。
计算机场景:二分查找
在有序数组里找一个数,用的就是这种二分查找方法。
# 在有序数组里找66
arr = [2, 5, 8, 12, 19, 23, 34, 45, 56, 66, 78, 89]
# 二分查找的过程:
# 1. 看中间的数 34,66比34大,只查右半边
# 2. 看右半边的中间 66,正好命中!
为什么叫 log n?
log n 在数学里叫“对数”,你可以简单理解为:2的多少次方等于 n。
- 2⁶ = 64,所以 log₂64 = 6
- 2⁷ = 128,所以 log₂128 = 7
n 从64涨到128,翻了一倍,但查找次数只从6涨到7,只加了1次。这就是 O(log n) 的可怕之处——数据越多,优势越大。
四、O(n) —— 老实人,“一个一个来”
O(n) 的意思是:最坏情况下,每个东西我都要看一遍。
生活场景
早上出门,钥匙找不到了。你从床头柜开始翻,翻书桌,翻沙发,翻厨房……一个地方一个地方地找。如果房间里有 n 个地方可能藏钥匙,最坏的情况下,你要把 n 个地方都翻一遍。这就是 O(n)。
计算机场景:顺序查找
在无序数组里找一个数,只能用这个方法。
# 在乱序数组里找66
arr = [34, 78, 12, 56, 89, 2, 23, 66, 45, 5, 19, 8]
for num in arr:
if num == 66:
print(“找到了!”)
break
运气好可能第一个就是,运气不好可能最后一个才是,最坏情况就是 n 次。
数据对比
| 数据量 |
O(log n) 次数 |
O(n) 次数 |
| 100 |
7 |
100 |
| 1万 |
14 |
1万 |
| 100万 |
20 |
100万 |
当数据量到100万时,O(log n) 只要20次,O(n) 要100万次。5万倍的差距!
五、O(k) —— 我只找该找的
O(k) 的意思是:这事儿需要干多少活,取决于“有多少个目标”,而不是“总共有多少东西”。
生活场景
全班50个人,你要收没交作业的那几个人。老师告诉你“就那5个没交”,你直接去找那5个人。不管全班是50人还是500人,只要没交作业的还是那5个,你的工作量就不变。这里的 k = 5(没交作业的人数),n = 50(全班人数),但如果k值很大,那么也会影响效率。

六、从“查东西”看透算法效率
快慢排名(一般情况下):
O(1) > O(log n) > O(k) > O(n)
但注意:O(k) 的位置不固定——
- 如果 k 很小(比如 k=10),它可能比 O(log n) 还快
- 如果 k 很大(比如 k=n/2),它可能接近 O(n)
- 所以 O(k) 的“快慢”完全取决于k 本身有多大,因此它的效率受K值大小而影响。
七、闭上眼睛回想一下
- O(1) 是什么?—— 看地图找工位,一步到位
- O(log n) 是什么?—— 猜数字,每次排除一半
- O(n) 是什么?—— 找钥匙,每个地方翻一遍
- O(k) 是什么?—— 收作业,只找没交的那几个
八、下次写代码时,记得问自己三个问题
- 我到底要处理多少数据?(n 有多大?)
- 我是不是真的需要处理全部?(能不能只处理 k 个?)
- 有没有办法每次排除一半?(能不能变成 O(log n)?)
想清楚这三件事,你就已经能在设计功能时,做出更高效的技术选型了。理解这些基础概念,是写出优秀代码的第一步。如果你想进一步深入探讨算法与数据结构,欢迎来云栈社区和其他开发者一起交流学习。
 发表于 2026-3-19 04:09:22
|
查看: 209|
回复: 0
发表于 2026-3-19 04:09:22
|
查看: 209|
回复: 0
