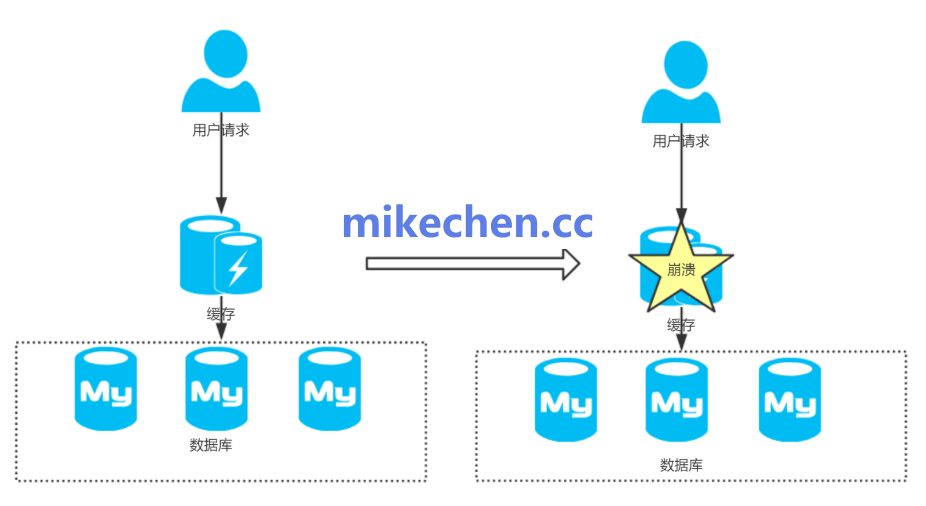
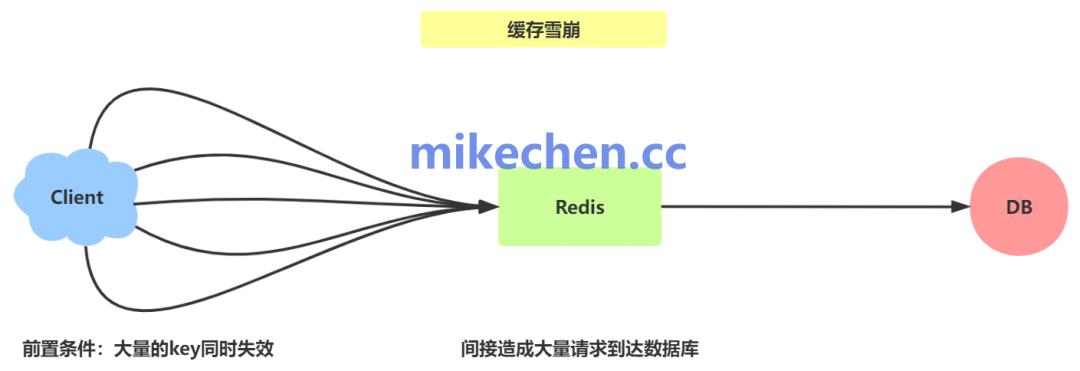
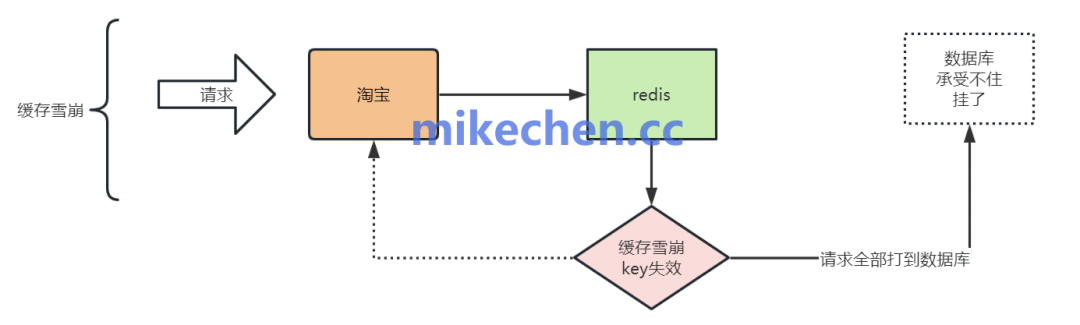
缓存雪崩指的是在分布式缓存系统(如Redis、Memcached)中,大量缓存数据在同一时间点或极短时间内集中失效,导致后续的海量用户请求无法从缓存中获取数据,从而直接“穿透”至后端数据源(如数据库)。
这会造成后端数据源瞬间承受巨大的请求压力,可能导致连接池耗尽、响应延迟激增,甚至引发整个服务链路的级联故障,就像雪崩一样。
缓存雪崩的常见成因
缓存雪崩的发生通常不是偶然,其背后往往有特定的设计或运维原因:
- 统一的过期时间:为缓存键设置了相同或过于集中的TTL(生存时间)。例如,所有缓存数据都在凌晨1点过期,导致此时出现一个巨大的请求回源峰值。
- 缓存资源耗尽:当缓存容量不足时,系统会根据淘汰策略(如LRU)批量清理数据,可能将大量热点数据同时移除。
- 突发事件:例如缓存服务重启、人为清空缓存、或在业务高峰期(如秒杀活动开始)突发巨大流量。
- 服务故障:缓存集群因网络分区、硬件宕机等问题整体不可用。
四种核心解决方案
针对上述成因,可以采取以下策略来预防和缓解缓存雪崩问题:
1. 缓存过期时间打散(TTL随机化)
避免为大量缓存键设置完全相同的过期时间。可以在基础过期时间上,增加一个随机的时间偏移量(例如,基础1小时 ± 随机10分钟)。这样可以将缓存失效的时间点分散开,平滑请求峰值,避免在某一刻对后端造成集中冲击。
2. 请求限流与熔断
在服务端或网关层实施限流策略,当单位时间内的请求量超过预设阈值时,对后续请求进行排队、降级或快速失败,以保护后端数据源不被压垮。同时,结合熔断机制,当检测到后端服务错误率升高或响应过慢时,自动切断部分请求链路,给系统恢复的时间。
3. 互斥锁重建缓存
当某个热点缓存失效时,不允许多个请求同时去数据库查询并重建缓存。可以使用分布式锁或本地互斥机制,保证同一时间只有一个请求线程执行“查询数据库 -> 写入缓存”的操作,其他请求则等待锁释放后直接读取新缓存。这种方法有效防止了缓存击穿,但需要注意锁的粒度和超时时间,避免死锁或长时间等待。
4. 缓存预热与主动刷新
对于已知的热点数据,可以在系统启动、业务高峰期来临前或缓存被清空后,主动将其加载到缓存中,即“预热”。此外,可以对即将过期的热点数据,在后台启动异步任务进行刷新,延长其有效期,避免用户请求触发被动更新。这需要结合业务监控数据来智能判断哪些数据需要预热和刷新。 |  发表于 2025-12-9 07:11:33
|
查看: 145|
回复: 0
发表于 2025-12-9 07:11:33
|
查看: 145|
回复: 0
