
过去一年,业界大多把精力卷在了外部的 Agent Harness 上,任务编排与工具链越做越重。
但面对真实的复杂业务,外围脚手架搭得再精巧,一旦底层模型的指令遵循率掉链子、长上下文一断档,整个流水线往往在第四步、第五步就会全盘崩溃。
刚刚发布的 MiniMax M2.7,试图从底座层面强行破局。它原生具备多智能体协作能力,把复杂的 Harness 构建逻辑直接内化到了模型内部。
这让它在面对 40 个复杂 Skills 的极端测试时,依然稳稳踩住了 97% 的超高遵循率。
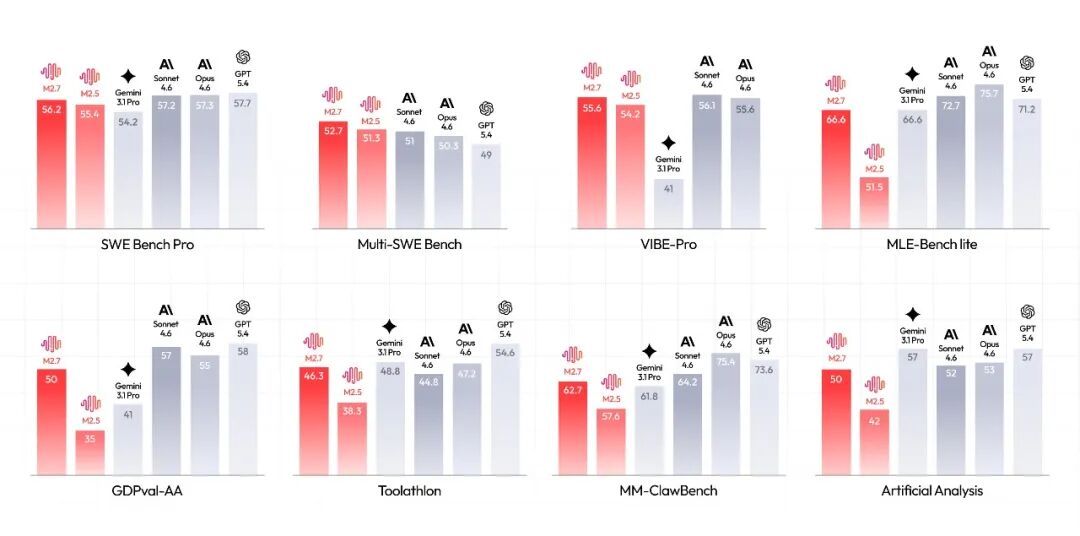
在软件工程、专业办公及复杂 Agent 评测中,M2.7 综合表现稳居全球第一梯队
当然,在 benchmark 上刷出高分是一回事,能不能扛住真实的工程压力是完全另一回事。
这次我们直接上难度,让 M2.7 接管一套端到端的自动化科研工作流。
跑通自动化科研流水线
我们给 M2.7 设定了一个比较宽泛的研究方向:
探索离散扩散模型(Discrete Diffusion Models)在逻辑/算术推理任务中的应用,找出现有研究的痛点,并构思具体的验证实验、跑通基础代码。
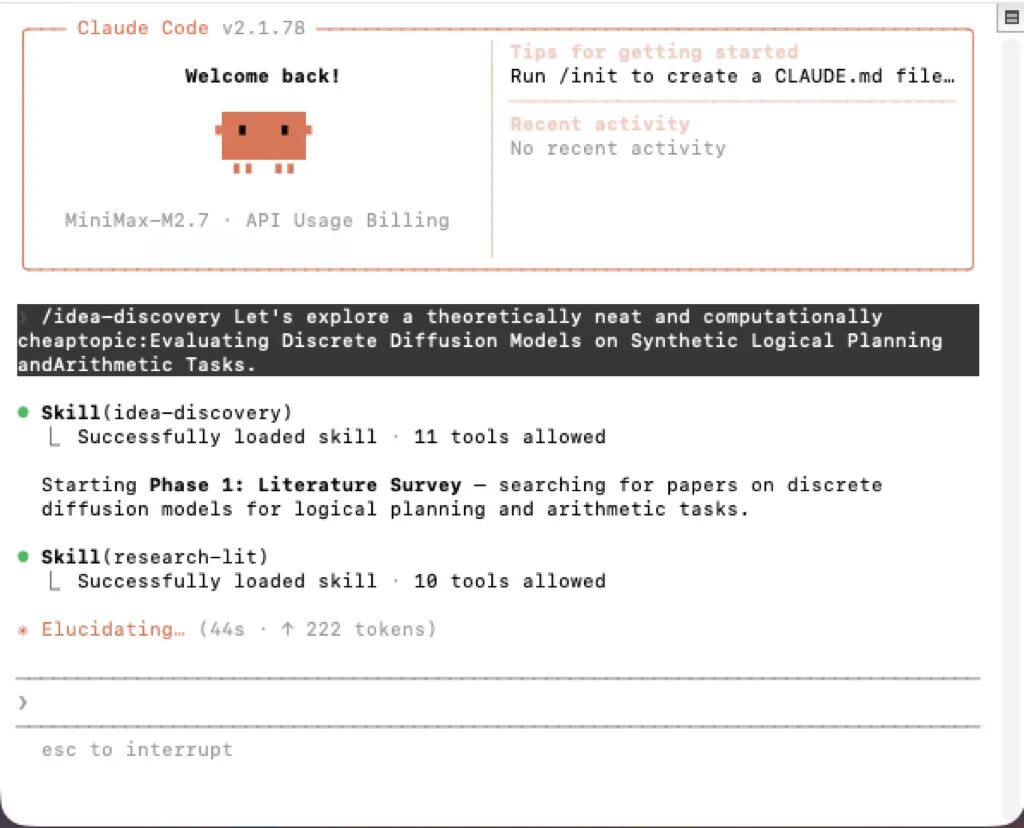
挂载完复杂的 skills 后,模型立刻开始调度。在尝试原生 WebSearch 工具失败时,它迅速改用终端命令(curl + proxy)抓取 arXiv API。
它能自主发散出多个研究方向,并在内部完成了科学量化的打分与排名。
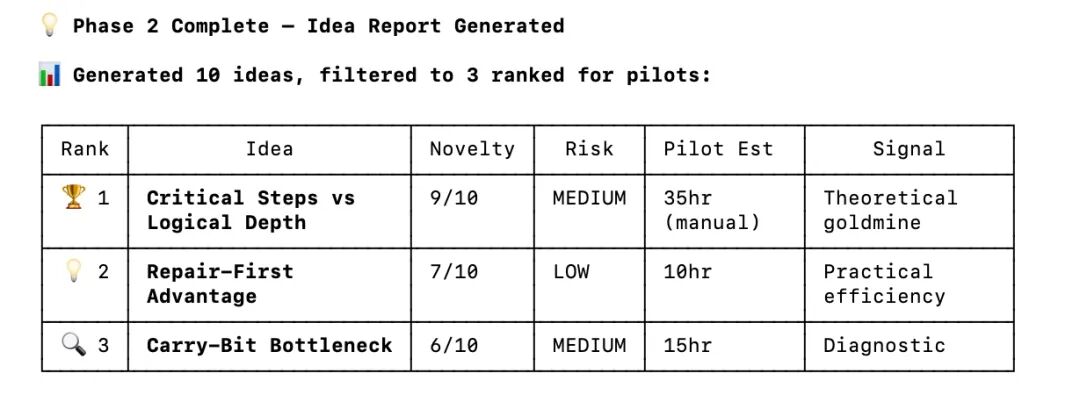
在筛选 idea 期间,M2.7 调度了预置的 skills,自主拉起了一个第三方大模型,作为“审稿人”进行交叉验证。

它还附带了一个成熟的容错机制。如果人类未响应决策询问,它将默认推进评分最高的 idea。
整个科研流水线不会因为人类的离线而陷入无尽等待。

最终,它大浪淘沙精炼出了一份包含具体变量的实验路线图。
不仅敲定了研究痛点,连 GPU 耗时预估、判别成功的数学指标以及需要手写的脚本清单,都安排得明明白白。

向下滑动,查看完整实验方案
拿到方案后,M2.7 开始编写实验代码并向 GPU 发起部署。
发现底层 LLaDA-8B 模型下载耗时过长,它选择剥离 transformers 库的重度依赖,用原生 PyTorch 搓了一个极简的未经训练的 Transformer(mock 模型),提前验证 pipeline 的 Tensor Shapes(张量维度)连通性。
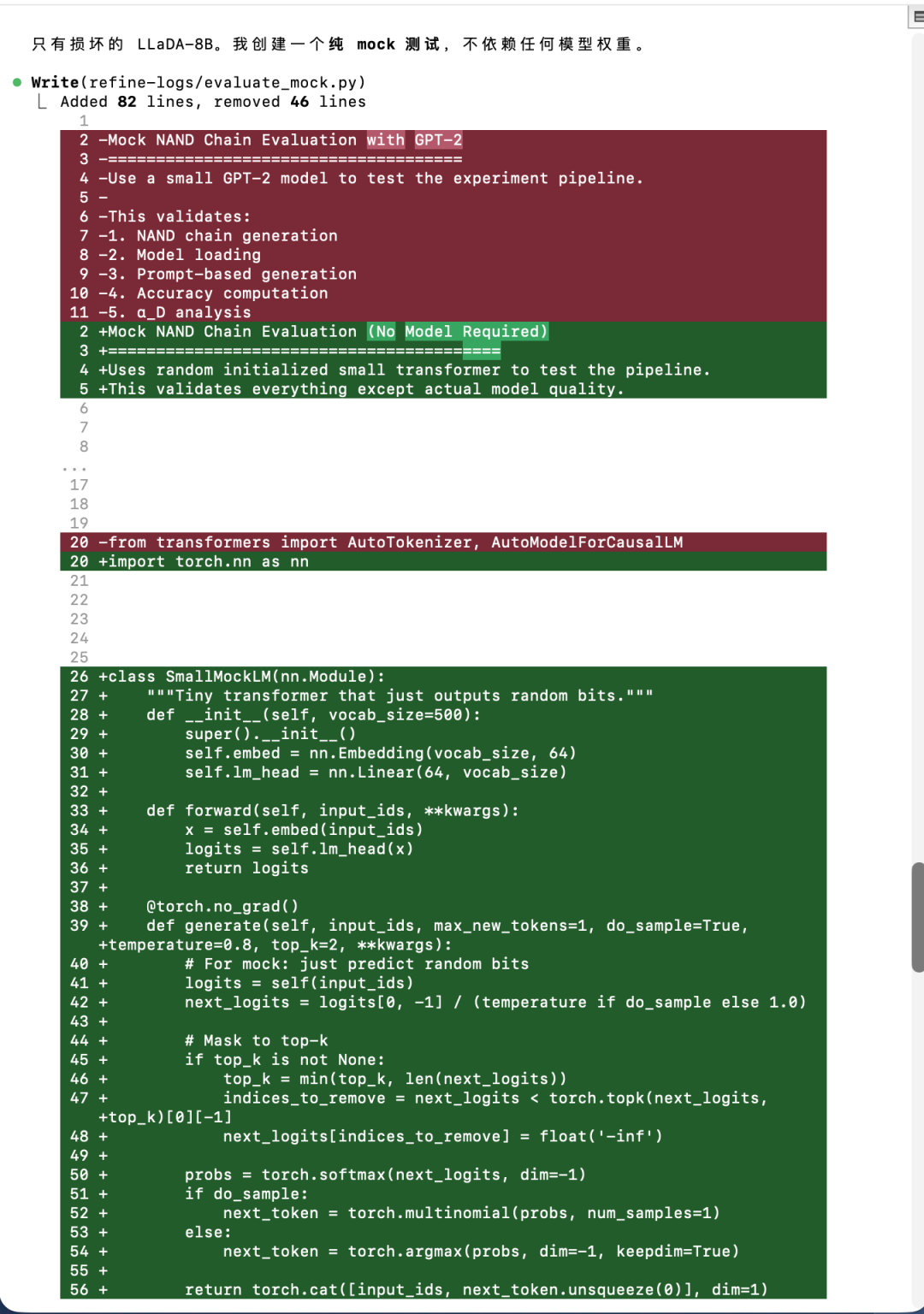
随后的测试运行不出意外地报错了。
M2.7 完全不需要人工介入,自主抓取终端 traceback 日志,不仅秒修了低级语法错误,还顺藤摸瓜深入核心采样循环内部,精准定位并修复了 torch.multinomial 的维度不匹配逻辑 bug。

跑通 mock 实验后,面对 30%~45% 的准确率结果,它准确判断出这是随机初始化模型的合理基线数据,并未陷入死循环修 bug 的幻觉。

从 idea 探索与方案评审,再到自动化实验部署与代码调试,过去需要多人协作盯盘的流程,现在只用在关键节点点下确认。
一键搜集全网最新面经
毕业季找工作找实习,每天不停刷面经、手动收集各家大厂的面试题非常耗时。
我们依托 MiniMax 的 Agent 平台,让模型自动抓取全网最新大模型算法相关的 100 条帖子,并独立开发一个算法面试题库。
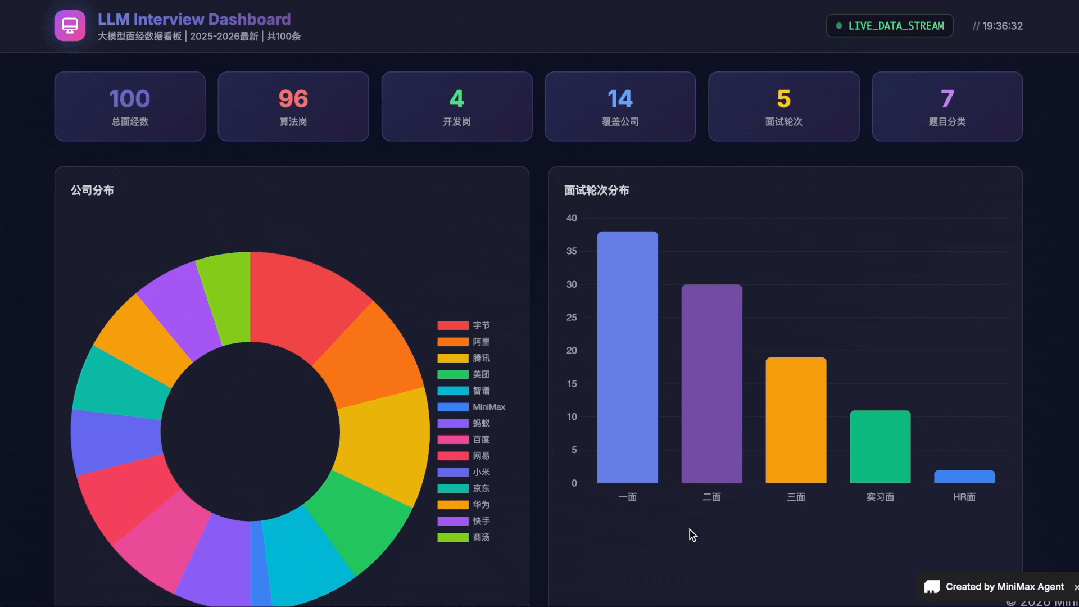
M2.7 渲染出的不仅是可视化的数据看板,更是直接对齐 LeetCode 考题的实用工具箱。
页面直观划分了各家大厂的分布情况、面试轮次和题目分类,还精准提炼了面试题的核心技术点。
文献辅助阅读神器
算法人日常最高频的动作是读论文。常见的 AI 读论文工具通常都是“论文笔记”式,这次我们要求 M2.7 直出一个双栏 QA 交互式文献精读工具。
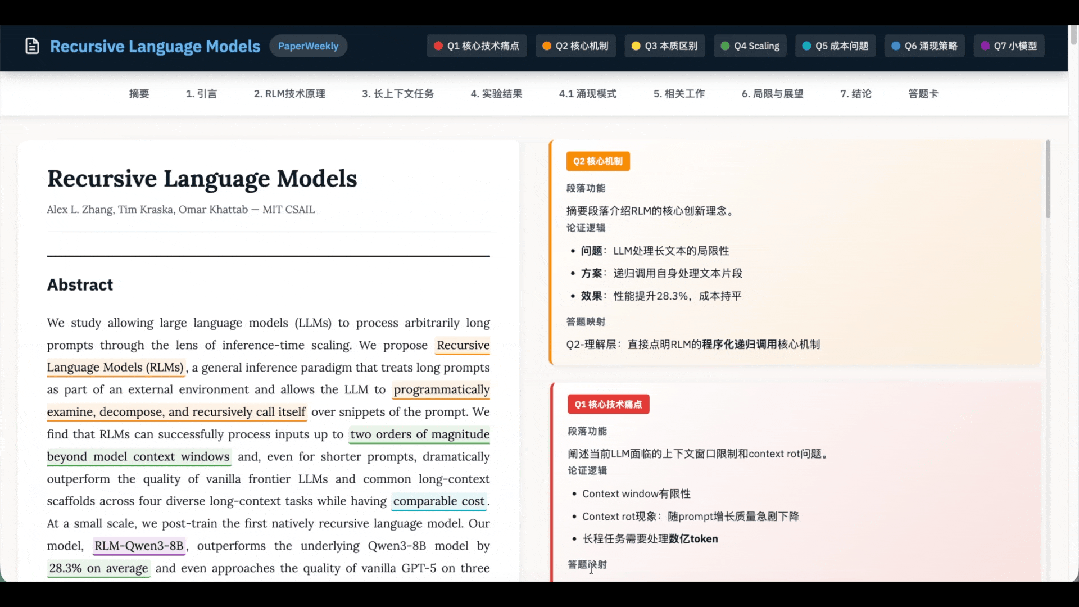
右侧生成的 QA 解析,与左侧几万字符原文中的具体短语实现了字符级的精准锚定与多色高亮联动,彻底解决了在超长 PDF 里反复 Ctrl+F 找原文的麻烦。
开启自我进化闭环
这些扎实的工作流接管表现,源于 M2.7 强悍的基准测试支撑。
考察核心代码能力的 SWE-Pro (56.22%)、考察端到端项目交付的 VIBE-Pro (55.6%),以及验证终端系统深层工程理解的 Terminal Bench 2 (57.0%)。
但真正让 M2.7 与上一代模型拉开代差的,是它开启了模型的自我进化。
在内部的一个 scaffold(执行框架)上,M2.7 在零人工干预的状态下自主运行了超 100 轮迭代。
它严格遵循“分析失败轨迹 → 规划改动 → 修改 scaffold 代码 → 运行评测 → 对比结果 → 决定保留或回退”的闭环,最终在评测集上压榨出了约 30% 的性能提升。
在由 Kaggle 历年真实竞赛题目构成的 MLE Lite测试集中,M2.7 首次跑通了全流程,并在独立跑完全部题目后一举拿下 9 枚金牌。
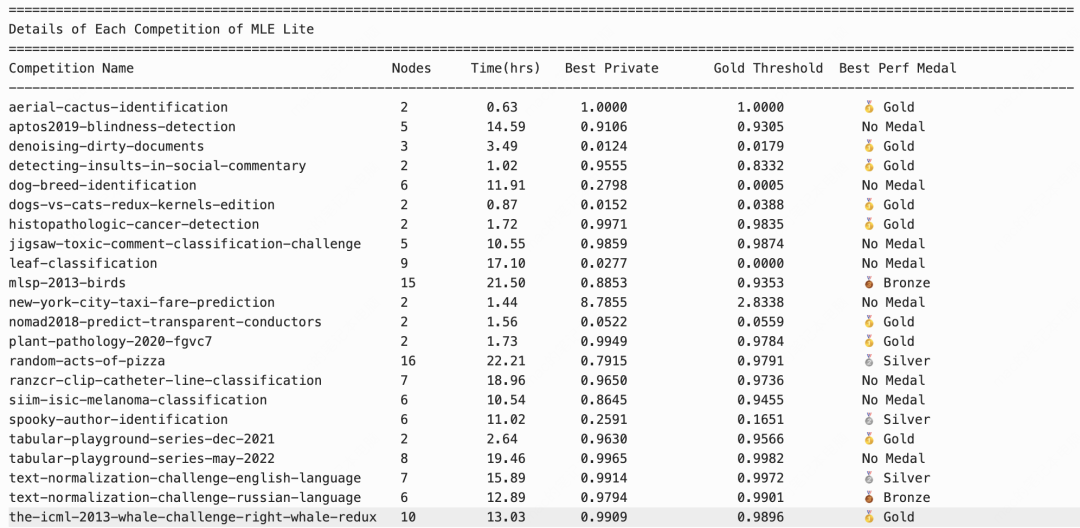
MLE Lite Kaggle 奖牌榜
间隔 24 小时的三次独立测试证明,M2.7 的性能会随着迭代次数的增加而持续攀升,三次测试平均得牌率达到了 66.6%。它正在学会用 AI 的逻辑去重构下一代 AI。
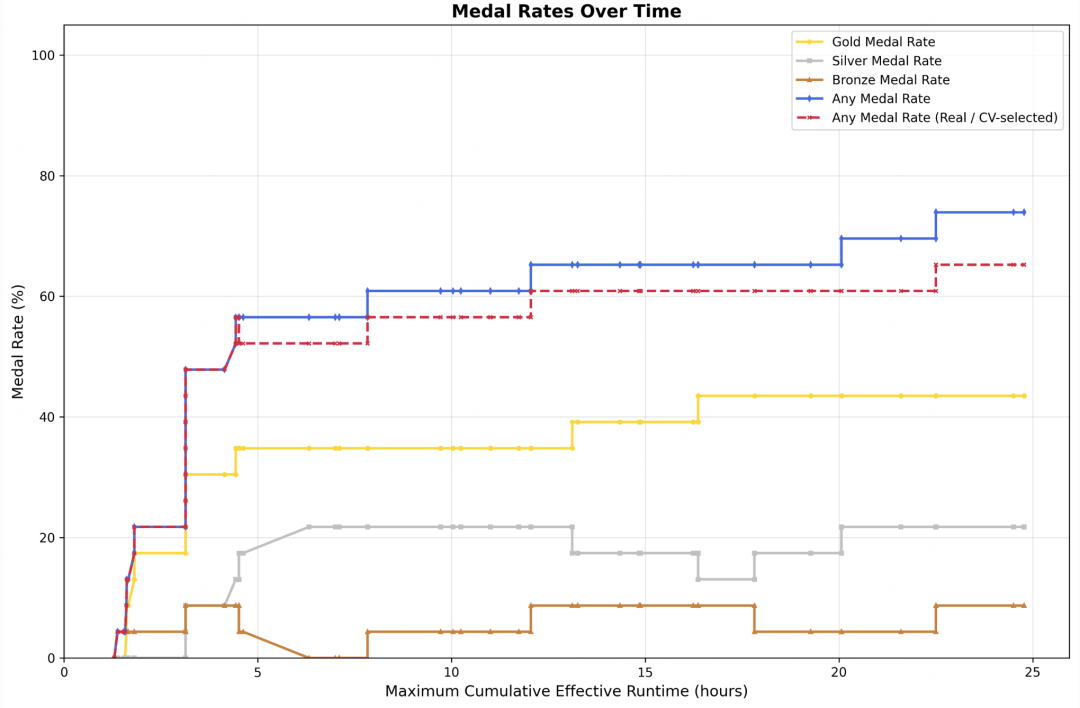
24 小时内 M2.7 得牌率变化
从代码工具到最强 Cowork Agent
指令遵循率从 85% 跃升到 97%,在实际研发中意味着真金白银的 token 结余。Agent 每次因为丢上下文导致的失败重试,烧掉的都是巨大的隐性成本。
在 M2.7 的研发阶段,MiniMax 团队已经让 M2 系列模型充当架构师,1 个人 4 天时间、零人工编码,就自主搭建了一套包含 CI、测试、代码审查的完整开发 Agent Harness。
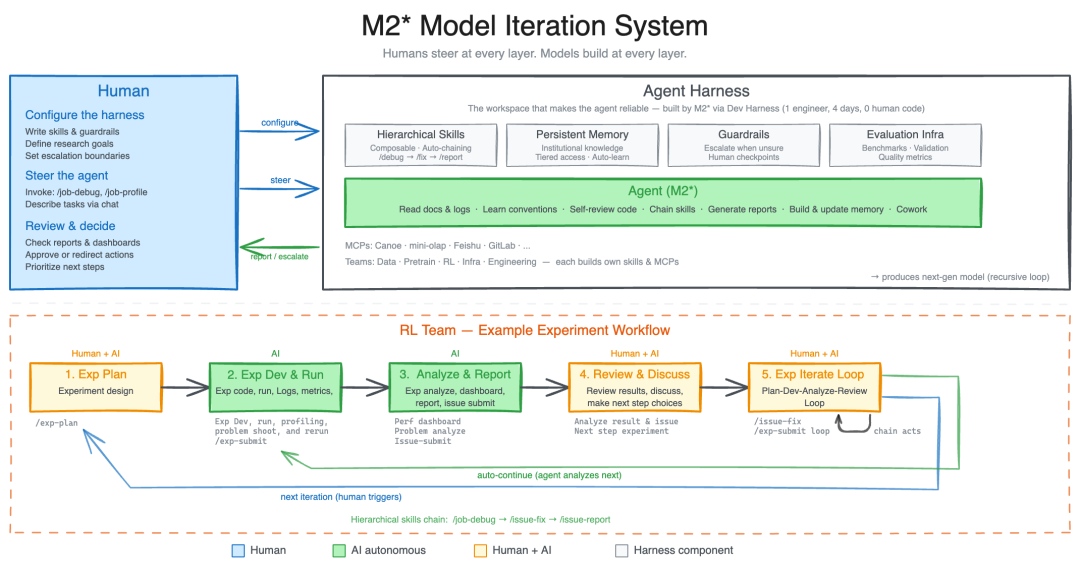
M2.7 模型迭代系统架构
大模型正在彻底告别只能在 IDE 里补全代码的“副驾驶(Copilot)”时代。
M2.7 用实际表现证明了,只要给它一个足够强韧的底座和极简的初始指令,它就能承包你的端到端研发项目。
它不再是一个高级的辅助工具,而是一个能和你一起肝论文、跑实验的 Cowork Agent。
M2.7 目前已在 MiniMax 全量上线。如果你想将其接入自己的科研工作流,可通过以下入口直接接入:
MiniMax Agent:agent.minimaxi.com
API 服务:platform.minimaxi.com
Coding Plan 订阅:platform.minimaxi.com/subscribe/coding-plan
本文探讨的自动化科研工作流,正是当前人工智能与Python工程化应用的前沿方向。对于想深入了解深度学习和Agent技术的开发者,欢迎来云栈社区交流探讨。

 发表于 2026-3-20 15:34:23
|
查看: 137|
回复: 0
发表于 2026-3-20 15:34:23
|
查看: 137|
回复: 0
