近年来,从Gemini、GPT到Qwen、Llama和DeepSeek,各类大模型层出不穷。Hugging Face上可用的模型数量已超过18万个。与此同时,我们也面临两大现状:其一,尽管大模型能进行零样本推理,但其准确性有限、存在幻觉、与人类目标不一致等问题仍然突出;其二,由于架构、规模、训练数据等方面的差异,不同模型的行为表现迥异,针对同一提示词(query),它们的回答往往千差万别。
受到集成学习的启发,一个新兴的研究方向——“大模型集成”(LLM Ensemble)应运而生。其核心思想是:与其为每个query固定依赖某一个模型,不如同时调用多个现成可用的LLM,综合利用它们各异的优势。在LLM Ensemble中,“推理后集成”方法日渐流行,它们通常可分为两类:一类是“先选择后生成”方法,这类方法通常依赖特定任务数据并需要微调额外模型,缺乏灵活性;另一类是基于相似度的选择方法(如Smoothie、Agent-Forest),它们通常完全无监督,通过选择与所有其他回答总体相似度最高的那个作为最终输出。
然而,基于相似度的方法设计相对粗糙,大多依赖简单的策略和浅层的度量(如BLEU)。我们不禁思考:在现实世界中,人类如何从一组候选文本中选出最理想的一份,尤其是在文本质量难以衡量的场景下?最直接相关的案例可能就是:学术同行评审。
受此启发,我们提出了一种完全无监督、简洁高效的LLM集成新框架——LLM-PeerReview。
LLM-PeerReview 框架详解
该框架模拟了学术同行评审的流程,包含三个顺次执行的模块:评分(Scoring)、推理(Reasoning)和选择(Selection)。
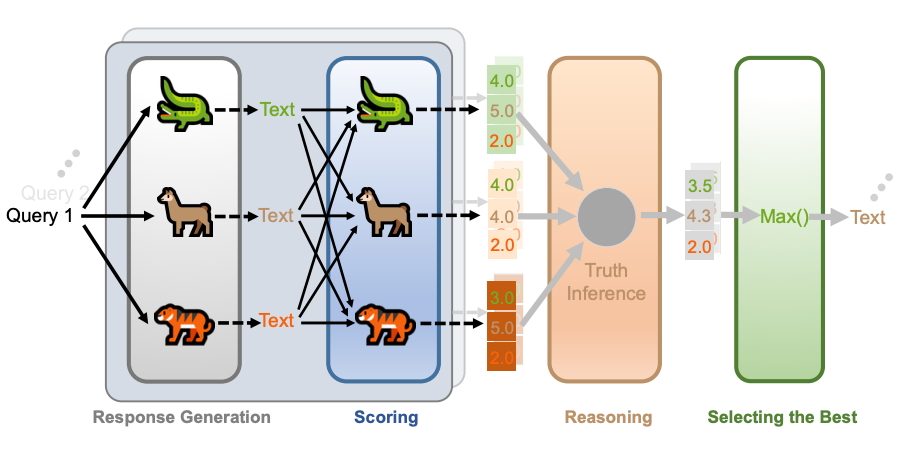
LLM-PeerReview 方法流程图。包含响应生成、评分、推理和选择最佳四个阶段。
1. 评分(Scoring):每个模型都是审稿员
我们复用模型集合中的LLM作为评估者(即LLM-as-a-Judge),针对同一query生成的多个候选回答进行打分(例如,用5分制表示“强烈接受”)。
为了减轻评估过程中固有的偏差,我们提出了一个关键创新——“翻转三元评分技术”(Flipped-triple scoring trick)。其具体操作如下:
- 随机洗牌(Shuffle):将针对同一query生成的多个回答随机打乱顺序。
- 三元组翻转滑动评分:对于每个担任评审员的LLM M_j,我们按顺序对回答三元组 (ri, r{i+1}, r{i+2}) 进行评分(总共滑动执行 N-2 次,N为回答总数)。在每次滑动前,我们还会对翻转后的三元组 (r{i+2}, r_{i+1}, r_i) 进行评分。
- 最终分数计算:通过上述机制,每个回答 r_i 会从同一评审员 M_j 处获得6个分数。取这些分数的平均值,即得到评审员 M_j 对回答 ri 的最终评分 s{j,i}。
该技术旨在缓解LLM-as-a-Judge中常见的两种偏差:
- 一致性偏差(Consistent Bias):在逐点(Point-wise)评分时,模型缺乏多个回答作为参考,容易倾向于给出固定分数。
- 位置偏差(Position Bias):当同时展示多个回答时,模型可能倾向于青睐出现在开头或结尾的回答。
2. 推理(Reasoning):汇聚审稿意见
我们将来自不同评审员的多份评分进行聚合。框架提供了两个版本:
- LLM-PeerReview:采用最简单的平均策略。
- LLM-PeerReview-W:引入权重感知,根据每个LLM的“评审水平”为其打分赋予不同的权重(基于改造后的图模型处理连续分数)。
3. 选择(Selection):挑选最佳回答
对于每个query,我们直接选择综合得分最高的那个回答作为最终的集成输出。
我们的核心观点是:让大模型互相评审来挑选最佳回答,是一个高度直观且自然的逻辑。实验表明,如果仅使用简单的逐点评分,像7B这样的中小模型表现不佳。而嵌入“翻转三元评分技术”后,LLM-PeerReview 的性能实现了质的飞跃,成为一个极其简洁而有效的多模型协同方法。
该方法优势明显:完全无监督、无需微调、框架可解释性强,既能应用于答案匹配型任务(如数学解题),也能用于开放型生成任务(如代码生成、指令遵循)。
理论支撑与效率考量
我们为评分阶段提供了理论分析,例如下面的误差-模糊度分解定理,它说明了集成误差、平均个体误差与模型多样性(模糊度)之间的关系,为评估员的选择提供了理论指导。

误差-模糊度分解定理公式,描述了集成输出与个体误差、多样性之间的关系。
在效率方面,Scoring过程可以灵活调整评审员数量以线性减少计算量。与需要多轮辩论的经典协作方法相比,LLM-PeerReview 仅需一轮打分,具备更高的计算效率。
核心实验结果
我们在多种任务和数据集上进行了广泛实验,包括事实问答(TriviaQA)、数学推理(GSM8K, MATH)和指令遵循(AlpacaEval),对比了单个LLM、流行的“推理后集成”方法(Smoothie, Agent-Forest)和“推理时集成”方法(GaC)。
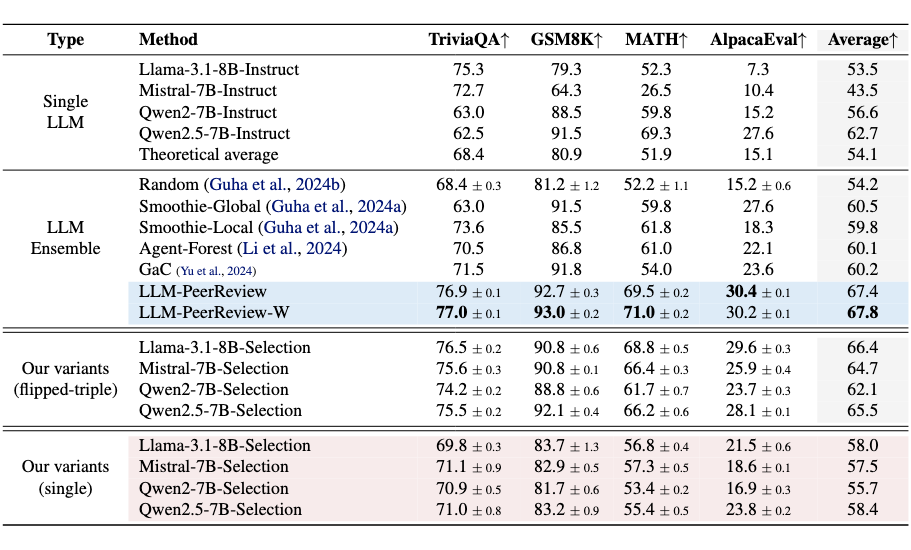
不同方法在多个基准测试上的性能对比表格。
核心结论如下:
- 显著性能提升:LLM-PeerReview 和 LLM-PeerReview-W 明显超越了任何单一LLM以及所有现有的LLM Ensemble基线方法。在平均性能上,分别以6.9%和7.3%的优势超越了先进的Smoothie-Global方法。
- 翻转三元评分技术是关键:通过对比“our variants (flipped-triple)”和“our variants (single)”可以清晰看到,采用新评分技巧后,四个单评审员设置的性能分别提升了8.4%、7.2%、6.4%和7.1%,证明了该技术是性能飞跃的主要功臣。
- 少量评审员仍有效:即使只使用一个LLM作为评审员并应用新评分技巧(即表格中的 flipped-triple 变体),其性能也已相当不错,在某些情况下甚至优于一些复杂的集成基线。
- 加权版本带来增益:LLM-PeerReview-W 相比基础的平均版本展示出了一定的性能提升。
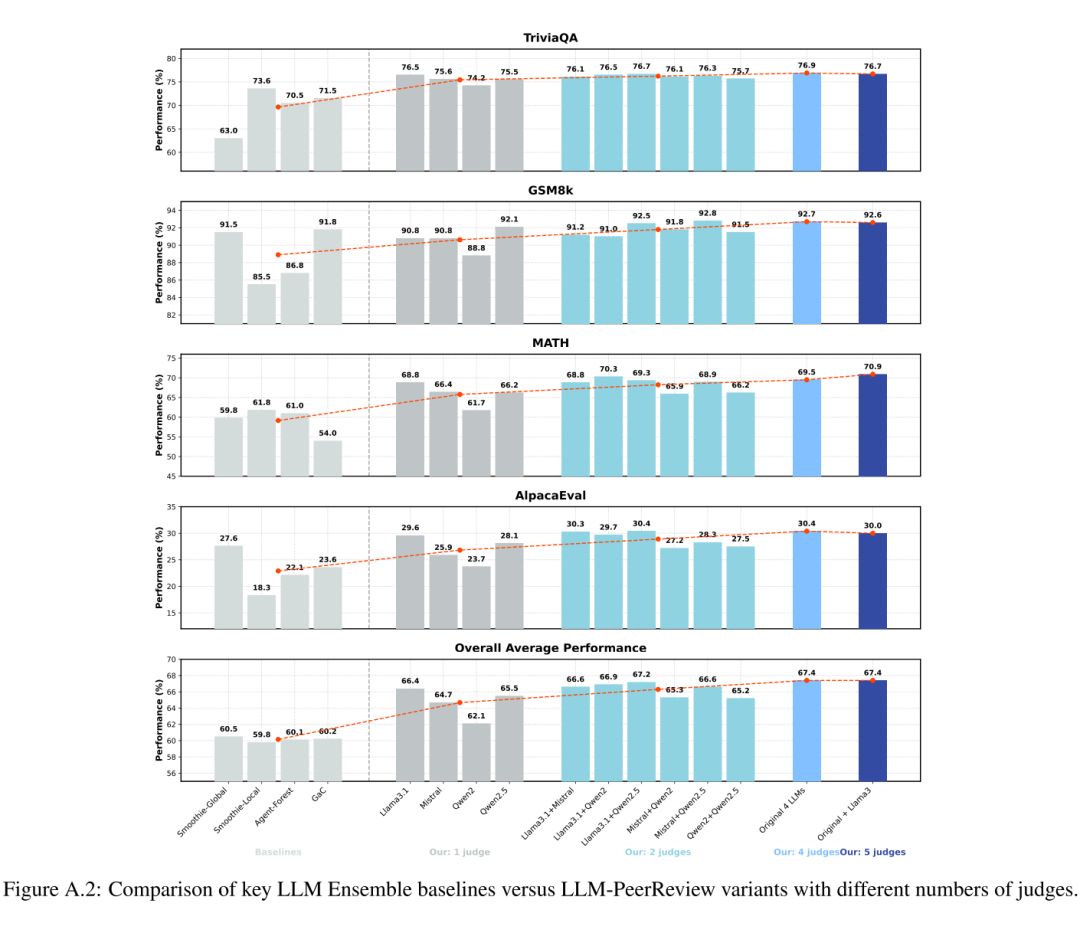
LLM-PeerReview 使用不同数量/种类评审员与其他基线方法的性能对比图。
总结与开源
LLM-PeerReview 是一个受同行评审启发、完全无监督、透明可解释的大模型集成框架。它摒弃了基于浅层相似度的选择策略,转而利用LLM-as-a-Judge进行精细化评估,并通过创新的“翻转三元评分技术”有效缓解了评估偏差。实验证明,该框架能显著提升模型集成的效果。
我们已全面开源了本研究的代码、数据和模型,旨在为LLM集成与协作研究社区提供一份实用的资源。
@article{chen2025scoring,
title={Scoring, Reasoning, and Selecting the Best! Ensembling Large Language Models via a Peer-Review Process},
author={Chen, Zhijun and Ji, Zeyu and Mao, Qianren and Cheng, Junhang and Qin, Bangjie and Wu, Hao and Li, Zhuoran and Li, Jingzheng and Sun, Kai and Wang, Zizhe and others},
journal={arXiv preprint arXiv:2512.23213},
year={2025}
}
相关链接:
对更多前沿AI技术与开源实践感兴趣的开发者,欢迎关注 云栈社区 的讨论与分享。
 发表于 2026-3-20 15:37:42
|
查看: 148|
回复: 0
发表于 2026-3-20 15:37:42
|
查看: 148|
回复: 0
