百万 token 上下文环境里,DeepSeek-V4-Pro 的单 token 推理 FLOPs 压到了 V3.2 的 27%,KV Cache 更是只有原先的 10%;V4-Flash 则更进一步——仅用 10% 的 FLOPs 和 7% 的 KV Cache。百万上下文从一个昂贵的演示特性,变成了可以日常承载的生产级工作负载。
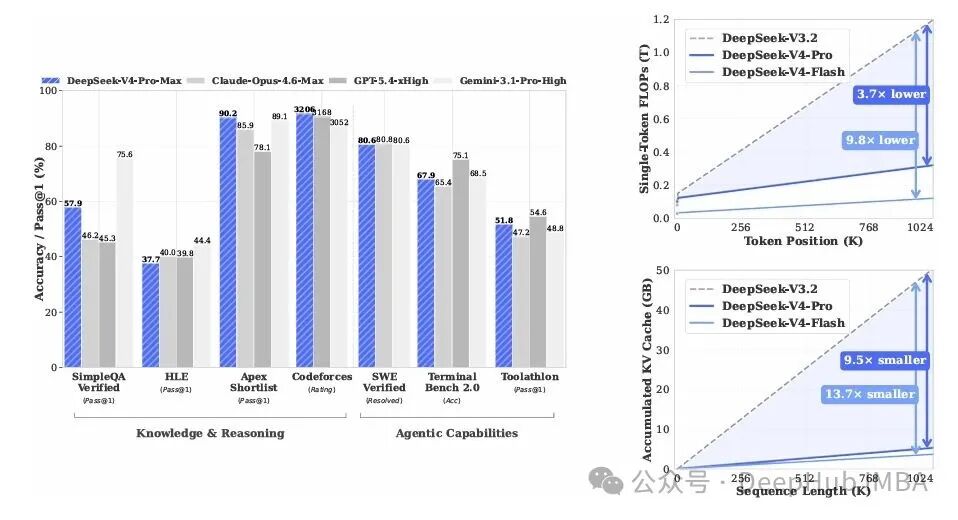
过去两年,大模型的演进基本没离开两条主线:一条是推理模型靠延展思考链做 test-time scaling 来刷新基准分;另一条是 agent 工作流——动辄需要跨越多份长文档、进行多轮工具调用的长周期任务。这两条路都极度依赖上下文窗口的长度,而原生的注意力是 O(n²) 复杂度:上下文长度翻倍,计算量与显存占用就翻四倍。这也是为什么很多开源模型纸面上标注 128K,真正跑到 64K 时推理就已卡顿的根本原因。
DeepSeek-V4 正是要正面解决这个瓶颈。它用混合稀疏注意力(CSA + HCA)沿序列维度对 KV Cache 做了一次深度裁剪,用流形约束的超连接(mHC)顶住深层网络堆叠导致的数值不稳定,用 Muon 优化器来加速收敛,再用 FP4 量化感知训练把 MoE 权重砍去一半。这样一套组合拳下来,1M 上下文的边际成本才被压到了可以接受的程度。
接下来的剖析会围绕三个核心问题展开:长上下文的计算效率如何突破(架构设计);万亿级 MoE 模型怎么稳定地训出来(基础设施与训练技巧);以及如何把十几个垂直领域的“专家”合并进单一模型(后训练策略)。
架构设计:V4 在 V3 基础上动了哪“三刀”
DeepSeek-V4 的基本底盘依然是 Transformer + DeepSeekMoE + MTP,但与 V3 系列相比,做了三处能称得上代际升级的改动:
| 维度 |
DeepSeek-V3 / V3.2 |
DeepSeek-V4 |
| 注意力 |
MLA(V3)/ DSA(V3.2) |
CSA + HCA 混合 |
| 残差连接 |
标准 residual |
mHC(流形约束超连接) |
| 优化器 |
AdamW |
Muon(embedding/head 保留 AdamW) |
| MoE 路由 |
sigmoid + top-k |
sqrt(softplus) + 放开节点路由限制 |
| 前几层 FFN |
dense |
MoE + Hash 路由 |
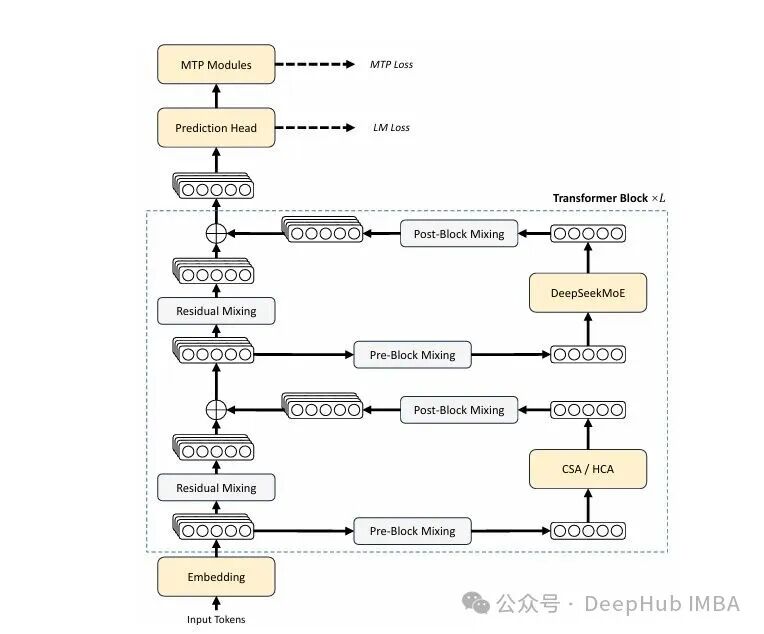
CSA + HCA——把 KV Cache 沿序列维度“叠罗汉”
V4 的注意力机制是一种由两种压缩注意力交错构成的混合架构。CSA 负责温和压缩与稀疏选择;HCA 则进行激进压缩并保留全量注意力。
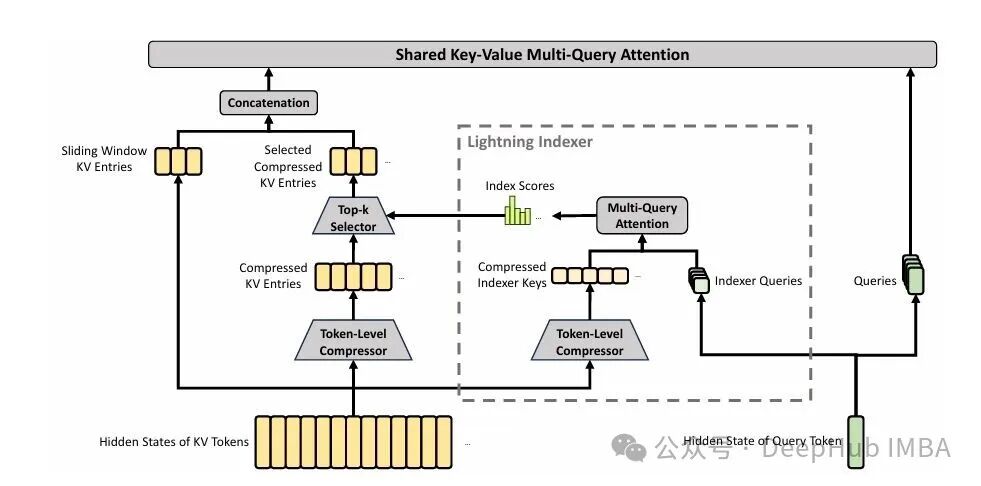
CSA:先粗读,再精读
CSA 将每 m 个相邻 token 的 KV 压缩为 1 个压缩条目(V4-Pro 中 m=4),然后依靠一个轻量级的 Lightning Indexer 为每个 query 挑选出 top-k 个最相关的压缩条目做核心注意力计算(V4-Pro 中 top-k=1024)。
压缩的过程本质上是一次加权求和——而不是简单的取平均。它借助学到的 softmax 权重加上位置偏置,让模型自主决定在当前窗口的这 4 个 token 里,哪一个更值得“多看两眼”。论文中的数学描述很清晰:
对每 m 个 token 的 KV,计算两路 C^a, C^b 和对应的权重 Z^a, Z^b,经由 softmax 归一化后加权求和,得到 1 个压缩条目。
这里采用重叠压缩的设计(C^b 采前 m 个 token、C^a 用后 m 个 token),目的是避免硬切边界造成的上下文断裂。
而 Lightning Indexer 则可以理解为一个低秩的多查询小注意力:用一组专门的 indexer query 对所有压缩后的 indexer key 算分,通过 ReLU 加权求和评出一个分数,最后选 top-k。indexer 的整个 QK 计算路径都跑在 FP4 精度上,这也是后续 KV Cache 体积能压到 V3.2 十分之一的关键。
一句话总结:CSA 相当于先把每 4 个 token 摘要成 1 句话,再用一个小模型从中挑出最相关的 1024 句话来精读。
HCA:直接做全局摘要
HCA 则走向了另一个方向:压缩比 m' 拉到了 128(V4-Pro/Flash 皆为 128),不做重叠,但保留密集注意力,不再进行 top-k 选取。
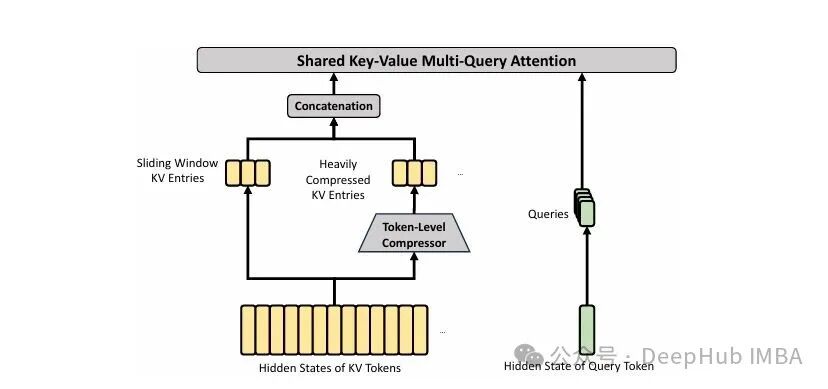
为什么还需要 HCA?因为 CSA 虽然可以聚焦细节,但 top-k 这种稀疏选择机制天然会遗漏一些全局性的摘要信息。HCA 把 1M 的原始 token 直接压缩成约 7800 个条目,所有 query 都可以访问,相当于一条永不断线的全局摘要通道。
两者按规律交错排布——V4-Pro 前 2 层用 HCA,之后 CSA/HCA 交替——共同构成了一套既具备局部精读、又拥有全局浏览能力的双轨注意力。
几个进一步提升效率的细节操作
Partial RoPE 只在 query 和 KV 的最后 64 个维度上应用旋转位置编码。当压缩条目被用作 value 时,会携带绝对位置残差;V4 的做法是在输出端用 position=-i 的 RoPE 做一次反向“贴合”,把绝对位置扭转回相对位置。每层额外保留最近 n_win=128 个 token 的未压缩滑窗 KV,专项增强局部细节感知。此外还引入了 Attention Sink:给每个 head 增加一个可学习的 sink logit,使得某个头在极长序列下的注意力总分可以接近零,缓解注意力强制分散的问题。整个 KV Cache 采用混合精度——RoPE 维度保留 BF16,其余维度用 FP8——直接砍掉一半的存储开销。
把这些全部叠加后,论文给出的量化对比是:以 BF16 GQA8(head_dim=128)为基线,V4 的 KV Cache 体积可压缩至约 2%。这为文章开篇提到的百万上下文可用性提供了底层保障。
mHC—— 给残差通路套上“概率守恒”
DeepSeek-V4 没有沿用标准残差链接,而是引入了 mHC(流形约束超连接)。
我们先回顾最初的 Hyper-Connections:将残差流的宽度从 d 拓宽至 $n_{hc} \times d$(V4 里 $n_{hc}=4$),通过 A、B、C 三个映射来控制信息流:
$X_{l+1} = B_l X_l + C_l \mathcal{F}_l(A_l X_l)$
问题出在 B 上——这是个任意学习的方阵,当网络堆叠得很深时,它的谱范数容易失控,导致训练常崩。
mHC 的关键创新在于:强制将 B 约束在 doubly stochastic 矩阵流形(Birkhoff polytope)上。这就意味着 B 的每行、每列元素之和都为 1,且元素非负——本质上是个概率混合矩阵。这带来了两个直接好处:一是谱范数恒小于等于 1,残差变换永不膨胀,前向传播不爆炸,反向梯度也不消失;二是 doubly stochastic 矩阵在乘法下构成封闭群,深层堆叠时的稳定性可以安全传递。
在实现上,B 的原始参数 $\tilde{B}$ 经过 exp 后,用 Sinkhorn-Knopp 迭代跑 20 步做行列交替归一化,就能投影到规定的流形上。A 和 C 则用 sigmoid 函数将其限制在非负且有界的范围内。
直觉上理解:原版 HC 允许残差通路进行任意的线性变换;mHC 则将其收紧为“概率混合”,信息在跨层传递时,永远在进行重新分配,不会被某条路径无限放大或抹除。这相当于为残差通路添加了一条信息守恒定律。
从工程层面看,mHC 带来了额外的激活内存和流水线通信开销。论文通过融合 kernel、选择性重计算和调整 DualPipe 的 1F1B 重叠,最终将额外 wall time 控制在 1F1B 总时间的 6.7%。
Muon 优化器
Muon 替换 AdamW 的核心思想在于:放弃元素级的二阶矩估计,改为将动量矩阵通过 Newton-Schulz 迭代近似正交化之后,再进行权重的更新。
# Algorithm: Muon for DeepSeek-V4
G_t = ∇W L # 梯度
M_t = μ M_{t-1} + G_t # 动量
O'_t = HybridNewtonSchulz(μ M_t + G_t) # 正交化
O_t = O'_t · √max(n,m) · γ # rescale RMS
W_t = W_{t-1}(1 - ηλ) − η O_t # 衰减 + 更新
这里的 hybrid 指的是 NS 迭代分两段执行:前 8 步用激进的系数 (3.4445, −4.7750, 2.0315) 快速逼近,后 2 步切换到保守系数 (2, −1.5, 0.5) 将奇异值精确稳定到 1。
有几个工程细节颇值得关注。Embedding、prediction head、mHC 的静态 bias 和 RMSNorm 坚守 AdamW 不动;由于 V4 在 Q、K 上已加 RMSNorm,QK-Clip 不再需要。Muon 与 ZeRO 的兼容是主要工程难题——Muon 需要完整的梯度矩阵,这与 ZeRO 的参数切分天然矛盾。V4 的解法是用 knapsack 算法做 bucket 分配,将 MoE 参数 flatten 后尽力均匀切分,将 padding 开销控制在 10% 内。跨 DP rank 的梯度通信采用 BF16(随机舍入),并改为 all-to-all 加本地 FP32 求和的两阶段方式,规避 BF16 累加带来的误差。
一句话总结:Muon 抛弃了 Adam 那种逐个元素“摸索”方向的方式,转而直接对整个梯度矩阵做正交化,方向感更稳,收敛也更快;但代价是必须在工程上重新设计 ZeRO 的对齐流程。
基础设施:让这些设计真正能跑起来
若论内卷程度,V4 的 infra 部分可能是这篇论文最深邃的一环。
MegaMoE:一个 kernel 融合通信与计算
MoE 的瓶颈在于 Expert Parallelism(EP)带来的跨节点 all-to-all 通信。V4 提出了按 expert wave 分批调度的思路:把 experts 切成多个 wave,每个 wave 完成通信后立刻开始计算;与此同时,当前 wave 在计算、下一个 wave 在通信、已完成 wave 的结果在回传——三件事高度并发。整套逻辑被浓缩进一个 CUDA mega-kernel 中(已开源到 DeepGEMM)。
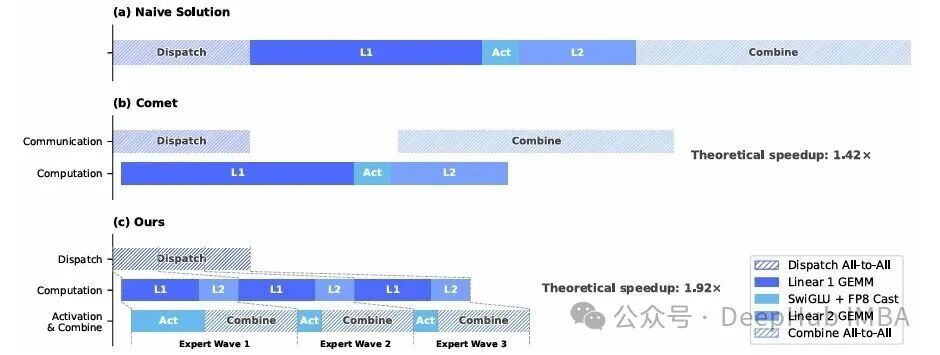
在通用推理场景下,相比强基线提速 1.5–1.73 倍,RL rollout 和高速 agent 场景最高能达到 1.96 倍。
更有启发意义的是论文对硬件设计的建议:通信能否被计算完全掩盖,本质上取决于 C/B(峰值算力 / 互联带宽),而不仅仅是堆带宽。对 V4-Pro 而言,C/B ≤ 6144 FLOPs/Byte 即可实现完全掩盖。这对未来 GPU 或 NPU 的互联设计具有现实的参考价值。
TileLang:用 DSL 替代手写 CUDA
V4 大量使用了 TileLang 来编写 fused kernel。其 Host Codegen 将主机端的检查、参数 marshalling 等全部在编译期生成,单次调用的 overhead 从几十微秒压缩到 1 微秒以下。Z3 SMT 求解器辅助的形式化整数分析可自动验证向量化、内存 hazard 和边界条件,将过去需要手工证明才能打开的优化全部自动化。在 Bitwise 可复现层面,该方案默认关闭 fast-math,提供显式的 IEEE-754 intrinsics(T.ieee_fsqrt 等),并对齐了 NVCC 的 lowering 顺序。
批不变 & 确定性 kernel:训练与推理的 bitwise 对齐
这对 RL 训练有着特殊的意义。V4 实现了端到端的 batch invariance(任意 token 的输出与其所处的 batch 位置无关)和确定性反向传播。
具体来说:Attention 采用双 kernel 策略来规避 split-KV 引入的 wave-quantization 问题;MatMul 放弃 cuBLAS 转而使用 DeepGEMM,并禁用 split-k;Attention 反向采用每 SM 独立 buffer 加全局确定性 reduction 来替换 atomicAdd;MoE 反向则通过 token 顺序预处理与 buffer 隔离消除了多 rank 写冲突。当训练和推理能达到 bitwise 一致时,RL 中令人头疼的采样分布偏移问题能得到缓解,调试体验更是质变。
FP4 QAT:把 MoE 权重再砍一半
V4 在 post-training 阶段对两类参数引入了 MXFP4 量化感知训练:占据 GPU 显存大头的 MoE 专家权重,以及推理时的热路径——CSA indexer 的 QK 路径。
有趣的是,FP4 → FP8 的 dequant 过程是无损的。因为 FP8(E4M3)比 FP4(E2M1)多了 2 个指数位,只要每个 FP8 量化块(128×128)内部的 FP4 sub-block scale 比值不超过特定阈值,FP4 的细粒度 scale 就能被 FP8 的动态范围完全吸收。整套 QAT 流水线可直接复用现有的 FP8 训练框架,反向传播无需任何修改。推理时则使用真正的 FP4 权重,避免了 simulated quantization 造成的双倍读写开销。论文还顺手将 indexer 的 index score 从 FP32 量化到 BF16,top-k selector 提速 2 倍,KV recall 依然保持在 99.7%。
推理框架:异构 KV Cache 与三档 on-disk 策略
V4 的 KV Cache 是异构的:CSA 有压缩 KV 和 indexer KV,HCA 有更激进的压缩 KV,所有层还有 SWA 滑窗 KV,而 CSA/HCA 还得管理未压缩的尾端 token。
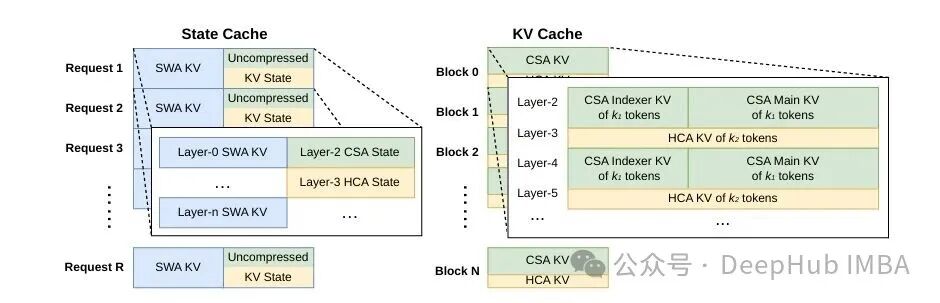
V4 将 KV Cache 拆解为两块。定长的 State Cache 按 request 预分配,存储 SWA KV 和尚未达到压缩边界的尾端 token。经典的 KV Cache 则分块管理,每块覆盖 lcm(m, m')=128 个原始 token,对应 32 个 CSA 压缩条目加上 1 个 HCA 压缩条目。
对于共享前缀的请求场景(典型的 RAG 或多轮 agent),V4 将压缩 KV 落盘复用,避免重复 prefill。SWA KV 因为未压缩,数据量是 CSA/HCA 的 8 倍,为此提供了三档策略:Full(全量存储)、Periodic(定期 checkpoint)、Zero(不存,依靠 CSA/HCA cache 重算最后 $n_{win} \cdot L$ 个 token),用户可根据存储与算力的配比灵活选择。
训练流程:32T token 预训练与多专家蒸馏
预训练:4K → 1M 的渐进式扩展
数据层面,整个训练消耗 32T+ 的 token,相比 V3 大幅度增强了多语言、长文档、数学/代码、agentic 数据的比例。遮蔽策略也从 V3 的 doc-level 改为了更细粒度的 sample-level attention masking。在课程上,序列长度按照 4K → 16K → 64K → 1M 的思路逐步扩展;注意力机制也先经历 1T token 的纯密集训练,然后再切换到稀疏模式。
模型规模上,V4-Flash 为 43 层、hidden 4096、256 路由 expert、6 激活、激活参数 13B、总参 284B;V4-Pro 则达到 61 层、hidden 7168、384 路由 expert、6 激活、激活参数 49B、总参 1.6T。Muon 的 RMS rescale γ 被调至 0.18,使其能直接复用 AdamW 的学习率超参;峰值 LR 在 Flash 上是 2.7e-4,Pro 则为 2.0e-4。
训练稳定性:两个“机制不明但有效”的技巧
万亿级 MoE 训练中,loss 一旦出现 spike,有时连 rollback 都救不回来。根源常是 MoE 层产生的 outlier 在路由机制的反馈下被自我放大。V4 给出了两剂连作者都坦言“理论上还未完全搞清楚”的解药。
Anticipatory Routing(前瞻路由)
在第 t 步,使用历史参数 $\theta_{t-\Delta t}$ 计算路由 index,但用当前参数 $\theta_t$ 计算特征。这便将 backbone 的更新与 router 的更新解耦,旨在打断 outlier → 路由倾斜 → 更大 outlier 的恶性循环。工程上通过提前 Δt 步预取数据并缓存 routing index,将额外 wall time 控制在约 20%。更巧妙的是,这一机制仅在检测到 loss spike 时才短暂启用,平稳后即切回标准训练,长期开销几乎为零。
SwiGLU Clamping
将 SwiGLU 的 linear 分量 clip 到 [-10, 10],gate 分量上限设为 10。做法简单直接,却有效抹除了激活层上的异常值。两个技巧双管齐下,整个 V4 系列的训练就再没崩过。
有一点很特别:DeepSeek 将“我们还不知道它为什么 work”这件事,坦率地写进论文正文并邀请社区一起探索。这种开放姿态在日渐封闭的环境里,已然成为一道独特的风景。
后训练:抛弃混合 RL,全面转向 OPD
这是 V4 与 V3.2 在方法论上最大的分水岭。
V3.2 时代走的是先 SFT,再 RL,将多种能力混在一起训练的路子。V4 的流程则一分为二:先做专家培养——对数学、代码、agent、指令跟随等各领域独立进行 SFT 加 GRPO RL,得到一组 specialist;再做 OPD 合并——让一个 student 模型在自己采样的 trajectory 上,同时对全体 specialist 的 logits 进行蒸馏。
OPD 的 loss 是经典的多教师反向 KL 散度:
$\mathcal{L}_{\text{OPD}}(\theta) = \sum_i w_i \cdot D_{\text{KL}}(\pi_\theta \| \pi_{E_i})$
关键在于,V4 没有采用 token-level KL 这种资源节约但梯度方差大的简化版,而是执行了全词表 logits 蒸馏。面对多个万亿级教师的 logits,工程方案分四步走:教师权重全部 offload 到分布式存储,按需加载;只缓存最后一层的 hidden state,训练时再过 prediction head 在线重建 logits,以此规避 100K+ 词表的 logits 物化;按 teacher index 排序数据,确保每个 mini-batch 只加载一次 teacher head;使用 TileLang 专门编写 KL 散度 kernel。
这套设计理论上支持近乎无上限的教师数量与万亿级参数的结合。论文承认,这种范式比传统的混合 RL 更稳定,并有效规避了多目标 RL 中普遍存在的“能力互蚀”问题。
推理模式:三档思考预算与交错思考
V4 提供三档思考模式:Non-think、Think High、Think Max。这三档模式是在 RL 阶段通过不同的长度惩罚与上下文窗口训练出来的;其中 Think Max 依赖专门的 system prompt 来引导深度推理。工具调用场景中的 thinking trace 可以跨用户消息保留——这充分利用了 1M 上下文——而 V3.2 在每个新的 user turn 都会清空。当然,在普通对话场景中,V4 依然会清空思考链,以防止上下文无谓膨胀。
另一个工程亮点是 Quick Instruction:将是否触发搜索、意图识别、标题生成这类辅助任务用特殊 token 直接拼接到输入末尾,复用已有的 KV cache 并以并行方式执行。这彻底消除了在主模型旁挂一个小模型所带来的工程债。
性能表现:开源的新天花板,距前沿闭源仍有 3–6 个月差距
V4-Flash-Base 已吊打 V3.2-Base
13B 激活的 Flash 在大部分指标上已然超越 37B 激活的 V3.2。这个对比清晰地将参数规模与参数效率剥离开来看,说明 V4 的架构改进是有效果的,并非单纯靠堆参数。
V4-Pro-Max:开源新巅峰
亮点摘要:
- SimpleQA-Verified 取得 57.9,领先所有现有开源模型约 20 个百分点,但与 Gemini-3.1-Pro(75.6)仍有差距;
- Codeforces 拿到 3206 分,人类排名第 23,首次有开源模型在编程竞赛上与 GPT-5.4(3168)基本打平甚至微幅领先;
- HMMT 2026 Feb 达 95.2、IMOAnswerBench 89.8、Apex Shortlist 90.2,数学推理能力已触达第一梯队边缘;
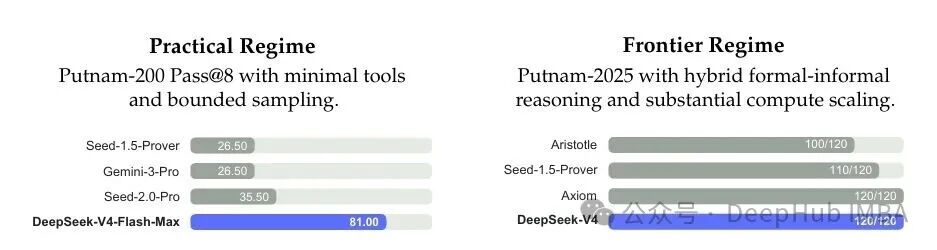
- PutnamBench Frontier Regime 取得 120/120 满分,与 Axiom 持平;
- 1M MRCR 在 1024K 长度的上下文上依然保持 0.59 的 MMR,表现全程稳定。
在 Agent 能力方面,Terminal Bench 2.0 拿到 67.9(Verified 子集约 72.0);SWE Verified 80.6,与 Opus-4.6、Gemini-3.1-Pro 处在同一档次;BrowseComp 83.4,仅次于 Gemini-3.1-Pro。在内部代码 R&D 评测中,DeepSeek-V4-Pro-Max 以 67% 的通过率,超过了 Claude Sonnet 4.5(47%),逼近 Opus 4.5(70%)。
现实任务:中文用户体会最深的胜负
这是论文里被讨论最少、却也是中文用户体感最强的部分。
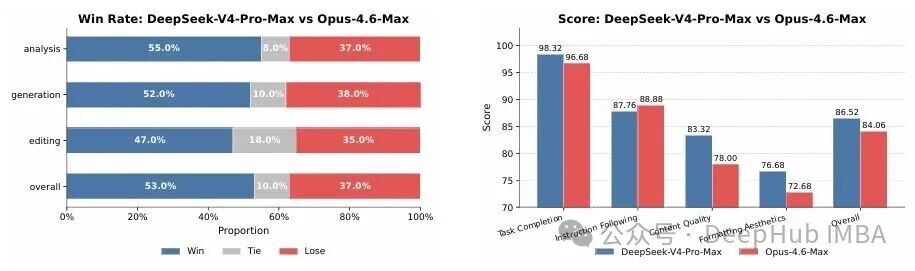
中文功能性写作方面,V4 对 Gemini-3.1-Pro 的胜率为 62.7% 比 34.1%;Gemini 的一大症结是常以自己的风格偏好覆盖用户的明确要求。创意写作上,V4 指令遵循胜率 60.0%、写作质量胜率 77.5%;而在挑战最大的多轮加复杂指令子集里,Claude Opus 4.5 依然以 52.0% 比 45.9% 胜出。在 30 项中文白领任务对比 Opus-4.6-Max 的评测中,V4 综合非负率达 63%——它在任务完成度和内容质量上更有优势,而 Opus 在格式美观度上仍略胜一筹。
Reasoning Effort 的 token 经济学
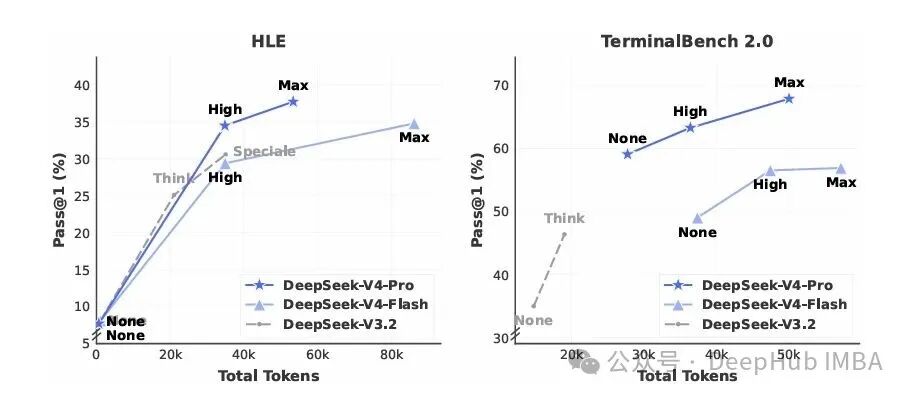
这张图传递的最有价值信息是:在相同的 token 预算下,V4-Pro 相比 V3.2 展现了更高的 token 效率——单位思考 token 换来的性能增益更多。这正是混合稀疏注意力与 Muon 优化器共同作用的结果。
批判性思考:V4 尚未解决的,和一些值得追问的问题
论文本身列出了三类局限性。将它们与我的个人观察合并后,整理成以下几个值得持续追问的方向。
论文承认的局限
首当其冲的是架构的复杂度。CSA 加 HCA 加 mHC 加 Muon 加 FP4 加 Anticipatory Routing 加 SwiGLU Clamping,有太多的技巧堆叠在一起,V4 团队自己也说未来必须做减法。其次是机制的不明确——Anticipatory Routing 和 SwiGLU Clamping 为什么起作用,在理论层面尚无法清晰阐释。第三条是距前沿仍有 3–6 个月的差距:在核心推理维度上,V4-Pro-Max 仍不及 GPT-5.4 与 Gemini-3.1-Pro。
几个值得紧盯的点
CSA 的 top-k=512/1024 是否足够?在 1M 上下文中,压缩后约 7800 个条目,top-k=1024 意味着仅“注意”了其中 13%。这个比例在哪些任务上会成为新的瓶颈,需要更多消融实验来揭示。
mHC 的 Sinkhorn 20 步迭代会不会成为下一个训练瓶颈?每层都要进行一次行列归一化迭代,持续下去是否需要在算法层面寻找近似方案,论文并未给出明确答案。
FP4 QAT 的稳定性边界——目前仅在 post-training 阶段引入,全程预训练是否可行?这关系到下一代模型能否直接进行 FP4 训练。
OPD 替代 RL 的代价。OPD 本质上是离线模仿(尽管轨迹是 on-policy 采样),它毕竟失去了 RL 在 reward landscape 上的探索能力。在更长周期、奖励更稀疏的任务上,这种范式是否会吃亏,仍有待更长时间的检验。
Anticipatory Routing 的超参数 Δt 并未披露,而这个参数值的选取本身,就足以支撑起一篇消融分析。
横向对比同期开源工作
Kimi K2.6 与 GLM-5.1 走的是更标准的稀疏 MoE 加长上下文路线,并未对架构做出如此深度的改造。Qwen3 与 MiniMax-M2 在注意力机制上的探索更为保守,但训练数据的规模可以媲美。V4 的差异化定位在于通过更激进的架构设计来换取长上下文处理能力与推理效率,其代价是极高的工程复杂度——短期内,这套方案别人不易复现。
最后总结
DeepSeek-V4 这篇论文最值得铭记的,或许不是某个具体的 SOTA 数字,而是它贡献给开源社区的几个可以独立拿走的模块化思路:CSA 加 HCA 组合,为长上下文效率开辟了一个比 sliding window 或 linear attention 更务实的新方向;mHC 为 hyper-connections 装上了数学的护栏,有潜力成为下一代残差连接的标配;Muon 加 ZeRO 的兼容性方案,让非 element-wise 优化器在大规模训练中真正落到了实处;MegaMoE、TileLang、批不变 kernel 这套 infra,哪怕单独拎出来都足够支撑起一篇系统性的论文;而 OPD 流水线则提供了混合 RL 之外的第二条路线——从多教师到单学生的全词表蒸馏。
更为重要的是,DeepSeek 将这些设计的开源实现一并公开——MegaMoE、CSA/HCA 推理代码、Muon 训练流程,在 HuggingFace 上都能找到。在闭源渐成主流、技术报告日益含糊的今天,这种既写论文又放代码的做法本身就弥足珍贵。
V4 是不是开源界最强?在大部分指标上是。是不是已经追平 GPT-5.4 与 Gemini-3.1-Pro?还差一点,但它已经将差距压缩到了 3–6 个月。真正的深远影响在另一面:当百万上下文从一个昂贵的玩具,演变成日常可跑的工作负载时,下一波 agentic 应用、长周期任务、在线学习的探索将迎来全新的基础设施底座。这才是 V4 系列真正的分量所在。
 发表于 2026-4-29 00:30:12
|
查看: 646|
回复: 0
发表于 2026-4-29 00:30:12
|
查看: 646|
回复: 0
