此次 DeepSeek V4 发布,推出了两个核心模型:
- Pro 版本:1.6T 参数,面向高端复杂任务
- Flash 版本:284B 参数,强调高性价比与响应速度
两者均支持 1M 上下文长度,这意味着在长文档分析、代码库理解以及复杂推理等场景中,模型能力实现了质的跃迁。
然而,许多讨论仍停留在一个相对浅层的观察上:DeepSeek 把价格打下来了。
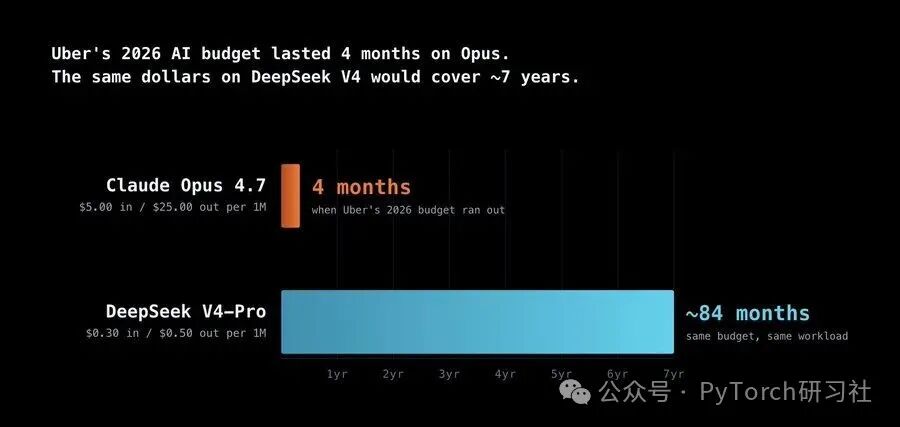
这类比较之所以显得单薄,是因为它预设了一个前提:全球 AI 竞争仍处于同一个技术与供应链环境之中。但现实是,这个前提正在瓦解。请细看定价策略下方的那行小字:
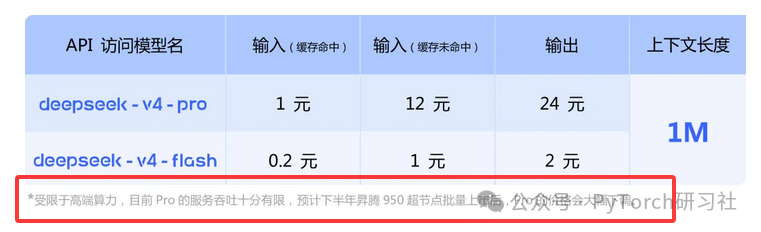
这恰恰揭示了当前国内 AI 行业的核心矛盾:模型能力的增速,已然超越了算力供给的增速。尤其在 Nvidia 高端 GPU 受限的背景下,企业即便手握先进模型,也可能面临算力跑不满、服务供不应求的局面。
过去我们谈论互联网、移动应用,它们更多是商业层面的竞争。但 AI 已经跨越了那条边界,演化成一种类似于能源、半导体、航天领域的“基础性能力”。换句话说:AI 不再只是企业的产品,而是国家能力的放大器。
一个国家的 AI 实力,直接取决于:
- 算力获取能力
- 芯片设计与制造能力
- 能源供给(数据中心本质上是电力机器)
- 软件生态与工程体系
这也是为什么 AI 会被越来越多地纳入国家战略框架——它的外溢效应实在太强了。
DeepSeek 在 V4 的相关说明中提到一个关键现实:高端算力供给存在硬约束,甚至不足以支撑 Pro 模型规模化服务。这句话若放在五年前,几乎不可想象。那时我们默认的世界是:NVIDIA GPU 可以全球流通、云计算能按需购买、技术扩散单向且持续。
但现在,算力开始呈现出一种全新的特征:阵营化分布。一边是以 NVIDIA 为核心的算力体系,另一边则在加速构建替代路径。DeepSeek 选择大规模部署华为昇腾(Ascend),从本质上讲,这并非单纯的【成本优化】,而是在做一件更为根本的事情:构建一个不依赖外部关键节点的算力闭环。
这已超越了传统意义上的国产替代,更接近冷战时期的技术体系分叉。DeepSeek 计划在 2026 年部署 950 个 Ascend 超节点,这个数字的意义不在于规模本身,而在于其背后的结构转变:从购买算力,到生产算力。
过去,企业更多是向云厂商采购 GPU 资源;而现在,风向正转向自建、定制、优化整套算力体系。这意味算力正从一种“商品”变成一项“资产”,企业行为也从单纯的成本优化,升级为系统的风险对冲。毕竟,如果只是商业决策,选择更便宜的 GPU 就够了;但现实是,部署 Ascend 同时在化解三类风险:
这是一种典型的地缘政治驱动下的工程决策。当模型公司、芯片厂商(如华为)、数据中心与能源系统开始深度协同优化时,竞争的基本单位就不再是一家公司,而是“技术体系”之间的整体较量。
DeepSeek V4 的另一大亮点是其极具攻击性的定价,以及明确的“未来还会更便宜”的信号。很多人把这理解为一场价格战,但如果放在宏观视角下审视,这更像是工业能力在数字世界的一次投射。
模型推理成本,本质上由三件事共同决定:
- 芯片(制造能力)
- 电力(能源体系)
- 系统优化(工程能力)
当一个国家在这些领域形成规模优势时,它就可以在 AI 服务价格上构筑起类似制造业的强大压制力。这与过去十年我们在钢铁、光伏,甚至如今电动汽车等行业中反复出现的模式高度相似。
当前,全球 AI 发展正浮现出两种截然不同的逻辑:
- 路径一:效率最大化
- 代表:以 NVIDIA 生态为核心的体系
- 特点:
- 使用最先进的硬件
- 追求性能极限
- 高度依赖全球供应链
- 路径二:体系韧性最大化
- 代表:以华为昇腾等为核心的路径
- 特点:
- 在受限条件下持续优化
- 强调自主可控
- 接受短期性能折损,换取长期稳定性
这两种路径不单是技术选择,更折射出两种迥异的国家风险偏好与战略思维。在此框架下,DeepSeek 的角色也随之发生嬗变——它不再只是一家发布前沿模型的 AI 公司,更像是一个将底层结构变化显性化的“信号放大器”。
通过 V4,它同时释放了三重信息:
- 高端模型能力已逼近新的天花板
- 算力供给成为核心制约瓶颈
- 替代性算力体系正在加速落地
如果说过去几年 AI 的分水岭是——谁能做出 Claude Opus 4.7 级别的模型,那么未来的分水岭将演变为:谁能在不确定的全球环境中,持续、稳定地运行这些模型。
这不再取决于单点技术的突破,而是取决于一整套系统的协同:
DeepSeek V4 的真正意义,就在于它让这场原本隐匿的竞争开始变得清晰起来:AI 竞赛早已不局限于技术本身,而是一场围绕基础设施、工业能力与国家战略的全面博弈。
 发表于 2026-4-27 21:41:51
|
查看: 151|
回复: 0
发表于 2026-4-27 21:41:51
|
查看: 151|
回复: 0
