4月24日,深度求索扔下一枚“技术核弹”:DeepSeek-V4 系列正式发布。它不只是一头性能怪兽,更像是一场成本革命——将处理百万字长文本的花费,从“实验室级别”直接打到了“白菜价”。这背后,是一系列堪称“暴力美学”的架构创新。
Part 1:一场“不讲武德”的降维打击
当其他大厂还在为数万 token 的处理成本焦头烂额时,DeepSeek-V4 直接甩出了两个王炸:
- V4-Pro:1.6万亿参数,性能比肩 GPT-4o,处理百万 token 的计算开销,仅有前代的 27%。
- V4-Flash:极致性价比,同等开销下,上下文窗口直接扩大 16倍。
这意味着什么?意味着你可以把一整本《三体》丢给 AI 让它分析,而成本和之前让它读一篇短文差不多。这不是简单的迭代,这是一场对行业定价和性能认知的“降维打击”。

Part 2:核心黑科技——“略读”与“精读”的机器革命
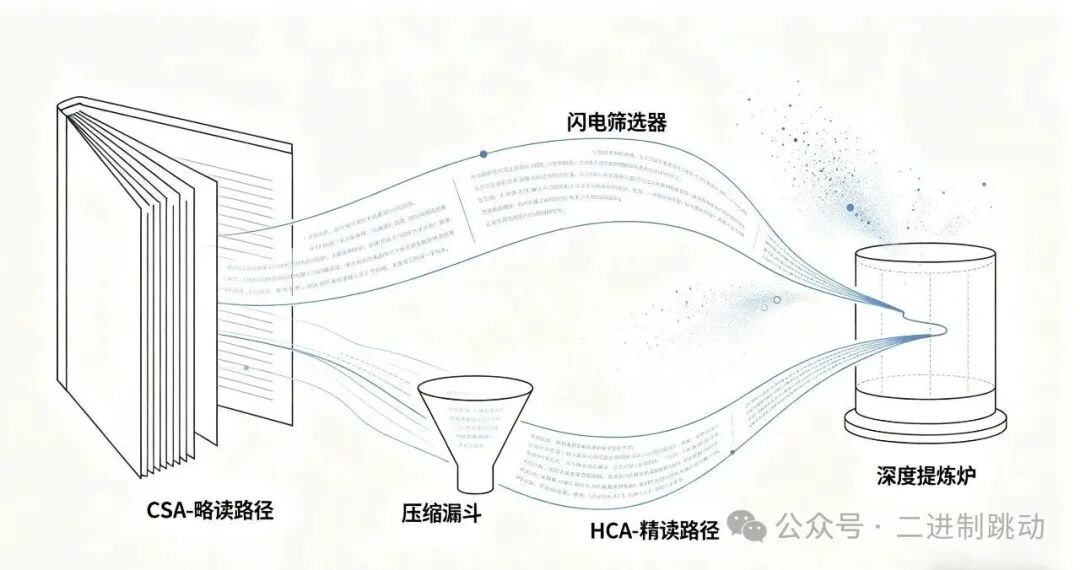
实现这一奇迹的核心,是一个名为 “混合注意力” 的架构。它聪明地模仿了人类阅读长篇巨著时“先用略读把握脉络,再用精读消化细节”的高效模式。
-
压缩稀疏注意力(像“略读”)
将每 128 个字压缩成 1 个“段落大意”,然后快速扫描全文,只挑出最相关的 1024 个段落进行精算。这一步,把原本平方级增长的计算量,硬是压到了接近线性。
-
高度压缩注意力(像“精读”)
在“略读”选出的重点段落内部,进行更深度的信息提炼,保证不丢失关键“韵味”。
这两种注意力在模型内部交替出现,就如同一位最高效的阅读者,在信息的海洋中精准捕捞。
Part 3:万亿参数的“模块化”智慧
V4-Pro 高达 1.6 万亿参数,但绝非蛮力堆砌。它采用了先进的 MoE(混合专家) 架构。
- 你可以把它理解成一个“超级咨询公司”,内部有 384 个各有所长的专家(数学、文学、编程等)。
- 每当你提出一个问题,一个“路由网络”会根据问题类型,只请出 6位 最相关的专家来协同回答。
- 这样一来,在保持“公司”整体知识库异常庞大的同时,每一次“咨询服务”的实际开销却非常经济。

Part 4:不仅仅是模型,更是一场生态突围
DeepSeek-V4 最深远的意义,或许不在于模型本身,而在于它和 国产AI芯片 的深度融合。
北京智源研究院已成功将其部署在 海光、昇腾、摩尔线程 等 8 款以上国产芯片上。这意味着:
- 算力自主:中国大模型有了不依赖英伟达 CUDA 生态的“第二选择”。
- 软硬协同:从框架、算子到并行策略的全栈优化,开辟了一条“自主可控”的新路径。
这不仅是技术上的胜利,更是战略卡位的胜利。
DeepSeek-V4 的发布,标志着一个新时代的开启。当“百万上下文”从昂贵的技术炫技变为普惠的经济标配,真正的应用爆发才可能到来——长文档分析、代码库级开发、终身 AI 记忆伴侣……
这一次,中国团队没有跟随,而是用一场极致的“工程暴力”与“架构美学”,重新定义了游戏的规则。 |  发表于 2026-4-27 20:03:57
|
查看: 154|
回复: 0
发表于 2026-4-27 20:03:57
|
查看: 154|
回复: 0
