L8.院士
5880
0
762
昨天大模型发布,包括 DeepSeek-V4-Pro(1.6T总参数/49B激活,61层,隐藏维度7168,Pro用于知识、推理、长文本等高要求任务)与 DeepSeek-V4-Flash(284B总参数/13B激活,43层,隐藏维度4096,用于低成本、低延时的推理与轻量化部署) 两款 MoE 模型,原生支持 100 万 token 上下文。
开源链接在:https://huggingface.co/collections/deepseek-ai/deepseek-v4,https://modelscope.cn/collections/deepseek-ai/DeepSeek-V4DeepSeek-V4,技术报告在 https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf。
具体工程侧的不谈,看看 DeepSeek V4 的一些功能点:
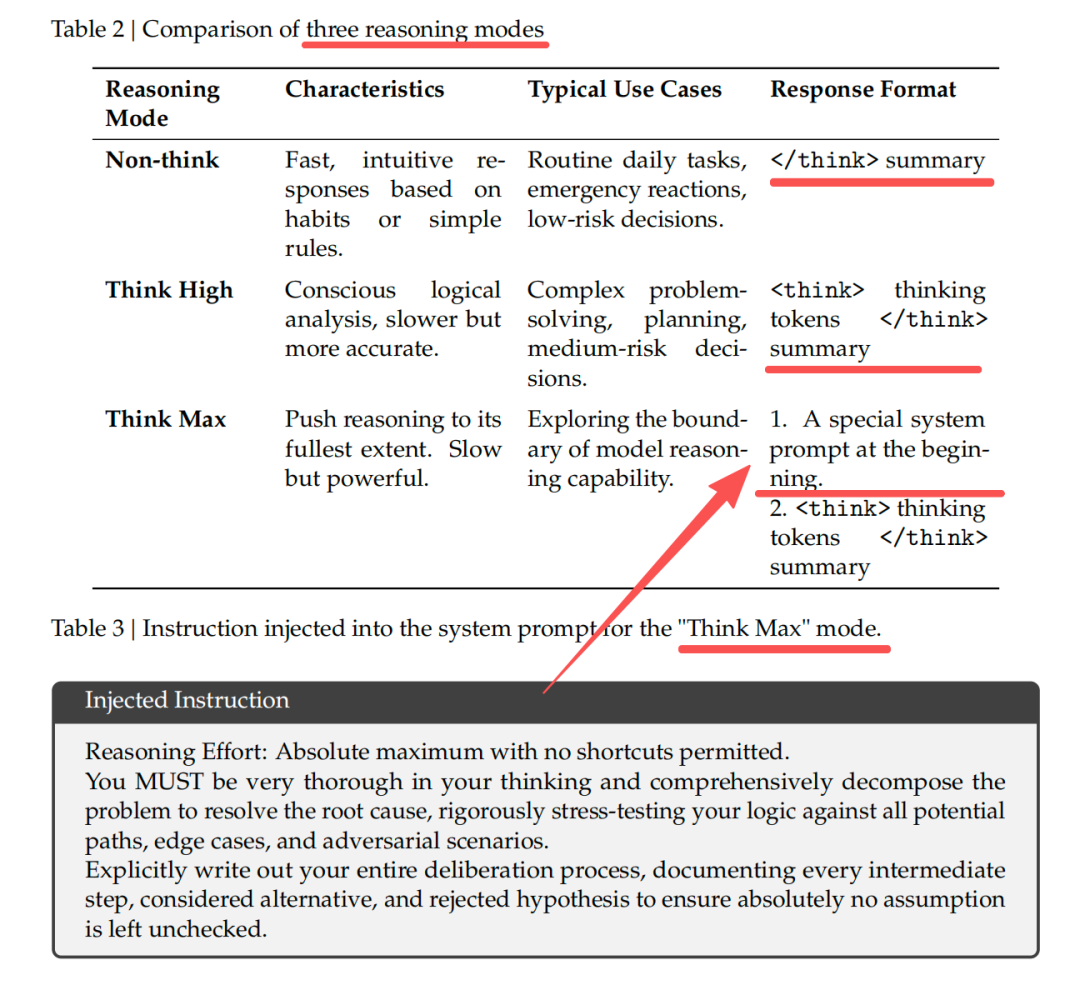
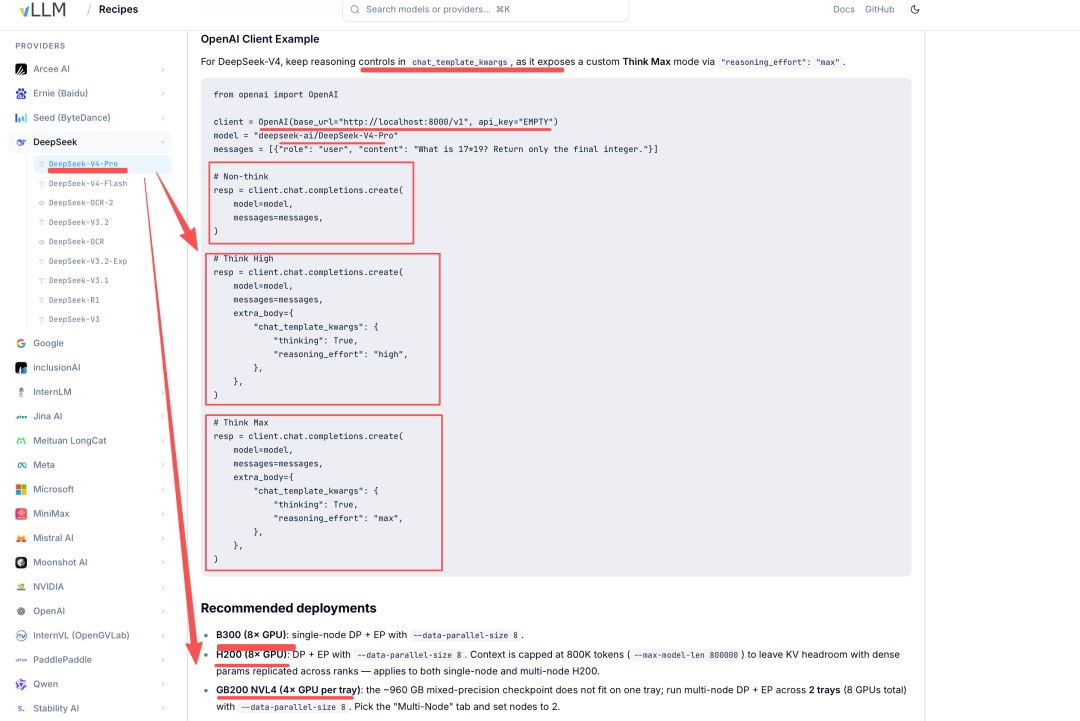
模型推理任务性能由计算投入决定,DeepSeek-V4-Pro/Flash 均支持三种推理强度模式:无思考(Non-think)、高思考(Think High)、最大思考(Think Max),在输出最终回答之前,模型会先输出一段思维链内容,以提升最终答案的准确性,这个在技术报告中论述如下:
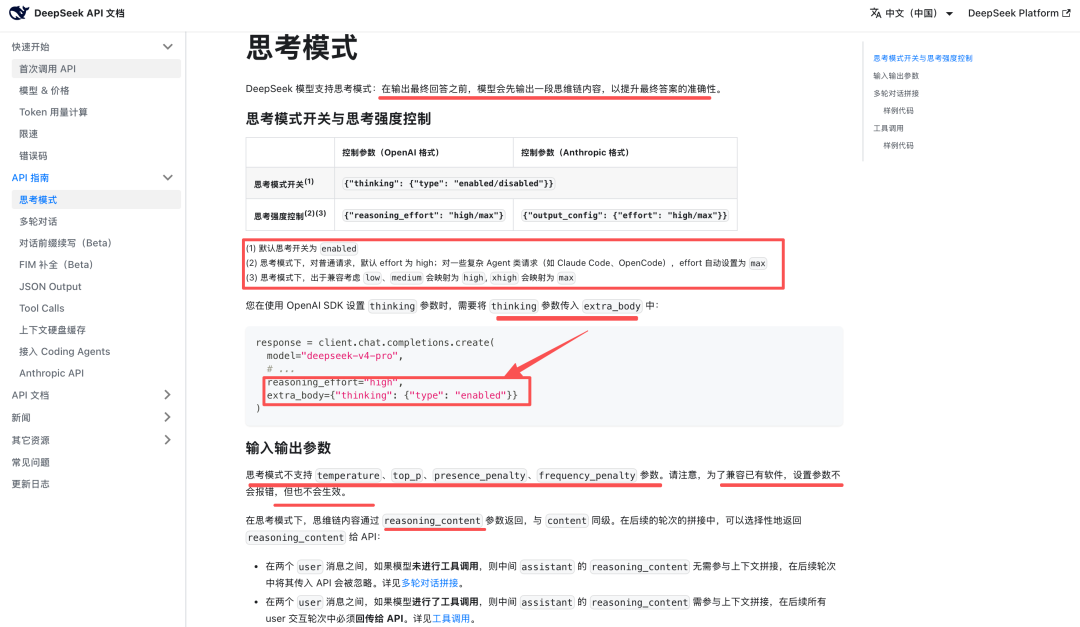
在具体使用上,可以看官方文档:https://api-docs.deepseek.com/zh-cn/guides/thinking_mode,可以通过 thinking 参数开启思考模式,并通过 reasoning_effort 控制思考强度。
默认思考开关为 enabled,思考模式下,对普通请求,默认 effort 为 high;对一些复杂 Agent 类请求(如 Claude Code、OpenCode),effort 自动设置为 max,出于兼容考虑 low、medium 会映射为 high,xhigh 会映射为 max。
这里注意:思考模式不支持 temperature、top_p、presence_penalty、frequency_penalty 参数。为了兼容已有软件,设置参数不会报错,但也不会生效。
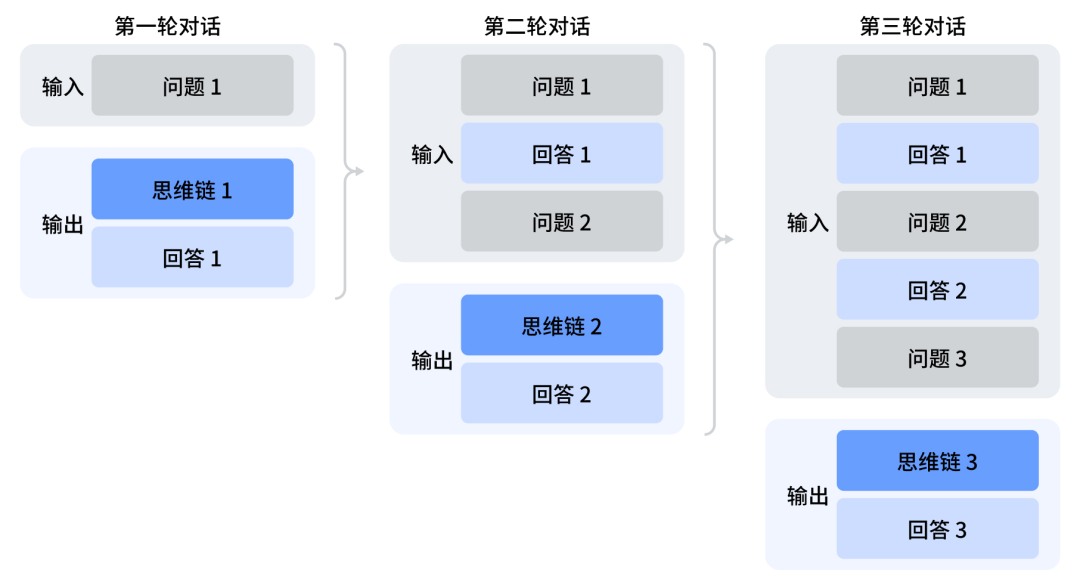
此外,如果多轮对话拼接,在每一轮对话过程中,模型会输出思维链内容(reasoning_content)和最终回答(content)。如果没有工具调用,则在下一轮对话中,之前轮输出的思维链内容不会被拼接到上下文中。
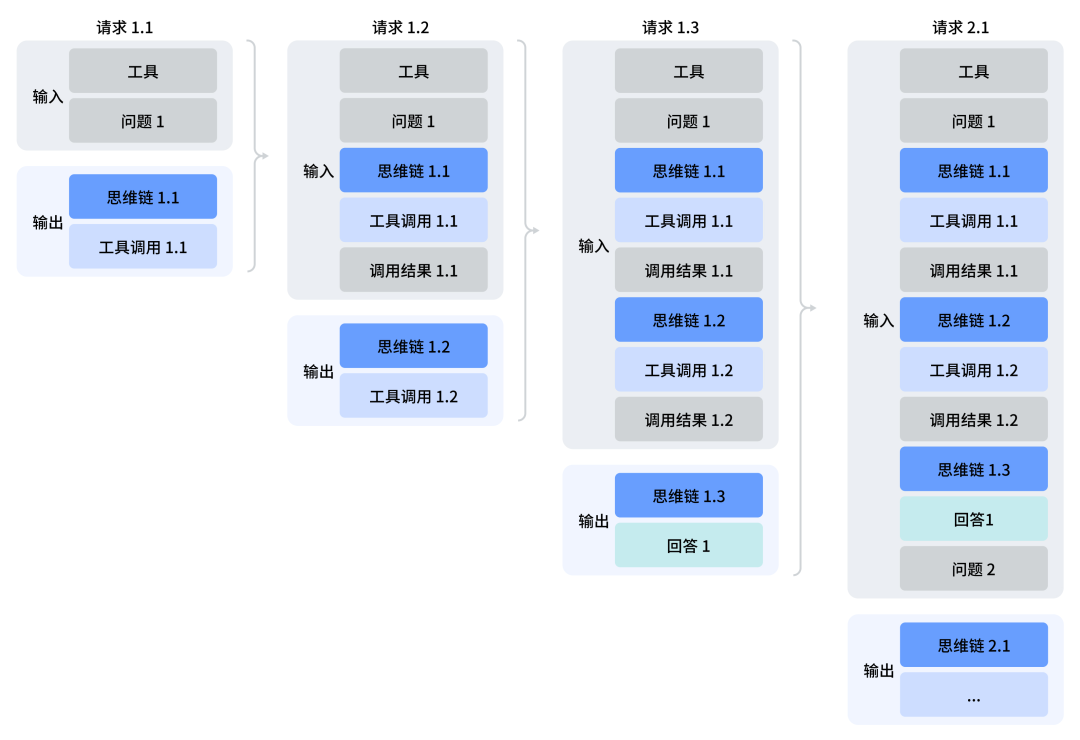
思考模式支持工具调用功能。模型在输出最终答案之前,可以进行多轮的思考与工具调用,以提升答案的质量,但是:区别于思考模式下的未进行工具调用的轮次,进行了工具调用的轮次,在后续所有请求中,必须完整回传 reasoning_content,从而让模型继续之前的思考。
例如:在 Turn1 的每个子请求中,都携带了该 Turn 下产生的 reasoning_content,从而让模型继续之前的思考,且在 Turn2 的请求中,仍然携带着 Turn1 所产生的 reasoning_content,这里的逻辑是继承 工具调用的累积效应。
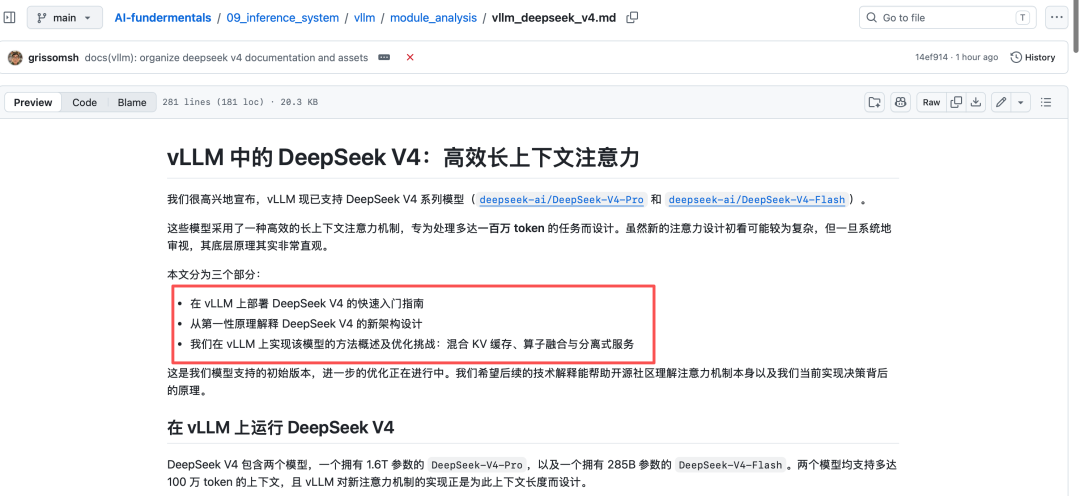
vLLM 现已支持 DeepSeek V4 系列模型(deepseek-ai/DeepSeek-V4-Pro 和 deepseek-ai/DeepSeek-V4-Flash),文档在:https://github.com/ForceInjection/AI-fundermentals/blob/main/09_inference_system/vllm/module_analysis/vllm_deepseek_v4.md,从中还可以顺便看看对应的一些架构上的解读。
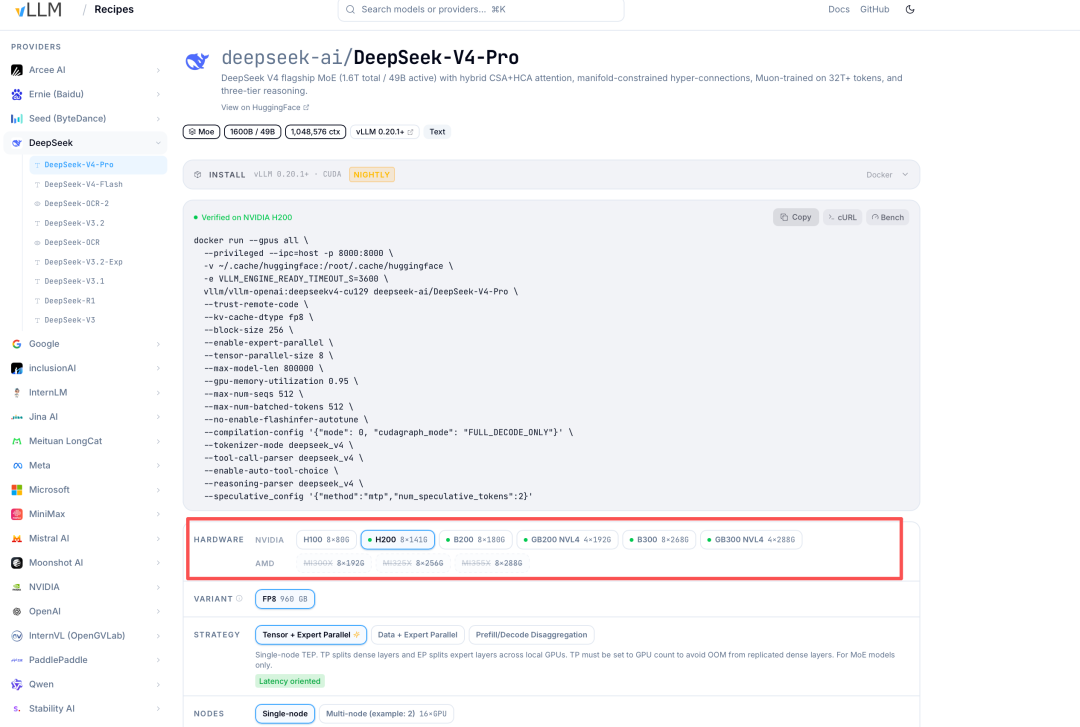
另外,在 https://recipes.vllm.ai/deepseek-ai/DeepSeek-V4-Pro?features=tool_calling%2Creasoning%2Cspec_decoding 中,可以看看具体的思考模式调用方式:
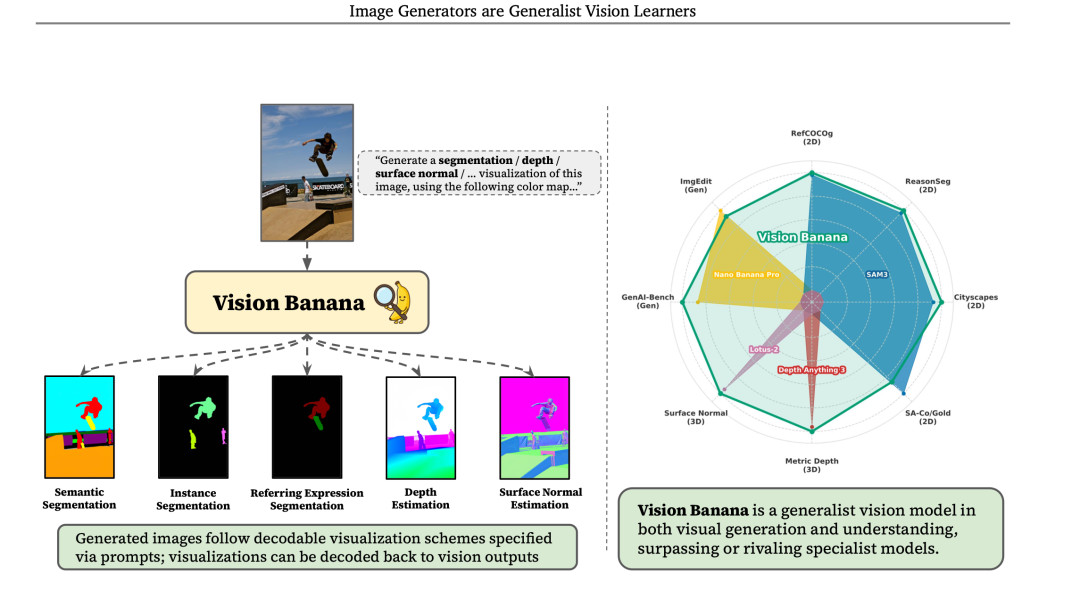
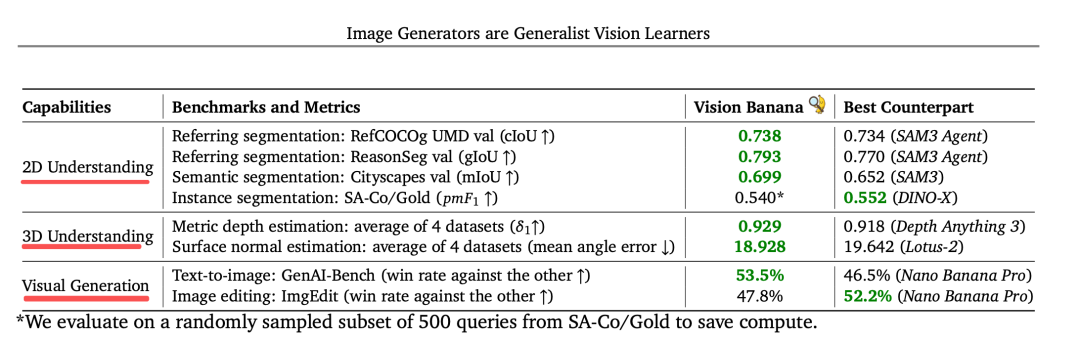
来看一个视觉方面的新思路,Google DeepMind 提出 VisionBanana,通过对 NanoBananaPro 进行轻量级指令微调,证明图像生成器是通用视觉学习器;该模型以 RGB 图像生成统一视觉任务接口,在 2D 分割、3D 深度/法向估计等任务上超越 SAM3、DepthAnything3 等专业模型,且完整保留图像生成与编辑能力。
它想说明的是,image understanding and generation 这两个任务,可以通过一个模型来做。
工作在《Image Generators are Generalist Vision Learners》,https://vision-banana.github.io,https://arxiv.org/pdf/2604.20329,可以看几个点:
现有视觉表示学习以判别式、对比学习、自编码为主(判别式监督学习(CNN、ViT)、对比学习(MoCo、SimCLR、CLIP)、掩码自编码(MAE、iBOT)),所以,是否可以假设:图像生成预训练等价于 LLM 预训练,可习得通用视觉表示,最新文生图/图生图模型(FLUX、NanoBananaPro、GPT-Image)有 零样本理解能力。
所以,可以假设图像生成是视觉任务统一接口,将所有 视觉理解 任务统一为 RGB 图像生成任务,通过对图像生成模型做轻量级指令微调,实现“一个模型同时搞定生成与理解”,核心就是不训练理解能力,只训练“按指令输出可解码 RGB”。
来看看具体做法,分 训练数据跟训练模型 两个方面。主要针对的其实还是 分割任务。
训练模型上,基于 NanoBananaPro,做轻量级指令微调,将分割、深度估计、法向估计等全部转为 RGB 图像生成任务,输入:原图 + 自然语言指令,输出一张标准 RGB 图,RGB 图可以可逆解码回任务标签(掩码、深度值、法向向量)。
训练数据方面,数据上使用原始生成数据 + 少量视觉任务数据,其中:
2D 理解任务数据【语义分割、实例分割、指代表达分割,使用网络爬取的自然图像、用Google内部自动标注模型生成掩码标签、无人工标注、无SAM类大规模掩码数据。输入:原图+文本指令(指定颜色映射),输出:可解码的 RGB 掩码图】;
3D 理解任务数据【单眼度量深度估计(Metric Depth)、表面法向量估计(Surface Normal),数据使用完全合成数据(渲染引擎生成),输入:RGB 渲染图,输出:可逆深度 RGB 图/法向 RGB 图】。
1、https://api-docs.deepseek.com/zh-cn/news/news260424
2、https://api-docs.deepseek.com/zh-cn/guides/thinking_mode
3、https://arxiv.org/pdf/2604.20329
4、https://github.com/ForceInjection/AI-fundermentals/blob/main/09_inference_system/vllm/module_analysis/vllm_deepseek_v4.md
5、https://recipes.vllm.ai/deepseek-ai/DeepSeek-V4-Pro?features=tool_calling%2Creasoning%2Cspec_decoding
收藏0回复 显示全部楼层 举报
发表回复 回帖后跳转到最后一页
手机版|小黑屋|网站地图|云栈社区 ( 苏ICP备2022046150号-2 )
GMT+8, 2026-7-28 19:20 , Processed in 1.313360 second(s), 42 queries , Gzip On.
Powered by Discuz! X3.5
© 2025-2026 云栈社区.
 发表于 2026-4-27 00:54:51
|
查看: 501|
回复: 0
发表于 2026-4-27 00:54:51
|
查看: 501|
回复: 0