100万token是什么概念?想象一下,把整部《红楼梦》原文、所有脂批、几篇学术论文和一份完整代码库全塞进去,模型还能精准定位你要的信息。不止V4,DeepSeek还开源&更新了三个开源项目
这件事本身不算新鲜,Gemini 和 Claude 都号称支持超长上下文。但 DeepSeek V4 做到了一件不一样的事:它把百万 token 的推理成本压到了上一代 V3.2 的 十分之一。KV cache 只需要 10%,单 token 推理 FLOPs 只有 27%。
这意味着“超长上下文”终于从展示品变成了可以 日常用 的东西。

旧做法哪里不够
在 DeepSeek V4 之前,超长上下文大致有几条路:
一条是硬扛。 把上下文长度拉上去,KV cache 随着序列线性增长,推理到后面每个 token 都要背着前面所有 token 的记忆包袱。Gemini 1M 和 Claude 的扩展上下文本质上都在走这条路,成本很高。
另一条是检索增强(RAG)。 既然一次性塞不下,那就先从外部知识库检索相关片段,只把相关内容喂给模型。这是目前绝大多数企业级应用的标准做法。但 RAG 有一个根本问题:检索质量决定了最终效果的上限,而你永远不知道检索到的那几段内容是不是真正够用。
这两条路都不是最优解。问题是,没有人找到一个既能让模型看到全部信息,又不会让成本爆炸的方法。
DeepSeek V4 的方案:压缩注意力,而不是压缩信息
DeepSeek V4 的核心创新是一套混合注意力架构,把两种压缩策略组合在一起用。
第一种叫 CSA(Compressed Sparse Attention)。 它的思路是:不是所有历史 token 都需要完整记住。每 4 个 token 的 KV cache 压缩成 1 个,然后再用稀疏注意力机制从压缩后的 KV 里挑选最相关的部分做注意力。换句话说,它先压缩再筛选,用两道过滤把计算量压下来。
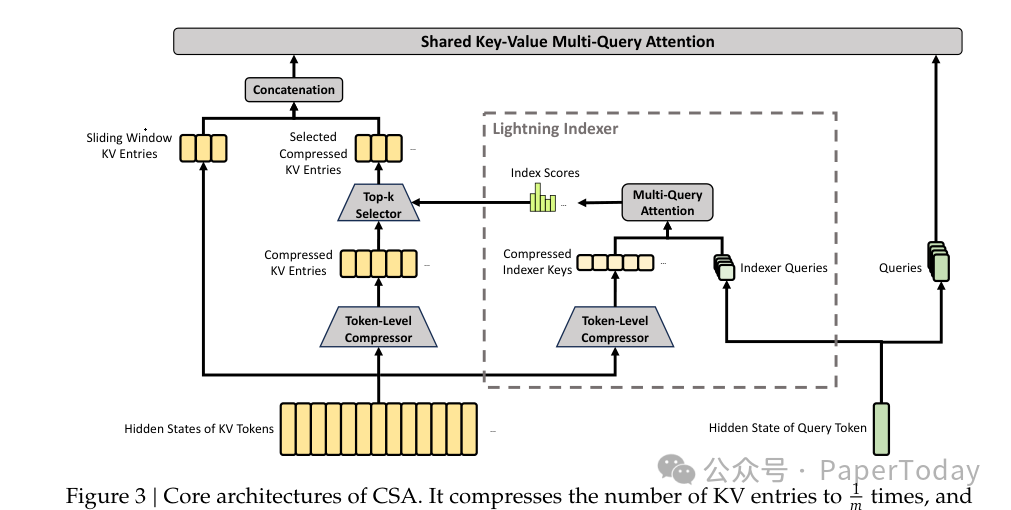
第二种叫 HCA(Heavily Compressed Attention)。 压缩更激进——每 128 个 token 的 KV cache 压成 1 个。但压缩之后不筛选,而是做全量注意力。适用于那些“粗看一眼就够了”的远距离信息。
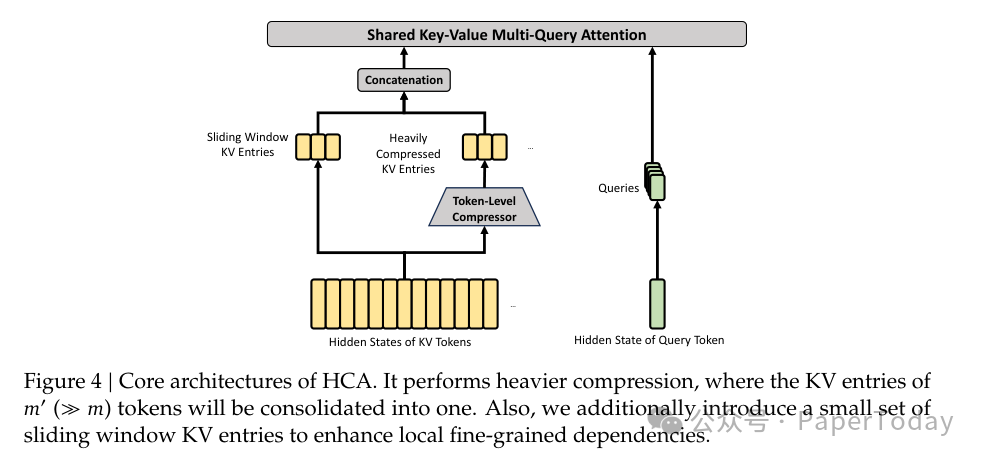
两种注意力交替使用:CSA 负责需要精细处理的层,HCA 负责可以粗略看的层。再加上一个滑动窗口分支处理局部依赖,三个分支拼在一起,就是 DeepSeek V4 的完整注意力方案。
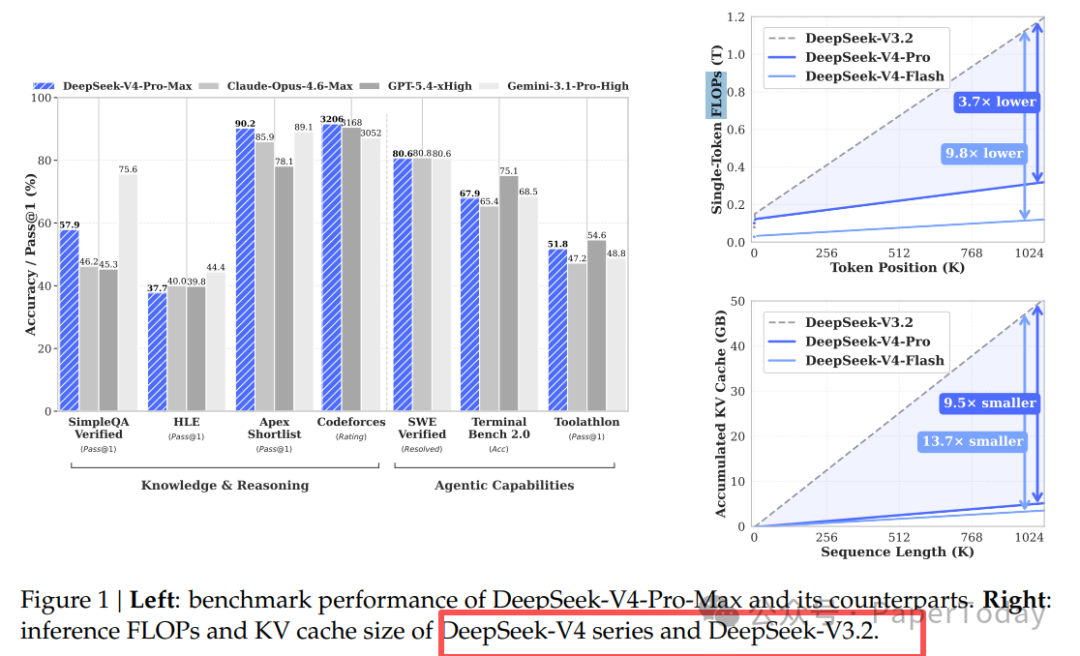
效果呢?在 100 万 token 的上下文下,DeepSeek V4-Pro 的单 token 推理 FLOPs 只有 V3.2 的 27%,KV cache 只有 10%。更小的 V4-Flash 更夸张:FLOPs 只有 10%,KV cache 只有 7%。
实验结果:开源模型第一次追平闭源
数字说明一切。
知识问答。 SimpleQA Verified 上拿到 57.9%,比所有其他开源模型高出 20 个百分点以上。但跟 Gemini 3.1 Pro 的 75.6% 比还有差距。
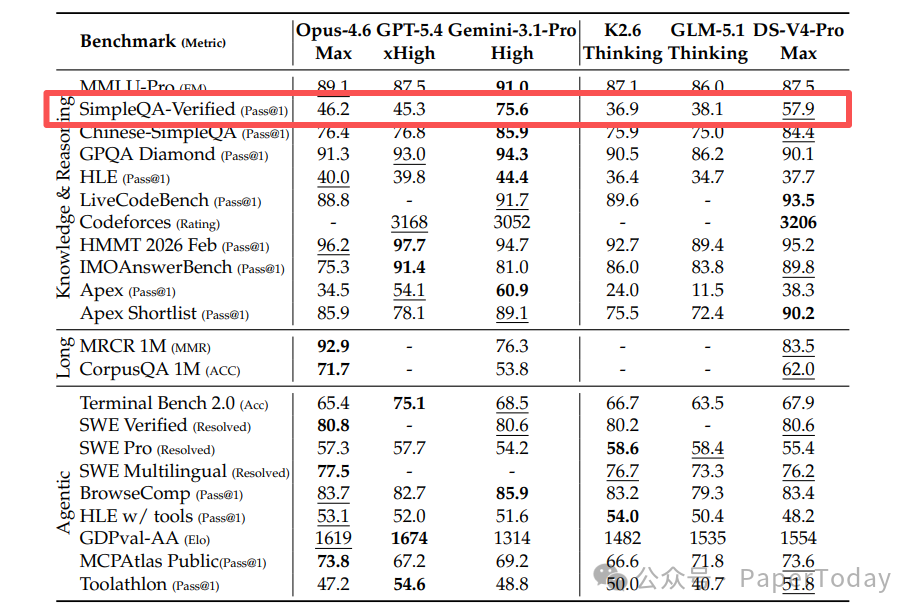
长上下文。 在 100 万 token 的 MRCR 检索任务中,V4-Pro-Max 拿到 83.5% 的 MMR,超过 Gemini 3.1 Pro 的 76.3%,但低于 Claude Opus 4.6 的 92.9%。
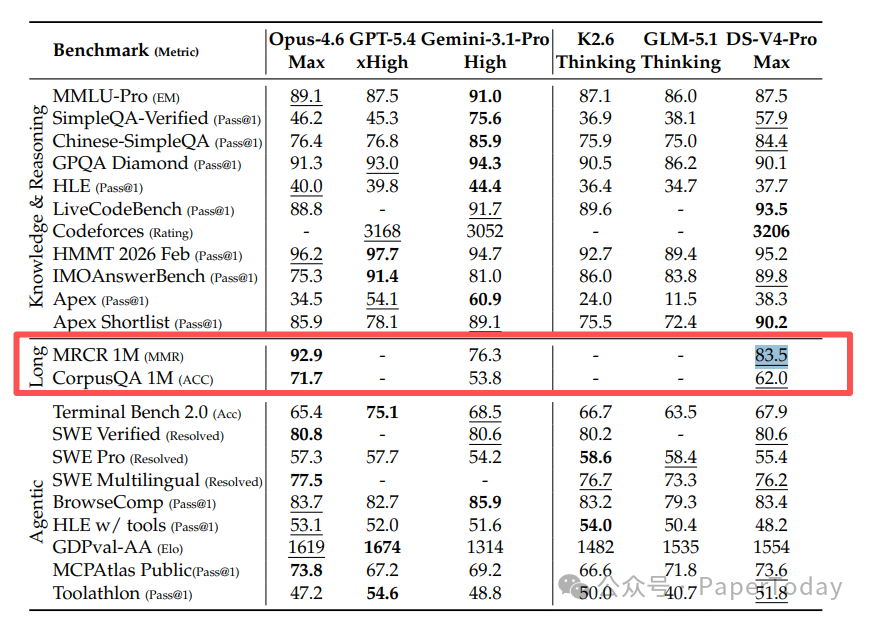
更值得注意的是 V4-Flash 的表现:总参数量只有 284B(激活 13B),比 V3.2 小得多,但在大多数基准上已经超过 V3.2-Base。这说明架构改进带来的效率提升是真实的,不只是参数换来的。
这件事对 RAG 意味着什么
回到标题的问题:RAG 还有救么?
答案是:RAG 不会消失,但它的角色会变。
当百万 token 的上下文成本降到可以日常使用,很多以前必须依赖检索才能解决的场景,可能直接把全部文档塞进上下文就够了。DeepSeek 自己的测试就显示,在搜索场景中,Agentic Search(直接让模型在长上下文中搜索)比传统 RAG 的胜率高出 61.7%。
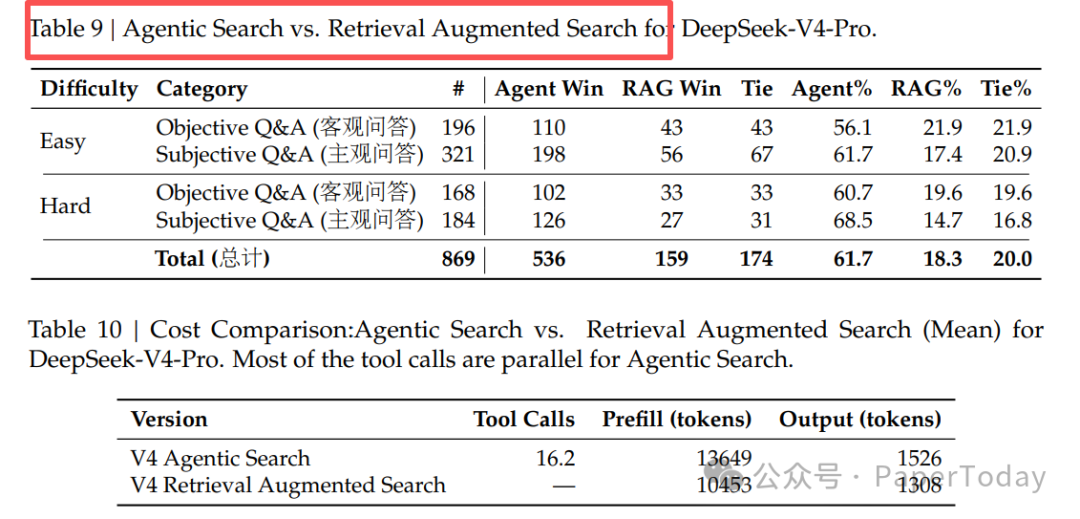
但这不意味着 RAG 完全没有用。DeepSeek V4 在“对比”和“推荐”这类需要综合多来源信息的任务上,RAG 仍然有竞争力。而且当数据量远超百万 token 时(比如整个企业知识库),检索仍然是必要的。
真正会改变的是中间地带:那些以前因为成本问题不得不切成碎片检索的内容,现在可以直接整块塞进上下文了。
对普通开发者和产品意味着什么
长文档分析从奢侈品变成标准功能。 合同审查、论文解读、财报分析这些以前需要分段处理再拼接的场景,现在可以一次性处理。
代码 Agent 变得更实用。 DeepSeek 的内部测试显示,V4-Pro-Max 在真实研发任务上的通过率达到了 67%,接近 Claude Opus 4.5 的 70%。85 名内部开发者的调查显示,52% 的人愿意把它作为主力代码模型。
多轮复杂任务成为可能。 百万 token 的上下文 + 完整保留推理历史,意味着 Agent 可以在很长的对话中保持连贯的思考链,不会像以前那样每轮都丢掉之前的推理。
DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence
https://huggingface.co/collections/deepseek-ai/deepseek-v4
 发表于 2026-4-27 01:27:27
|
查看: 187|
回复: 0
发表于 2026-4-27 01:27:27
|
查看: 187|
回复: 0
