距离DeepSeek R1发布已经过去15个月,DeepSeek V4终于在昨天问世了。各方面的进步相当显著——官方给出的说法是,内部测试成绩已经超过了Claude Sonnet 4.5,交付质量也接近非推理模式下的Opus 4.6。
从各大AI基准测试榜单到网友的实机体验,结论各有不同。平均来看,DeepSeek V4依然能坐稳开源AI的头把交椅。不过,在编程和推理能力上,它确实还够不到御三家旗舰产品的水平,这一点DeepSeek自己也承认还有差距。
那么,国产AI到底差在哪?最核心的瓶颈恐怕还是算力资源。有网友粗略估算了一下:DeepSeek V4 Pro拥有1.6万亿参数,其预训练计算量大约在 1e25 FLOPs 这个量级。
作为参照,如果OpenAI手上那10万块GB200芯片,哪怕实际利用率只有15%,完成同等计算量也只需要大约37个小时。

换句话说,DeepSeek V4过去长达15个月的努力,如果能有像OpenAI那样的算力支撑——哪怕效率再低——也只不过一天半就能搞定整个训练过程。这差距确实让人感慨。
DeepSeek具体有多少算力没有公开。但从他们公布的算法来看,应该也用上了NVIDIA的Blackwell架构显卡,同时还有华为的昇腾,但规模上显然没法跟OpenAI相比。
除了算力,DeepSeek V4这次进步最大的一块是“世界知识”。官方表示,在这方面它只比谷歌的Gemini 3.1稍逊一筹。
另外,从DeepSeek透露的动向来看,他们已经开始大批招聘数据标注人员,甚至找到了北大的文科生来做这项精细活儿。
不过也不必过于悲观。DeepSeek提到,下半年随着华为昇腾950的批量上线,V4的能力和运行速度都会提升,而且价格也已经明确会大幅下降。
在算力及世界知识层面,国产AI与美国闭源AI的差距依然摆在眼前。但AI这场竞赛不是几个月或几年就能分出胜负的,算力和知识的短板都会慢慢补上。

DeepSeek V4选在昨天正式发布,虽然和OpenAI的GPT-5.5撞了日子,但热度反倒比后者还高。然而,这次不会再有什么“DeepSeek冲击波”了。
回想一下2025年1月,DeepSeek R1刚问世时,凭借不到600万美元的训练成本就实现了全球最强的开源AI性能。那不仅在国内炸开了锅,还直接动摇了美国科技界的信心。
当时,美国AI行业坚信,凭借巨大的算力规模与市场优势,他们完全可以遥遥领先——尤其在中国被限制进口先进AI芯片之后,这种迷信更根深蒂固。但DeepSeek R1一下把这道迷思打破了。
R1发布那阵子,在美国科技圈引发了一场巨震,被称为“AI版的斯普特尼克时刻”——指苏联发射全球首颗卫星时给美国带来的震撼。当时NVIDIA股价在一周内就蒸发了高达6000亿美元。
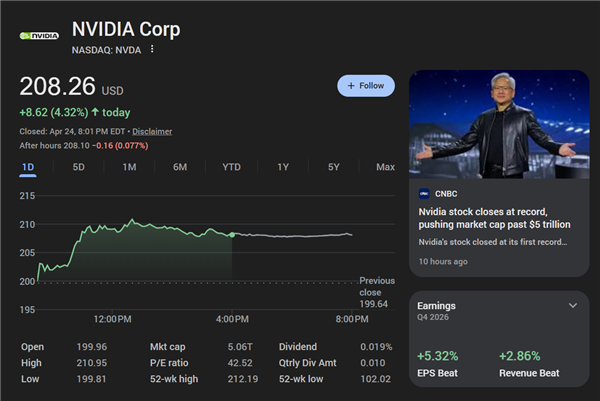
而现在,DeepSeek V4 发布后,情况完全不同了。美国科技界和股市已经“脱敏”。NVIDIA 股价不仅没有跌,近期还一路上涨,昨晚又大涨4.3%,重新站回200美元,市值也重新突破了5万亿美元。
上一次市值冲到5万亿还是去年10月份。之后便开启了长达半年的调整。
这次DeepSeek V4发布之后,美国科技界对它的讨论远不如R1那时热烈。原因也简单——过去的15个月里,美国AI大模型迭代速度太快了,御三家已经牢牢筑起了自己的护城河。尤其在AI编程方面,Anthropic公司明明一直在疯狂限制国区账号,可照样挡不住国内开发者“送钱”也要用Opus来写代码。
至于NVIDIA,从黄仁勋此前的多次表态来看,他一直很关注DeepSeek的发展。一方面赞赏它的开源精神,另一方面也格外在意DeepSeek对国产AI算力的支持程度。前不久他还放出狠话:如果DeepSeek V4选择只在华为等国产AI平台上首发,对美国人来说将会非常可怕。
但事实证明,黄仁勋的担心或许多余了。DeepSeek V4依然没有放弃对NVIDIA显卡的支持。当然,对国产AI平台的支持也在加码:首发的算力阵容里就有华为的昇腾平台,下半年昇腾950的超算集群也会批量上线,这将大幅拉低Pro大模型的使用价格。

 发表于 2026-4-27 00:30:51
|
查看: 158|
回复: 0
发表于 2026-4-27 00:30:51
|
查看: 158|
回复: 0
