字节跳动开源的 GUI Agent 模型 UI-TARS,最近在业内引起了不少关注。它解决的不仅是“看懂屏幕”,而是从零教会一个多模态大模型怎么在真实桌面、Web、移动端上自主完成复杂操作。这篇文章会拆解其核心架构,梳理出 8 大类数据格式与三阶段训练细节——这份指南,普通工程师也能照着做。
1 核心架构与数据表
1.1 训练三阶段透视
GUI 智能体的训练与普通大语言模型不同,它需要跨越视觉理解、动作映射和逻辑推理三座大山。如果直接把所有目标混在一起微调,模型往往会变成一个只会死记硬背点击坐标的残次品。因此,UI-TARS 严格采用了渐进式的三阶段训练架构:
- 持续预训练(Continual Pre-training):给基座多模态大模型灌入海量的 GUI 世界知识,让它先具备看懂界面、找到元素、理解页面变化、预测下一步动作的基础能力。
- 退火与监督微调(Annealing / SFT):抽取极高质量的子集,并引入核心的反思与纠错(Reflection)数据。这一步不再追求广度,而是追求动作质量、任务对齐和错误恢复能力。
- 直接偏好优化(DPO):基于在线运行产生的正确与错误动作对,通过强化学习思路把“正确比错误更优”的偏好压入模型,极大提升策略鲁棒性。
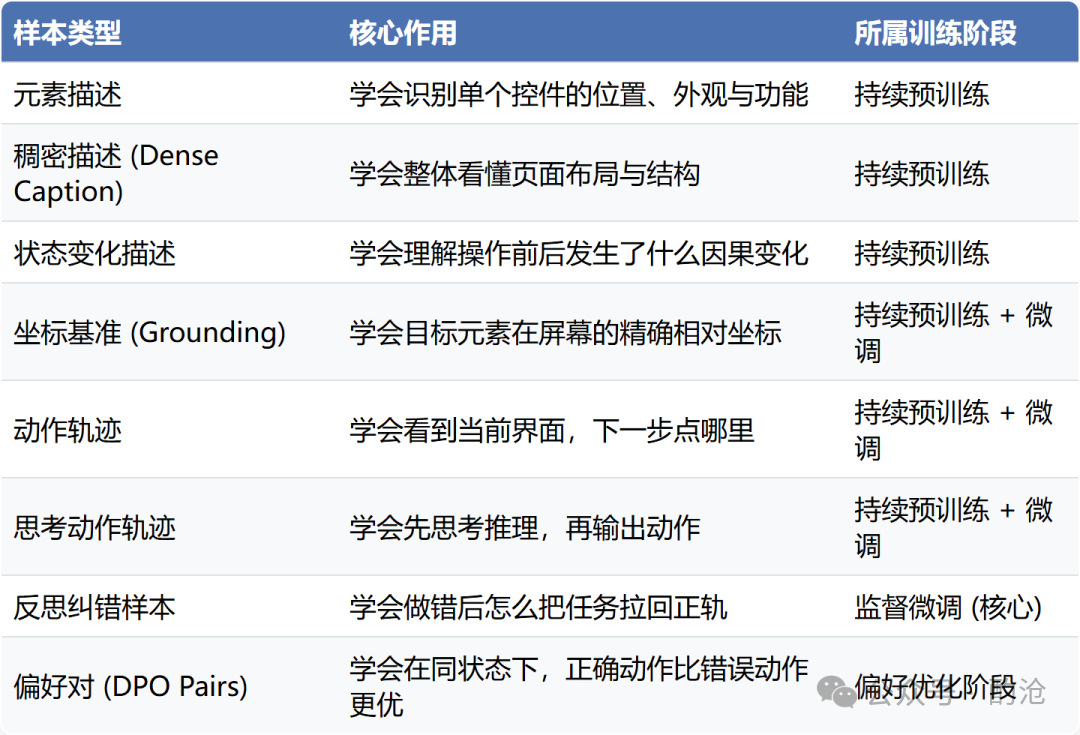
1.2 八类核心样本表
为了支撑上述三阶段,工程上需要构造 8 类核心训练样本:
2 持续预训练阶段
2.1 界面视觉感知层
✅ 元素描述任务
先大规模收集网站、App、操作系统界面的截图,并用专门解析工具抽取元数据(元素类型、深度、bounding box、文本等),再把每个元素构造成元素描述任务。元素描述覆盖四个方面:元素类型、视觉描述、位置关系、元素功能。
这类样本本质上是图像到文本的监督学习。如果模型连“这个是按钮、那个是输入框”都看不明白,后面动作学得再多也会崩溃。输入是带有 Bounding Box 提示的截图,目标输出是结构化描述,覆盖元素类型、视觉外观、位置关系和功能。
{
"task_type": "element_description",
"image": "settings_page.png",
"target_element_box": [1680, 940, 1820, 1000],
"input": {
"instruction": "描述高亮元素"
},
"output": {
"element_type": "button",
"visual_description": "蓝色圆角按钮,白色文字Save",
"position_information": "位于页面右下角,在 Cancel 按钮右侧",
"element_function": "保存当前设置"
}
}
✅ 全页稠密描述任务
元素描述是看懂一个控件,而 Dense Caption 是看懂整个页面。要求模型从整张 GUI 图像生成整个界面的高密度布局描述。这一步能极大减少模型在后续执行复杂任务时的视觉幻觉。
{
"task_type": "dense_caption",
"image": "file_manager.png",
"input": {
"instruction": "详细描述整个界面"
},
"output": "页面顶部是工具栏,左上角有返回和前进按钮。左侧是目录树,当前选中Documents。中间区域是文件列表,按名称和修改时间两列展示。右上角有搜索框,底部是状态栏。"
}
✅ 状态变化感知任务
这是多图输入 -> 文本输出的任务。它训练的不是单纯的静态视觉识别,而是因果变化感知。它教模型的不仅是看到什么,而是刚刚那一步操作改变了什么。
{
"task_type": "state_transition_caption",
"image_before": "form_before_submit.png",
"image_after": "form_after_submit.png",
"input": {
"instruction": "描述两张图之间的变化"
},
"output": "点击提交后,页面右上角出现绿色Saved successfully提示,表单内容保持不变,提交按钮变为灰色不可点击。"
}
2.2 基础动作执行层
✅ 坐标基准 Grounding
Grounding 是 GUI Agent 走向跨平台泛化的核心。模型不依赖底层 DOM 树或辅助功能树(Accessibility Tree),而是直接预测元素的归一化相对坐标。从元素框里取中心点,把目标描述 + 截图配成训练样本,让模型直接预测目标位置。
UI-TARS 定义了统一动作集合,包括:
Click(x, y)Drag(x1, y1, x2, y2)Scroll(x, y, direction)Type(content)Wait()Finished()CallUser()
{
"task_type": "grounding_text_format",
"image": "checkout_page.png",
"messages": [
{
"role": "user",
"content": "点击右上角红色的 Submit Order 按钮"
},
{
"role": "assistant",
"content": "Action: click(start_box='(0.91,0.08)')"
}
]
}
✅ 多步轨迹数据
从 MINT 和 OmniCorpus 这类图文交错预训练数据里,筛出高质量 GUI 教程。流程是:
- 用 fastText 做粗筛;
- 用 LLM 做细筛,去掉伪教程;
- 去重、去广告、去噪;
- 最后还让 LLM 改写教程文字,提高一致性和质量。
这些教程的作用,不是教模型某一个按钮坐标,而是教模型任务通常怎么走。比如一个教程写的是:打开设置 → 找到显示 → 调整字体大小 → 点击应用。那么模型学到的是一种流程知识,而不只是一个点击点位。
另外还包括:
- 他们自己的 PC 标注工具收集的人类操作轨迹;
- 多个开源 GUI / Web / Mobile 数据集,然后统一映射到同一个动作空间。统一动作空间包括 Click / Drag / Scroll / Type / Wait / Finished / CallUser,还包含桌面和移动端特有动作。
{
"messages": [
{
"role": "user",
"content": "任务:把当前网页加入书签"
},
{
"role": "assistant",
"content": "Action: click(start_box='(0.95,0.06)')"
},
{
"role": "user",
"content": "<image: step1_menu_open.png>"
},
{
"role": "assistant",
"content": "Action: click(start_box='(0.82,0.24)')"
},
{
"role": "user",
"content": "<image: step2_bookmark_dialog.png>"
},
{
"role": "assistant",
"content": "Action: click(start_box='(0.76,0.71)')"
}
]
}
✅ 思维链动作注入
原始的动作轨迹(Action Trace)只是简单的观察-动作序列,容易导致模型变成反射式点按器。为了增强 Reasoning,通过逆向推导将轨迹扩充为观察-思考-动作格式。模型在此阶段需要学习 5 类推理模式:任务拆解、长期目标一致性、里程碑识别、试错、反思纠错。
论文说原始 action trace 是观察-动作序列,没有显式 thought。为了增强 reasoning,论文把它扩成观察-thought-action形式,并用两阶段方法生成 thought:
- ActRe:已知当前正确动作,反推 thought;
- Thought Bootstrapping:不预先告诉正确动作,采样多个 thought-action 对,只保留真正导向正确动作的 thought。论文还强调 thought 同时有中英文版本。
给 thought 注入了 5 类推理模式:
- 任务拆解
- 长期目标一致性
- 里程碑识别
- 试错
- 反思纠错
{
"messages": [
{
"role": "user",
"content": "任务:把系统字体调大"
},
{
"role": "assistant",
"content": "Thought:先进入系统设置,再寻找显示或辅助功能,因为字体大小通常位于这些区域。\nAction: click(start_box='(0.03,0.96)')"
},
{
"role": "user",
"content": "<image: start_menu.png>"
},
{
"role": "assistant",
"content": "Thought:开始菜单已经打开,下一步点击设置图标进入系统设置。\nAction: click(start_box='(0.14,0.72)')"
}
]
}
2.3 预训练工程实操
✅ 数据集与模型准备
在工程实现上,基于 Qwen2-VL 等优秀多模态基座模型。准备数据时,需将上述 5 类数据的格式统一转化为多轮对话(Message)格式,所有图片以 Token 占位。动作空间需统一为预先定义的函数集,例如 click(start_box='(x,y)'), type(content='text'), hotkey(key='enter')。
✅ 损失函数与训练策略
本质上,持续预训练阶段依然采用标准的自回归语言建模损失。
- 输入:图像特征序列 + 指令 Token 序列。
- 输出:模型需要自回归地预测出
Thought: 后面的推理文本,以及 Action: 后面包含归一化坐标的动作字符串。
- 掩码(Masking):在计算 Cross-Entropy Loss 时,只对模型应该生成的答案部分(
output 或 target_output)计算损失,用户指令和图像部分的 loss_weight 置为 0。使用大规模分布式训练跑完所有全量 GUI 数据。
3 监督微调
3.1 高质量数据提纯
✅ 为什么需要退火
在经历了海量数据的持续预训练后,模型已经见多识广,但输出格式和决策逻辑可能还带有一定的噪音。
退火(Annealing)阶段本质上就是一次超高质量的监督微调(SFT)。强调它不是粗暴继续训,而是让学习更聚焦、更贴近真实 GUI 决策。包括:
- 高质量 grounding 样本
- 高质量 thought-action 轨迹
- reflection 修正样本
✅ 错误反思与补救
离线标注数据太干净,不会包含真实错误。但智能体在真实桌面操作时必定会点错、卡顿。专门做了 reflection tuning:找到模型自己在线执行时的错误步,让标注员补上修正后的 thought 和 action,甚至继续标错误已经发生之后,下一步如何补救。
{
"task_type": "reflection_sft",
"instruction": "把当前网页加入书签",
"context_before_error": [
{
"observation": "browser_page.png",
"action": "click(start_box='(0.95,0.06)')"
}
],
"error_step": {
"observation": "menu_open.png",
"wrong_action": "click(start_box='(0.98,0.02)')"
},
"corrected_step": {
"target_output": "Thought: 任务目标是书签而非关闭页面;应选择书签入口。\nAction: click(start_box='(0.82,0.24)')"
},
"recovery_step": {
"observation": "tab_closed.png",
"target_output": "Thought: 标签页被误关闭,需先恢复页面再继续任务。\nAction: hotkey(key='ctrl+shift+t')"
},
"loss_mask": ["corrected_step", "recovery_step"]
}
3.3 微调工程实操
会从 perception、grounding、action trace、reflection tuning 里挑高质量子集继续训练,并把这一阶段的模型称为 UI-TARS-SFT。所以这一步可以把它理解成:高质量 GUI 任务监督微调(SFT)。只是论文用 annealing 这个词,强调它不是粗暴继续训,而是让学习更聚焦、更贴近真实 GUI 决策。
在工程编写 DataLoader 逻辑时,对于 reflection_sft 数据,历史的 wrong_action(例如误点关闭标签页)绝对不能作为正样本去计算 Loss。
- 工程师需要在代码中动态生成 Attention Mask 和 Loss Label。
- 将
context_before_error 和 error_step 标记为上下文(Label 设置为 -100,不计算交叉熵损失)。
- 仅对
corrected_step(正确的替代方案)和 recovery_step(后果产生后的补救措施)对应的 Token 序列计算梯度。
这种训练方式让模型学会从错误上下文中推导出正确的下一步,而不是学会模仿错误本身。
4 偏好优化对齐
4.1 偏好对样本结构
SFT 阶段教会了模型标准做法是什么,但模型仍然不知道不同动作之间的优劣差距有多大。在 DPO(Direct Preference Optimization)阶段,数据不再是单一标准答案,而是在同一状态下成对出现的 Chosen(好动作) 和 Rejected(坏动作)。这些数据来源于在线自举过程中的真实错误。
{
"task_type": "preference_pair",
"instruction": "把当前网页加入书签",
"observation": "menu_open.png",
"preferred": {
"thought": "目标是把页面加入书签,应该点击书签入口而不是关闭页面。",
"action": "click(start_box='(0.82,0.24)')"
},
"rejected": {
"thought": "也许先关闭页面会触发保存选项。",
"action": "click(start_box='(0.98,0.02)')"
}
}
4.2 对齐工程实操
工程复刻此阶段,不能再使用简单的交叉熵损失,必须引入基于 Bradley-Terry 偏好模型的 DPO Loss 算法。
- 加载参考模型:将 SFT 阶段产出的最终模型作为
pi_ref(冻结参数)。
- 加载训练模型:同样初始化为 SFT 模型,作为
pi_theta(需要更新梯度的策略模型)。
- 前向传播:将图像和指令输入,分别计算
pi_ref 和 pi_theta 在 chosen 序列和 rejected 序列上的隐状态对数概率(Log Probabilities)。
- 损失计算:通过 DPO 损失公式,模型不仅被拉向 chosen 动作,同时被强烈推离 rejected 动作。超参数通常设置在 0.1 左右以控制相对KL散度的惩罚力度。这极大降低了模型在复杂 GUI 环境下崩溃卡死或死循环点击的概率。
5 自动化数据引擎
✅ 批量生成思考过程
手工标注 Thought 成本极其高昂。工程师可以使用 ActRe(Action Reasoning) 机制。对于大量仅包含 [截图, 动作] 的开源多步轨迹数据,利用一个能力较强的视觉语言模型(如 GPT-4o 或已具备初步能力的自研 VLM)。将过去的步骤序列和当前的正确动作一并输入给大模型,让大模型事后诸葛亮地反推出为什么这一步要采取这个动作。这样就能快速低成本地构造出海量的 Thought-Action 数据对。
✅ 虚拟环境集群跑测
仅靠离线数据无法支撑 SFT 的纠错阶段和 DPO 阶段。必须构建一个自动化数据飞轮。工程师需要部署数百个包含真实 OS 环境的 Docker 容器或虚拟机(VMs)。编写自动化脚本,将成千上万的任务指令发送给当前版本的模型,让模型直接控制虚拟机进行实际操作。系统全程录屏并抓取截图、操作坐标及状态流。
✅ 自动过滤与人工介入
模型在虚拟机里的试跑会产生大量翻车数据。工程处理管线分三层:
- 规则过滤:用代码自动剔除那些在同一个坐标连续无效点击超过3次的死循环数据。
- VLM 打分:用奖励模型对最终结果进行状态判定,成功的轨迹直接回流至高质量 SFT 数据集。
- 人工修正提取偏好对:将失败的轨迹交给标注员。标注员找到导致任务失败的关键分岔点,标记此时模型的输出为
rejected(错误思想与动作),然后人工演示并写出正确的逻辑,记录为 chosen。这就源源不断地产出了支撑整个高阶能力训练的 Reflection 和 DPO 数据对。
以上便是字节 UI-TARS 从数据构造到三阶段训练的完整实战路线。如果你想进一步获取相关源码、模型权重与更多技术资源,欢迎访问 云栈社区 与更多开发者一同交流进步。
 发表于 2026-4-27 00:15:32
|
查看: 208|
回复: 0
发表于 2026-4-27 00:15:32
|
查看: 208|
回复: 0
