PinchBench 是一个专门用来测试大语言模型(LLMs)作为 OpenClaw 智能体大脑时表现有多聪明的基准平台。它直接给 AI 丢过去真实世界里的复杂任务——比如写邮件、查股票、整理报告等。所有测试成绩会公开展示在 pinchbench.com 的排行榜上,方便开发者横向对比不同模型的实际干活能力。
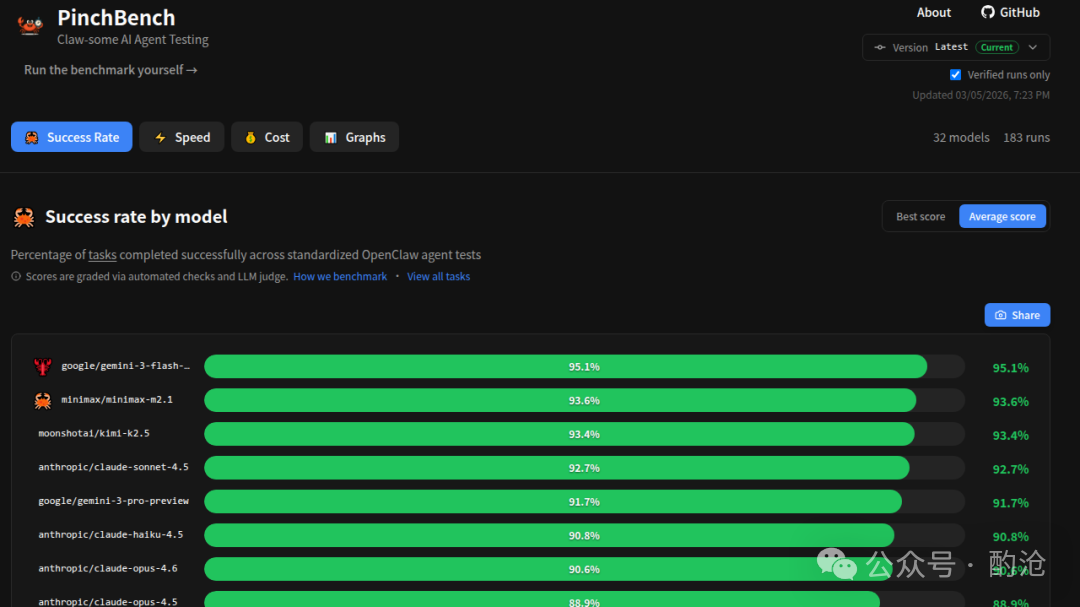
1 基准测试定位
现在很多 AI 测试往往只测单点能力(如写诗、做数学题)。PinchBench 认为,一个优秀的 AI 助手必须具备四大关键能力:
| 核心能力 |
考核重点 |
| 工具使用能力 |
能否准确调用外部工具,并传入正确的参数。 |
| 多步推理能力 |
面对复杂任务,能否将多个动作串联(如:搜索资料 → 整理数据 → 写成报告)。 |
| 应对现实混乱 |
面对人类模糊的指令和不全的信息,能否在混乱中正常工作。 |
| 实际执行结果 |
拒绝纸上谈兵,只看是否真正完成了建文件、发邮件、排日程等实体动作。 |

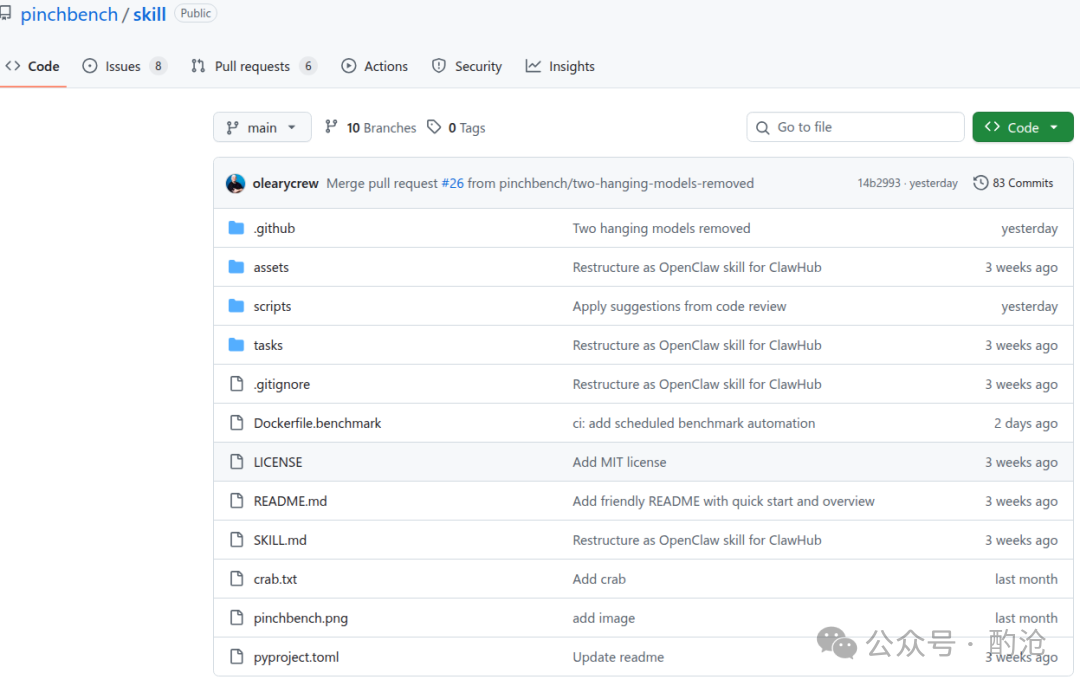
2 快速上手与任务
2.1 运行环境配置
- ✅ 环境要求
- Python:3.10 及以上版本
- 依赖管理:uv(一个极速的 Python 包管理器)
- 底层框架:一个正在运行的 OpenClaw 实例(该测试依赖的底层智能体框架)
- ✅ 运行方式
为开发者提供了极简的快速启动命令。通过命令行拉取代码后,只需运行 ./scripts/run.sh 脚本并指定要测试的模型(例如 GPT-4o),也可以指定只跑特定的任务(如日历或股票任务)。
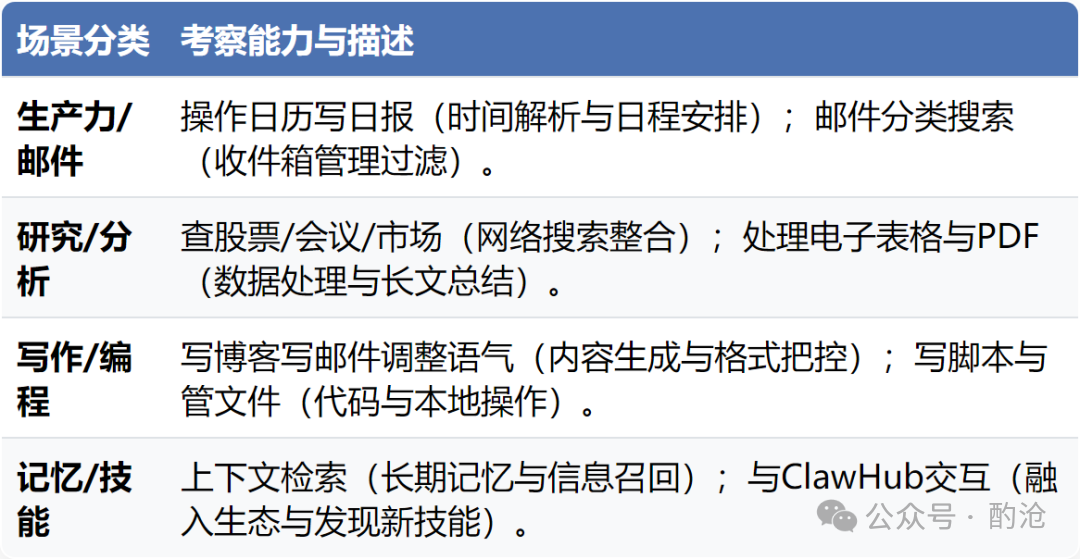
2.2 内置任务场景
PinchBench 目前内置了 23 个真实任务,涵盖 8 大日常核心场景。每个任务执行后,会通过自动化代码验证或大模型裁判 (LLM Judge) 进行客观细腻的打分。
3 进阶打榜与贡献
3.1 成绩打榜机制
平台鼓励开发者将跑出的模型成绩上传到公开排行榜,机制如下:
- 申请令牌:首次需用
--register 申请一个 API 令牌(Token)。
- 自动上传:正常运行测试时,成绩会自动上传至服务器。
- 本地测试:若仅作为本地测试,添加
--no-upload 参数即可阻止上传。
3.2 核心命令行
为高级用户提供了一系列控制指令以满足定制化测试需求:
| 参数指令 |
功能描述 |
--model / --suite |
指定要测试的大模型(如 anthropic/claude...)/ 选择测试套件(全部、特定任务 ID 等)。 |
--runs N |
同一个任务跑 N 次取平均分,减少 AI 发挥不稳定的偶然性。 |
--timeout-multiplier / --output-dir |
按倍数延长回复较慢模型的超时等待时间 / 指定测试结果报告的保存路径。 |

3.3 社区贡献规范
官方欢迎开发者编写新的测试任务,但一个好任务必须满足四个核心条件:
- 真实的:必须是真实用户确实会要求 AI 去做的事情。
- 可衡量的:必须有清晰的成功标准,方便打分。
- 可复现的:同样的任务每次跑,评分标准和结果应该是一致的。
- 有挑战性的:测试智能体的综合统筹和实操能力,而非自带百科知识库。
4 代码库结构解析
4.1 核心目录一览
整个 PinchBench 的代码库结构非常清晰,主要分为三个核心目录:
scripts/:包含评测运行的核心逻辑。tasks/:包含所有测试任务的 Markdown 格式定义。assets/:包含任务所需的一些测试资产(文本、电子表格、PDF 等)。
4.2 核心脚本解析
scripts/ 目录下的核心逻辑分散在以下几个关键脚本中:
| 脚本文件 |
核心职责 |
关键功能点 |
benchmark.py |
主入口点 |
解析参数,加载任务,创建代理与工作区,执行评分,聚合上传结果。 |
lib_agent.py |
代理执行逻辑 |
与 OpenClaw CLI 底层交互,准备工作区,执行任务,解析日志与费用。 |
lib_grading.py |
评分引擎 |
执行自动化代码评分,或构造提示词调用 LLM 裁判评分,或混合评分。 |
lib_tasks/upload |
解析与上传 |
解析 Markdown 任务文件(Yaml、代码、量表);处理排行榜后端的注册与上传。 |

4.3 任务定义结构
tasks/ 目录下定义了 23 个不同场景的任务。每个任务都是一个 Markdown 文件,通过 lib_tasks.py 解析,包含以下结构:
- YAML Frontmatter:包含元数据配置(ID、分类、评分类型、超时、依赖文件)。
- Prompt:发送给 Agent 的具体指令。
- Expected Behavior:期望的执行路径。
- Grading Criteria:给分点的清单。
- Automated Checks:自动评分所需的 Python 代码。
- LLM Judge Rubric:供裁判 LLM 阅读的评分标准。
5 智能体执行引擎
5.1 生命周期管理
lib_agent.py 扮演 PinchBench 和底层 OpenClaw 框架之间的桥梁。它负责严格的生命周期管理:
ensure_agent_exists:确保 OpenClaw 中存在待测智能体,若绑定的工作目录错误会无情删除并重建。cleanup_agent_sessions:每次跑新任务前,清理该智能体历史的会话日志(Transcript),防止上下文污染。prepare_task_workspace:像监考老师发卷一样,将任务所需的初始文件(如 CSV、脚本)从 assets/ 拷贝到隔离的工作目录中。
5.2 核心任务执行
✅ execute_openclaw_task
它通过 Python 的 subprocess 调用命令行 openclaw agent --message "任务提示词" 来驱动 AI。它设置了严格的超时时间(Timeout)。如果 AI 未在规定时间内完工,进程将被强制中断,并被标记为 timed_out。
5.3 日志与账单
_load_transcript:因 OpenClaw 异步写入日志,此函数内置了巧妙的重试机制(尝试 6 次),从本地捞取 AI 运行的 JSONL 对话记录。_extract_usage_from_transcript:遍历对话记录,汇总 Input/Output Token 数量,计算出本次任务花费的金额(Cost USD)。
6 自动化评分系统
6.1 评分路由分发
任务执行完毕后,lib_grading.py 负责评判 AI 表现(0.0 到 1.0 分)。核心函数 grade_task 会根据任务配置进行路由分发,选择三种模式之一:automated(代码硬核校验)、llm_judge(大模型裁判)、或 hybrid(两者结合,按权重计算总分)。
6.2 代码自动评分
✅ 执行逻辑 _grade_automated 会从任务配置的 ## Automated Checks 区块提取纯 Python 代码,并使用 exec() 在沙盒中动态运行。
✅ 核心特点 本质上就是为每个任务写单元测试(Unit Test)。这段代码会检查 Agent 工作区的文件状态(如文件是否生成、JSON 是否合法、代码能否跑通)。极其客观、非黑即白,但没有泛化能力(来 100 个任务需写 100 个测试脚本)。
代码示例:自动化测试脚本提取(略,详见任务文件中的 ## Automated Checks 部分)
6.3 大模型裁判
当任务是开放式的(如写委婉的拒绝信),PinchBench 会聘请高智商 AI 裁判(默认 Claude 3.5 Opus)审阅工作过程。_grade_llm_judge 包含 5 个核心步骤:
Step 1: 整理案卷与浓缩日志 调用 _summarize_transcript() 压缩冗长日志,仅保留关键动作(如 Tool: bash(…) -> Result: file.txt),防止裁判被干扰或超出上下文长度。
Step 2: 宣读判罚标准 从 Markdown 文件提取专属评分表 llm_judge_rubric;若无,则拼接常规的 grading_criteria。
Step 3: 构造法官提示词 调用 _build_judge_prompt() 拼接出带有严格系统指令的巨大 Prompt:包含考题、期望行为、浓缩日志、评分细则,并强制要求输出指定格式的 JSON。
Step 4: 召唤裁判并执行 调用 run_openclaw_prompt() 启动专用的裁判智能体,喂入 Prompt,并设置独立超时时间(默认 180 秒)等待判卷。
Step 5: 暴力提取与数据清洗 实施极强的防御性编程:
- 第一层
_parse_judge_response 尝试寻抓 ```json 代码块或成对大括号强行解析。
- 如果裁判写了小作文,动用正则匹配 Fallback 提取分数。
- 最后通过
_normalize_judge_response 将各种奇葩 JSON 键名统一抹平为标准格式 {"scores": {}, "total": 0.9, "notes": "..."}。
代码示例:专属评分表提取

总结:从环境搭建到跑分提交,再到理解底层代码架构和评分机制,PinchBench 为开发者提供了一套完整的 LLM 智能体测试方案。如果你正在对比不同模型在 人工智能 领域的实际落地能力,或者希望用 软件测试 的思路来量化 AI 表现,这个框架值得一试。整个项目基于 Python 构建,可扩展性很强,社区也欢迎贡献新任务。更多资源和讨论可以访问 云栈社区。
 发表于 2026-4-27 00:13:20
|
查看: 259|
回复: 0
发表于 2026-4-27 00:13:20
|
查看: 259|
回复: 0
