本文根据 OPPO 大数据架构负责人 David 在 Data for AI Meetup(深圳站)的技术演讲整理而成。在本次分享中,David 系统介绍了 OPPO 在多模态数据湖建设中的技术选型与落地经验。面对手机影像、多模态推荐搜索以及端侧 AI Agent 等场景带来的数据爆发式增长,OPPO 团队通过引入 Gravitino 统一元数据管理,并自研云原生分布式缓存 Curvine,成功构建了统一的存储、管理与查询架构。文章将围绕 OPPO 的多模态应用场景、数据湖架构设计、Gravitino 的核心能力、Curvine 的加速实践以及未来展望四个部分展开,详细解读这套架构如何解决数据孤岛、元数据混乱和 IO 性能瓶颈等实际问题。
主要内容包括以下几个部分:
- OPPO 的多模态应用场景
- OPPO 的多模态数据湖架构
- Gravitino 统一全模态元数据
- Curvine 加速多模态数据读写
- 展望:Curvine 作为多模态数据湖的必备中间件
01 OPPO 的多模态应用场景
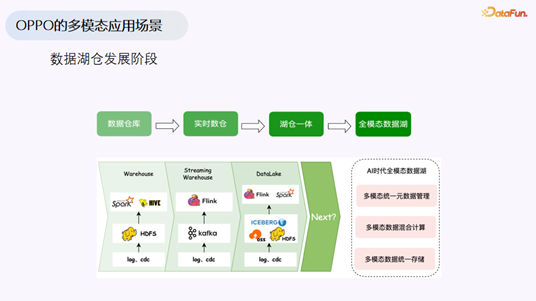
数据湖仓的发展阶段
David 首先回顾了数据湖仓的发展历程。他提到,刚加入 OPPO 时,公司的大数据基础设施基本处于离线 Hive 加少量 Spark 的第一阶段。经过五六年的演进,当前 OPPO 正处在数据湖与全模态数据湖的交界处,并持续向前推进。今天分享的技术和架构,虽然部分仍属于探索性项目,但已在一些业务中落地验证。
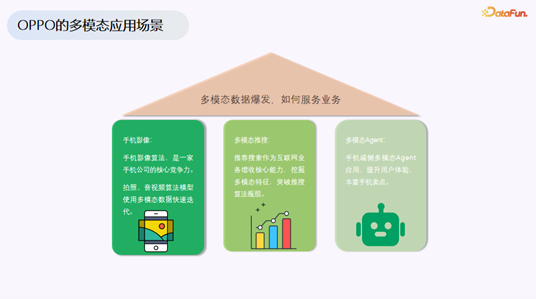
三大核心应用场景
OPPO 的多模态数据湖主要服务于三类核心业务:
手机影像:作为一家手机公司,影像算法是核心竞争力。用户购买手机时,拍照效果往往是首要考量。为了不断优化算法和模型,需要海量的图片数据支持迭代。
多模态推理:推荐搜索是互联网业务增收的核心动力。过去十年,传统推荐算法已接近瓶颈,充分挖掘多模态数据的特征与价值,成为突破瓶颈的关键方向。
多模态 Agent:这是 OPPO 内部的一些探索性项目,例如餐饮推荐、日常管理类等手机端侧的多模态智能体应用。
这三类场景共同推动了多模态数据的爆发式增长,也对底层数据架构提出了全新的要求。
02 OPPO 的多模态数据湖架构
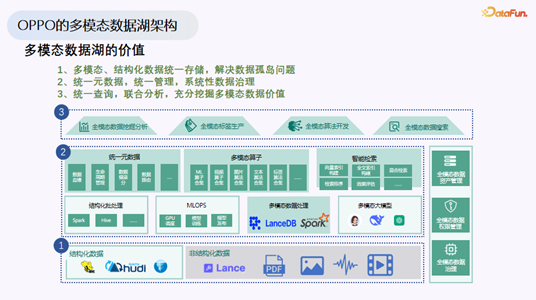
多模态数据湖的核心价值
David 认为,构建多模态数据湖需要解决三个核心问题:
- 解决数据孤岛:多模态数据分散在不同存储介质和系统中,远不像数仓数据那样集中。OPPO 上云后,数据统一存放在阿里云 OSS 上,但在此之前,算法工程师各自管理自己的目录,数据非常混乱。
- 统一元数据:在建设多模态数据湖的第一天,就必须考虑元数据统一,实现统一存储、统一管理、统一治理,避免未来产生大量历史债务。
- 统一查询与联合分析:构建统一的查询平台,方便结合数仓数据与多模态数据进行联合分析,充分挖掘多模态数据的价值。
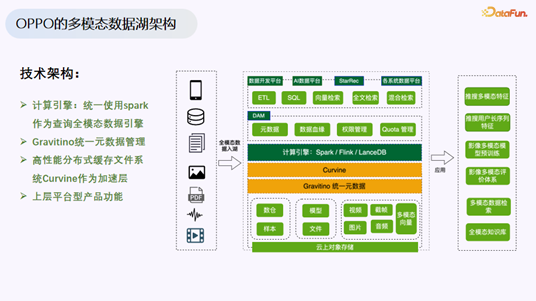
技术架构选型
OPPO 的多模态数据湖技术架构分为四层:
- 计算引擎:统一使用 Spark 作为全模态数据查询引擎。技术团队延续了原有的 Spark 经验,选择基于 Lance 开源项目进行二次开发。
- 统一元数据管理:采用 Gravitino 作为行业标准的统一元数据方案。
- 加速层:自研高性能分布式缓存文件系统 Curvine,解决云上 IO 性能瓶颈。
- 平台产品层:复用已有的数据地图、权限管理、数据治理等平台能力,实现多模态数据资产的统一管理。
03 Gravitino 统一全模态元数据
为什么选择 Gravitino
David 回忆,两年前团队就开始与 Gravitino 社区沟通。当时最大的痛点是算法工程师滥用数据——线上接近 PB 级的数据中,有数百 PB 是算法数据,但这些数据散落在各个脚本里,不知道是谁的、谁在管理、谁在使用。团队需要一个方案来收口:从某一天起,所有新增目录如果没有通过 Gravitino 访问,一律拒绝。通过控制增量、转换存量的方式,逐步将所有元数据收归统一平台。
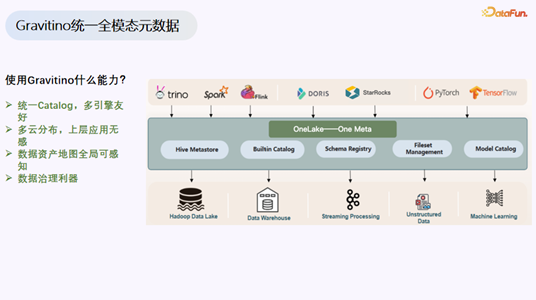
Gravitino 的核心能力
Gravitino 为 OPPO 提供了三项关键能力:
- 统一 Catalog:支持多引擎友好,实现了 Hive 表和 Lance 表在同一套目录下的统一管理。
- 多云分布:OPPO 采用混合云模式(自建机房 + 阿里云),Gravitino 让数据分布对业务无感,方便表和数据迁移。
- 数据资产全局可感知:现在可以归因到每一个目录的归属人、每日账单、上下游依赖关系,数据治理变得清晰可控。
能力成果
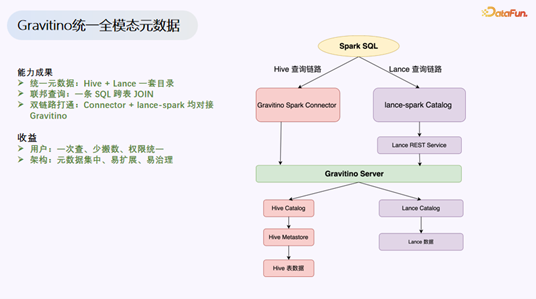
基于 Gravitino,OPPO 实现了以下成果:
- 统一元数据:一套目录同时管理 Hive 和 Lance 表。
- 联邦查询:一条 SQL 即可跨 Hive 表和 Lance 表进行 JOIN 查询,通过自研的二开实现 Connector 和 lance-spark 的双链路对接。
- 收益明显:用户实现了“一次查、少搬数、权限统一”;架构层面实现了元数据集中、易扩展、易治理。
04 Curvine 加速多模态数据读写
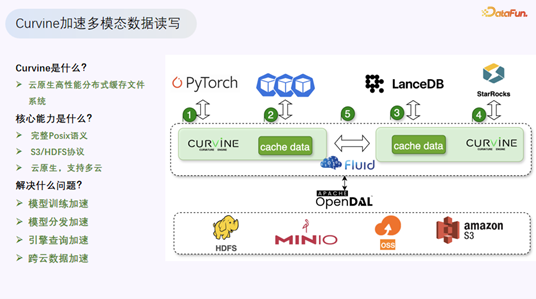
Curvine 是什么?
Curvine 是 OPPO 自研并已开源的云原生高性能分布式缓存文件系统。它提供两种模式:缓存模式(所有读写与 OSS 对象存储保持一致)和 FS 模式(元数据由 Curvine 管理,支持完整 POSIX 语义,可将对象存储上的数据当作本地盘访问)。Curvine 同时支持 S3 和 HDFS 协议,并原生支持 Kubernetes 的 CSI 模式。
解决了什么问题?
OPPO 将大数据架构整体迁移到阿里云后,遇到了几个典型的云上性能问题:
- 对象存储带宽配额:云厂商对 OSS 的读带宽有默认配额,常规场景够用,但大数据场景下很容易成为瓶颈,需要不断购买额外带宽。
- 专线带宽压力:混合云模式下,云上云下通过专线连接。大数据任务一次读取就可能打爆专线带宽,影响其他业务。团队通过分析发现,有些表每天被下游上百个任务重复读取,非常适合用缓存来降低带宽压力。
- 计算节点磁盘利用率低:每个计算节点配置了 2.5TB 的云盘,主要用于 Reduce 阶段的 Shuffle 数据,利用率常在 20% 以下。团队希望充分利用这些闲置资源。
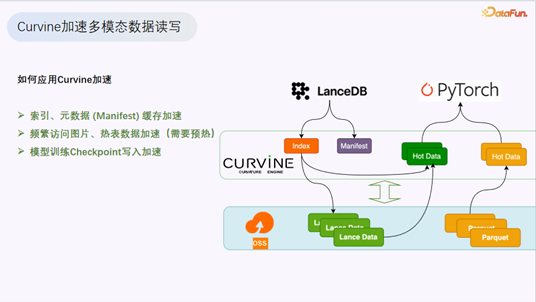
如何应用 Curvine 加速
在实际落地中,Curvine 主要应用于以下场景:
- 索引与元数据缓存:将 LanceDB 的索引和 Manifest 元数据放入缓存层,支持预热模式,满足高性能访问需求。
- 频繁访问数据加速:对热表数据进行预热,将重复读取的数据从 OSS 加载到计算节点的本地缓存盘。
- Checkpoint 写入加速:模型训练过程中需要频繁写入 Checkpoint,Curvine 提供了高性能写入能力。
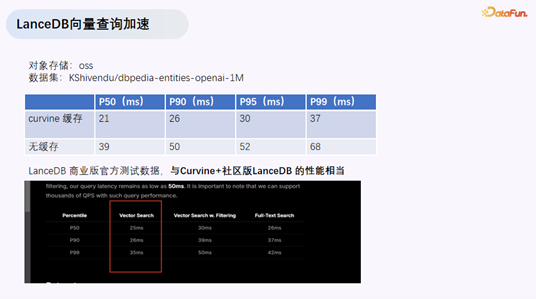
- LanceDB 向量查询加速:在 OPPO 的多模态数据湖中,LanceDB 的向量查询通过 Curvine 获得了与商业版相当的性能。
性能对比
David 展示了测试结果:使用 LanceDB 官方测试数据集(dbpedia-entities-openai-1M)和测试案例,对比直接存储在 OSS 上和使用 Curvine + 社区版 LanceDB 的性能。最终结果表明,Curvine 加速后的社区版 LanceDB 查询性能几乎与 LanceDB 商业版相当。商业版的核心优势之一正是内置的分布式缓存,而 Curvine 以开源方式实现了类似的能力。
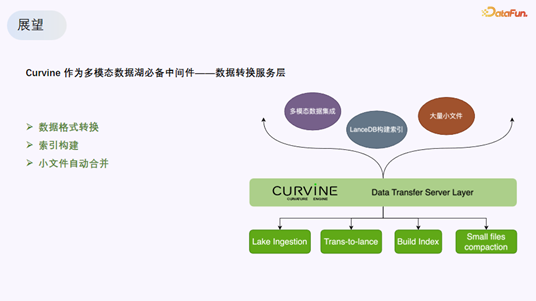
05 展望:Curvine 作为多模态数据湖的必备中间件
David 表示,Curvine 作为一个常驻服务,已经具备任务调度处理机制,目前主要处理数据加载和大文件操作。未来计划扩展为数据转换服务层,实现以下功能:
- 数据格式转换:数据写入时自动转换为 Lance 格式。
- 索引构建:接收索引构建任务,自动生成数据索引。
- 小文件自动合并:解决大数据和 LanceDB 多模态数据湖服务中常见的小文件问题。
他最后提到,虽然 OPPO 的探索与云厂商的商业化产品方向一致,但作为公司内部的技术实践,Curvine 的开源社区(https://github.com/curvineio/curvine)欢迎更多行业伙伴共同参与。

OPPO 通过引入 Gravitino 和自研 Curvine,在构建多模态数据湖以支撑人工智能业务的实践中,有效解决了元数据治理与云上IO性能两大核心挑战。这套架构的分享为面临类似问题的企业提供了宝贵的技术选型与落地参考。更多前沿技术实践与深度讨论,欢迎访问 云栈社区 进行交流。
 发表于 2026-4-20 06:53:09
|
查看: 246|
回复: 0
发表于 2026-4-20 06:53:09
|
查看: 246|
回复: 0
