DeepSeek 的识图模式大范围开放,已与「快速模式」「专家模式」并列为一级入口。
上传图片就能识别、理解、推理,不再是那个只能认字的 OCR 了。
V4 发布之初,人们高呼价格屠夫,但明显的短板也摆在眼前:纯文本模型,看不了图。
所以对 Kimi K2.6、Qwen 3.6 这些已经具备多模态能力的选手,冲击还不算致命。你可以安慰自己,DeepSeek 再便宜,至少它看不了图。
现在这个理由不存在了。

我首先抛出一个最关心的问题:DeepSeek API 支持图片理解吗?
答案是支持,但实际上还没到位。我去 AI 编程工具 Trae 里看了一下,这里还是纯文本推理,并未匹配图片理解能力。
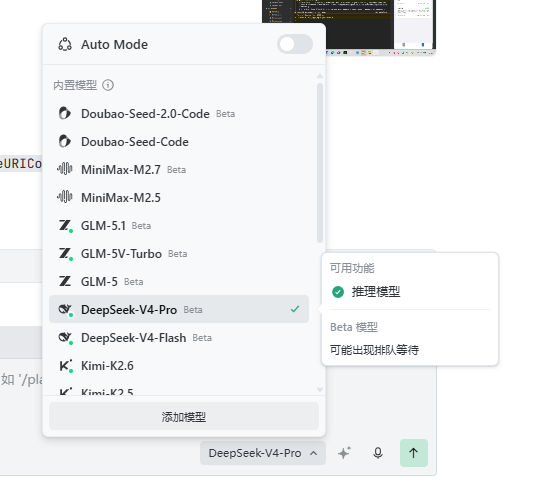
随手截取了一个代码调试的界面,直接丢给 DeepSeek 的识图模式,看看实际表现如何。
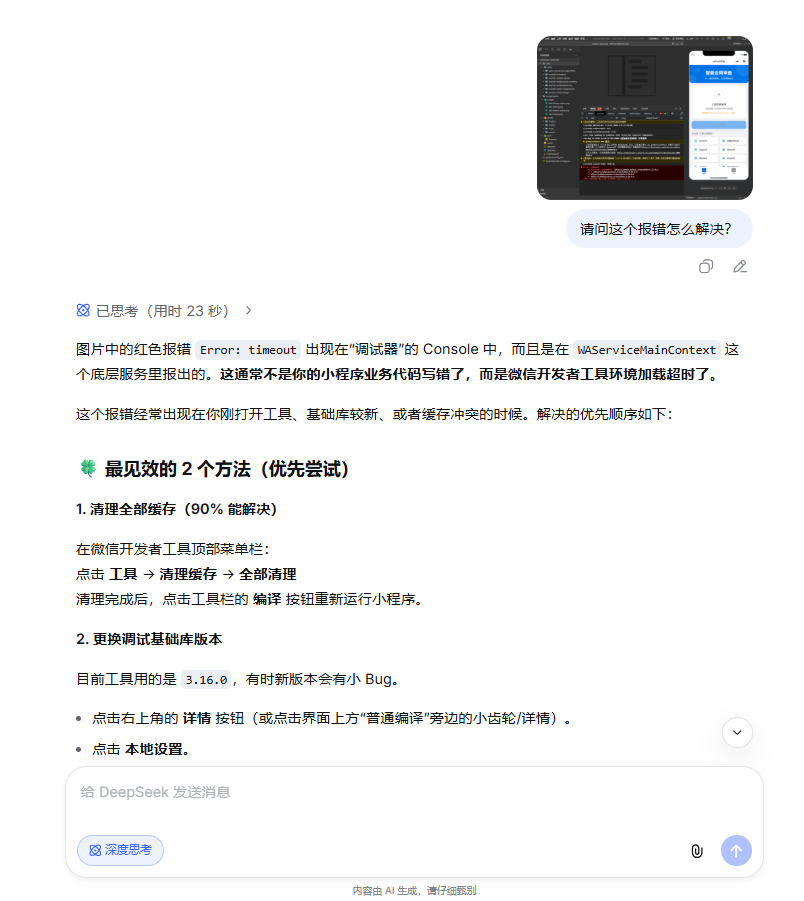
答案是对的,说明能力已经有了,就等全面到位。
先说技术,这次的识图并不是简单外挂一个视觉模块。
DeepSeek 发了一篇论文叫《Thinking with Visual Primitives》,以视觉原语思考。
核心创新在于,将点坐标和边界框直接嵌入推理链条,模型一边推理一边「指点」,像人用手指点着数硬币一样。
这解决了传统多模态模型最大的痛点——指代鸿沟。AI 能看见图,但用自然语言描述「左边那个大的红色物体」太过模糊,复杂场景下一描述就飘,一飘就错。
DeepSeek 的做法是让模型在推理时直接输出视觉坐标,比如「找到一只熊[452,23,804,411],正在爬树」,精准定位,不靠猜。
更狠的是效率。一张 756×756 的图片,DeepSeek 仅消耗 81 个视觉条目,压缩比高达 7056 倍。同等尺寸下,Claude Sonnet 4.6 要 870 个 token,GPT-5.4 要 1100 个,这可以说是架构级的差异。
V4 发布的时候,直接冲击的是国内纯文本大模型同行,比如 MiniMax、智谱的 GLM 系列等。
这次加上图片理解能力,会进一步冲击 Kimi K2.6、Qwen 3.6 等多模态大模型。
即使多模态能力还没完全追上,差距也在快速缩小。DeepSeek 的杀手锏是价格,当能力差距不大但价格差很多的时候,大部分用户会用脚投票。
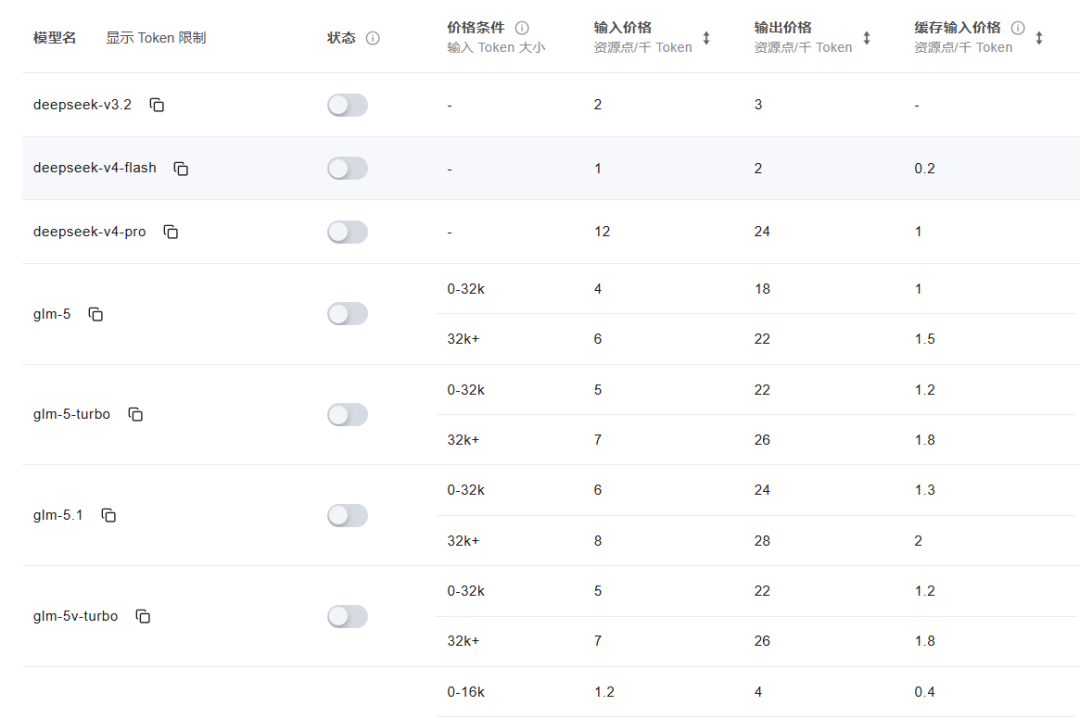
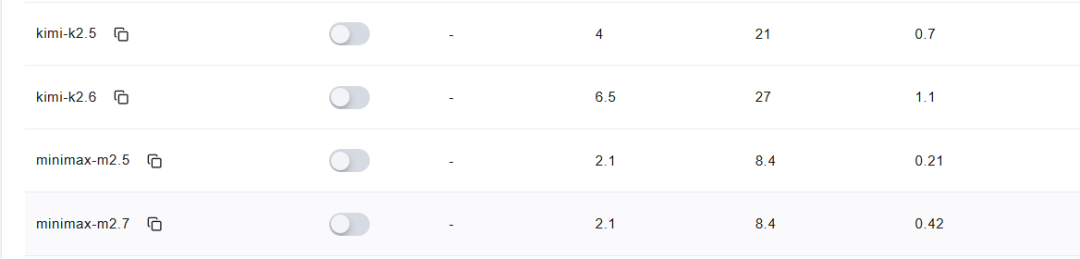
Token 便宜加上能看图,在 coding 这个变现最快的赛道上,非常值得期待。
总结一下,V4 补强了性能,识图模式填平了视觉短板,而传闻 6 月发布的 V4.1 将进一步补全 API 与企业工具链。
这样的迭代节奏,真不给同行留活路。 |  发表于 2026-5-13 19:48:06
|
查看: 118|
回复: 0
发表于 2026-5-13 19:48:06
|
查看: 118|
回复: 0
