把一个网页截图丢给模型,让它复刻成可运行的页面。前几分钟往往很唬人:配色像了,卡片有了,按钮也摆出来了。再多点两下就露馅——导航跳错,图片素材没找全,移动端布局挤成一团,原网页里那个小小的筛选按钮被它当成装饰。
这类翻车很恼人,因为它看起来离成功只差一点。可在真实 Agent 任务里,这一点就是大坑。模型一开始看错屏幕,后面写代码、调工具、改页面,全都沿着错误方向越跑越远。
GLM-5V-Turbo 这篇报告打的就是这个点。我对它的兴趣不在“又一个多模态模型发榜”,而在它把问题问得更接近真实工作:多模态模型能不能从看图回答,走到看着屏幕连续干活?
会看图的模型,离会干活还差一截
过去很多 VLM demo 的评判方式很单纯:给一张图,问里面有什么;给一张表,问某个数字;给一张截图,让模型描述界面。这个阶段当然重要,可它更像入场券。到了 Agent 场景,模型要做的是一串动作:观察屏幕,决定下一步,调用工具,拿到反馈,再观察,再修正。
网页复刻是个很好的例子。模型要先理解页面结构,知道哪些是导航,哪些是商品卡,哪些图片必须重新找;它还得点进页面,截取素材,写 HTML,检查交互。如果第一眼把一个下拉筛选看成普通文本,后面生成的页面就会少一个关键功能。我觉得这就是多模态 Agent 最容易被低估的地方:错误不大,却会一路传染。
论文里有一句判断很重要:感知能力会持续影响更高层的推理和执行。放到 GUI 任务里,这句话很直白——按钮位置看错,下一步动作就错;表格区域切歪,搜索关键词就错;截图里的层级没看明白,代码结构就跟着乱。会看图只是开局,会在屏幕上少犯错才是硬门槛。
GLM-5V的关键动作,是把视觉放进工作流
GLM-5V-Turbo 没有把视觉能力当成语言模型外面接的一根线。它做的是四层一起推:视觉底座、训练方式、强化学习任务、工具和框架接入。这个组合看起来杂,我读下来反而觉得这是比较现实的路线。Agent 能力本来就不是单个模块能解决的。
第一层是 CogViT。可以把它理解成 GLM-5V-Turbo 的眼睛,负责把物体、细节、空间关系看清楚。报告里说它做了两阶段训练:一段偏视觉表征,一段偏图文对齐。前者让模型更会抓局部和纹理,后者让图像内容能和文本指令对上。
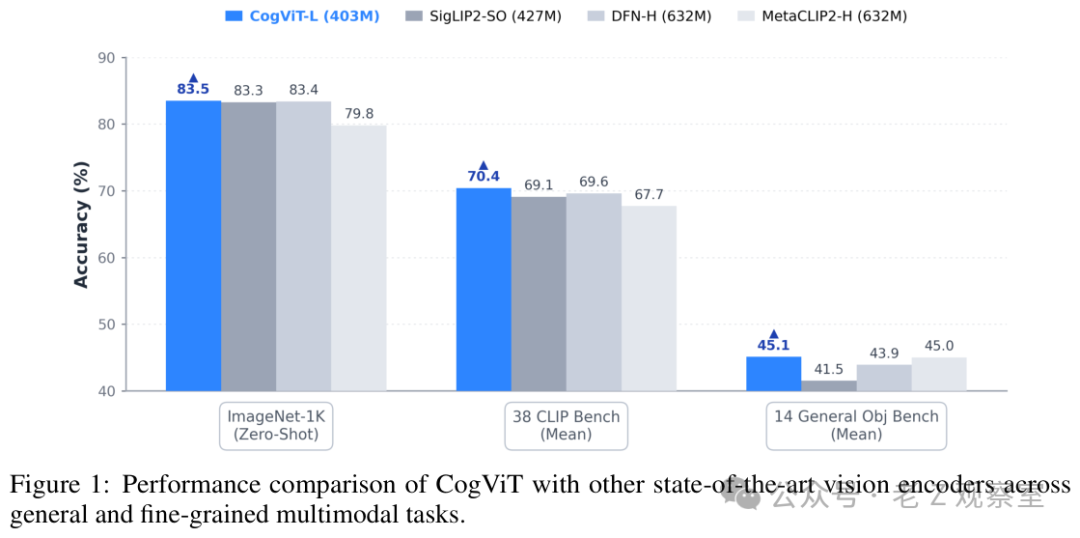
这张图值得细看 CogViT 的角色:它不是只服务看图问答,而是给后面的 GUI、空间理解、网页复刻、视觉搜索打底。我第一眼看这部分没觉得新鲜,很多模型报告都会讲视觉编码器;看到后面的 Agent 任务时才反应过来,前面的眼睛没打牢,后面的手就会乱动。
第二层是 MMTP。这个名字听着硬,直觉很简单:模型想在多模态输入下保留高效预测能力,又不想让视觉信息在大规模并行训练里变成通信灾难。报告比较了几种把视觉 token 送进预测头的方式,最终选择用统一的 image 占位符保留位置感,而不是直接搬运完整视觉 embedding。
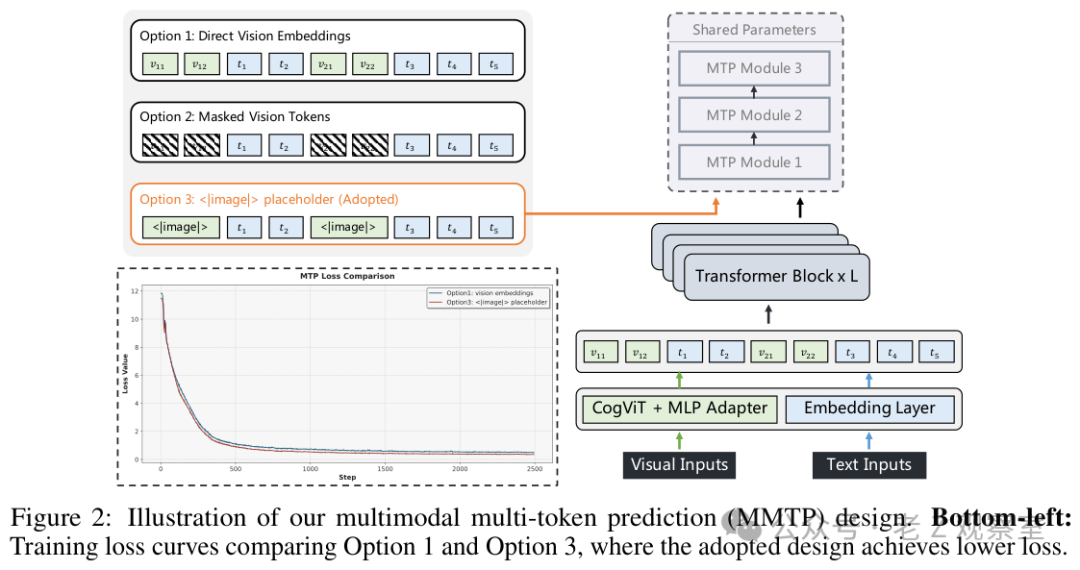
我觉得这里最有工程味。直接传视觉 embedding 看起来更完整,可系统成本高,优化也不一定稳;用占位符听起来有点笨,却能让大规模训练更好维护。很多好系统就是这样,不追求每个局部都最优,先让整条训练和推理链路跑得稳。
第三层是超过 30 类任务的联合 RL。这里的数字比单个榜单更有信息量:RefCOCO 平均提升 4.8%,PointBench 提升 3.2%,MVBench 提升 5.6%,SUNRGBD 提升 7.7%,OCRBench 提升 4.2%,CharXiv 提升 7.7%,OSWorld 提升 4.9%,MMSearch 提升 3.5%。这些任务横跨 grounding、pointing、视频、OCR、图表、GUI 和搜索。我的判断是,如果这些增益能稳定复现,它说明模型学到的不是某个题库套路,而是一批可迁移的观察和行动习惯。
第四层是工具体系。报告把识别、网页搜索、图片搜索、网页读取、裁剪、画框、视频追踪、网页生成、PPT 生成、深度研究等工具放进同一套表里。

这张表别只当工具清单看。它真正说明的是:GLM-5V-Turbo 面向的任务形态已经变了。模型不只是回答“图里有什么”,还要决定该裁哪一块图、该搜哪个线索、该读哪个网页、该把哪些素材放进生成结果。视觉能力在这里变成了可调用动作。
我还会把它放到客服后台里想一遍。用户传来一张发票截图,模型要圈出抬头、查订单、补一封邮件,再回到系统里填表。单步都不难,难的是别在第二步把第一步看错的地方继续放大。
榜单只是前菜,截图改网页才是正题
报告里的评测覆盖面很宽。GLM-5V-Turbo 在 ImageMining 拿到 30.7,BrowseComp-VL 是 51.9,MMSearch 是 72.9,SimpleVQA 是 78.2;GUI 任务里 AndroidWorld 是 75.7,OSWorld 是 62.3;多模态编码的 Design2Code 达到 94.8。更值得注意的是,文本编码能力没有明显被视觉训练拖下去,在 CC-Backend、CC-Frontend、CC-RepoExploration 上还保持了不错的分数。
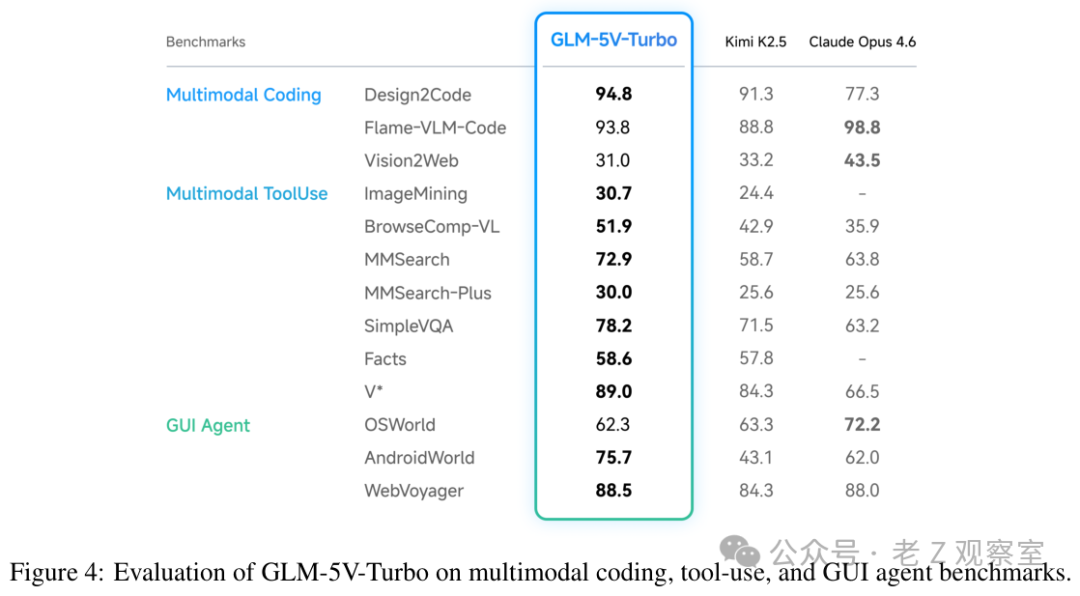
我更看重这张图背后的覆盖面。单个 VQA 分数高,不能证明模型能当 Agent;单个 coding 分数高,也不能证明它会看屏幕。GLM-5V-Turbo 把 UI-to-code、视觉搜索、GUI 操作、工具使用和文本编码放在一起考,至少方向对了:真实任务不会只考一门课。
更有画面的是 demo。论文展示了 URL-based GUI exploration:模型拿到目标网站 URL 后,要通过 GUI 探索页面,收集必要素材,再复刻成 HTML 代码。这个场景比“看图写代码”难,因为它要求模型一边看,一边找,一边生成,还要保持视觉一致性和功能完整度。

这里我有个很强的反应:这类 demo 的价值不在于页面做得多漂亮,而在于它把 Agent 的任务结构暴露出来了。模型要处理的不是一张静态截图,而是一个会变化的网页环境。点错、漏看、素材找错,都会变成后面代码里的 bug。
再具体一点,复刻电商页面时,模型不能只把商品卡片排出来。它要知道深色模式下商品图会不会糊成一片,结算页的地址自动补全是否该出现,运输费用是不是要跟选择联动。写报告时也一样,股票分析不是把几段新闻拼在一起,而是要把价格走势、分析师态度、公司基本面和后续行动放到同一个版面里。这些细碎要求对人来说像常识,对模型来说就是一串需要不断看屏幕、查证据、改输出的动作。我觉得这比单轮看图问答更接近我们真正会付费使用的 Agent。
还有几个案例也很典型。PRD-to-App 要根据产品需求文档生成网站;PDF-to-PPT 要从论文里抽结构、配图、组织幻灯片;Stock Analyst 要聚合多源信息,输出带技术分析和行动方案的报告;视觉搜索案例里,模型要从图片线索出发,裁剪、搜索、对照,再回答复杂问题。这些场景放在一起看,会发现 GLM-5V-Turbo 想证明的不是“我能识别这张图”,而是“我能把图当成任务的一部分来用”。
我更关心的问题:能力到底属于模型还是系统
这篇报告最克制的地方,是它没有把多模态 Agent 说成已经解决。剩下的坑很硬。
我反而愿意相信这种克制。一个模型报告如果只展示漂亮页面和领先分数,很容易让人误以为产品马上能无缝接管工作。GLM-5V-Turbo 至少把几个麻烦摊开了:策略怎么长出来,视觉记忆怎么保留,工具框架怎么影响结果。这些问题不性感,却决定真实系统能不能稳定跑一整天。对团队来说,真实难点会落在评测、工具和日常运维细节里面。
一个坑是策略探索。Agent 训练仍然依赖人工构造或强过滤的冷启动轨迹,这能让模型起步,但也会限制它探索新打法。模型可能越来越会走熟路,却不一定会自己发明更好的任务拆解方式。我对这一点很在意,因为很多 Agent 的上限不在单步能力,而在它会不会换一种组织任务的方法。
另一个坑是长程多模态记忆。文本历史可以压缩成摘要,屏幕和视频没这么好压。一个网页早期截图里的按钮位置、一个视频中间出现过的物体、一个表格的布局关系,后面可能又会变得关键。系统为了省上下文把早期视觉观察丢掉,短期看省钱,长任务里可能会让验证失真。
我最存疑的是归因问题。GLM-5V-Turbo 的强案例和评测,很大一部分依赖工具、skills、Claude Code、OpenClaw、AutoClaw 这类外部框架。那外部开发者只拿模型 API,没有同样的工具协议、验证器和任务编排,能力会掉多少?这不是否定模型价值,反而是多模态 Agent 落地时必须算清的一笔账。
所以我会把 GLM-5V-Turbo 看成一个信号:多模态模型的竞争,正在从“谁更会描述图片”转向“谁更能看着屏幕把任务做完”。截图改网页只是一个入口。真正难的是,让模型在长流程里少看错、少乱点、少把早期错误带到终点。在技术社区里,这类围绕视觉 Agent、多模态落地的探讨会越来越多,或许你也能在 云栈社区 发现更多同行的实践与思考。
 发表于 2026-5-3 19:34:16
|
查看: 100|
回复: 0
发表于 2026-5-3 19:34:16
|
查看: 100|
回复: 0
