家里如果有台移动机器人,最尴尬的指令大概不是“去厨房”,而是“把沙发旁边那个黑色背包找出来”。厨房是几何问题,房间坐标、墙、门、通道都能帮它走过去。黑色背包是另一种问题:它得知道“背包”这个词对应画面里的哪个东西,还得知道“沙发旁边”在三维空间里是哪块区域。
很多 SLAM 系统擅长前半段——定位、建图、避障都不在话下。但地图一旦变成纯几何坐标表,语言就很难接上去。我看到 RADIO-ViPE 这篇论文时,第一反应不是“又一个语义 SLAM”,而是它选了一个更现实的输入条件:只给一段未标定的单目 RGB 视频,不给深度传感器,不给相机内参,不给预设位姿,还要在线做开放词汇三维 grounding。
这就接近真实设备会遇到的脏活了。
地图会不会听懂人话,决定机器人像不像真能用
机器人在实验室里跑 SLAM,最容易被忽略的一点是:地图建出来之后,谁来用这张地图?导航模块关心墙和障碍物,任务规划关心“杯子在哪”、“椅子旁边有没有空地”、“这块区域能不能放箱子”。几何地图能回答“哪里有东西”,却很难回答“这东西叫什么、能不能被一句自然语言点中”。
旧路线各自都很强,但放到同一个房间里就开始露缝。传统几何 SLAM 定位稳,语义弱;开放词汇三维方法能听懂很多词,却常常要离线处理,还依赖深度、位姿或静态场景;ViPE 这类单目视频几何系统把未标定视频往前推了一大步,但它本身不负责开放词汇语义。更麻烦的是,真实客厅不是静物展厅——人会走过镜头,椅子会被踢歪,桌上的盒子可能换位置。

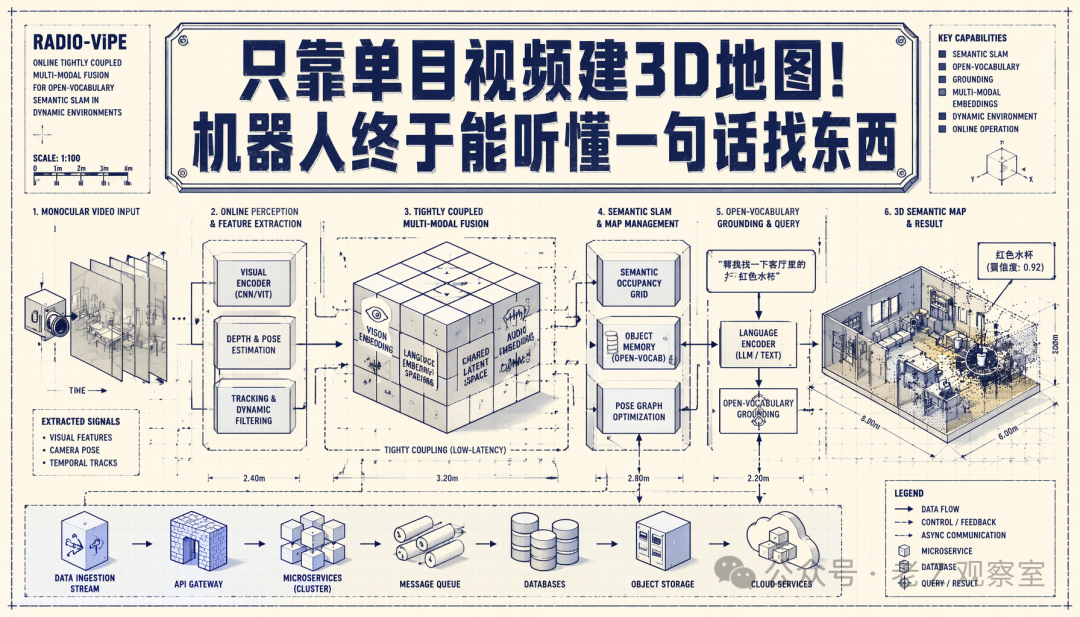
图 1 里最该看的不是模型名字,而是输入和输出的距离:左边是一段普通单目视频,右边要变成可用自然语言访问的三维地图。这个跨度很大。论文 Table I 也把问题列得很直:在线、开放词汇、几何 grounding、里程计、地图、动态处理、免标定——这些能力以前很少同时凑齐。
我的判断是,RADIO-ViPE 值得写,恰好因为它没把问题切得太干净。它没有假设相机已经标好,也没有假设场景安静不动,更没有把语义理解放到建图结束以后才处理。真实部署里,麻烦往往从地图还没建完时就开始了。
再换一个场景:AR 眼镜跟着人走进会议室,用户说“把投影幕旁边那块空墙标出来”。这句话里有物体、方位、可用区域,还要求系统知道自己刚刚看过哪里。只靠二维检测框会丢掉空间关系,只靠三维点云又听不懂“空墙”这种开放表达。这个缝隙很小,但它正好卡住很多看似聪明的空间智能 demo。
语义提前进场,SLAM 才不只是事后贴标签
很多语义地图方案给人的感觉像贴纸:几何系统先把房间搭起来,视觉语言模型再给点云或区域贴上“椅子”“桌子”“墙面”的标签。这个思路好理解,也容易做 demo。但我觉得它太晚了。建图过程中遇到纹理弱的墙面、重复的柜门、视角变化很大的同一张桌子,系统需要的不只是像素级颜色证据,还需要更高层的“这两块区域可能是同一个东西”。
RADIO-ViPE 的关键动作,是让 RADIO/RADSeg 产生的 dense multi-modal embedding 提前进入 SLAM。这里的 embedding 可以简单理解成每个位置的一张语义身份证:它不只描述颜色和纹理,还带着和语言空间对齐的视觉含义。系统再把这些特征压缩到 256 维,避免内存爆掉。这个压缩我挺喜欢,因为它承认了一个工程事实:再漂亮的语义特征,如果塞不进实时系统,就只能留在离线论文里。
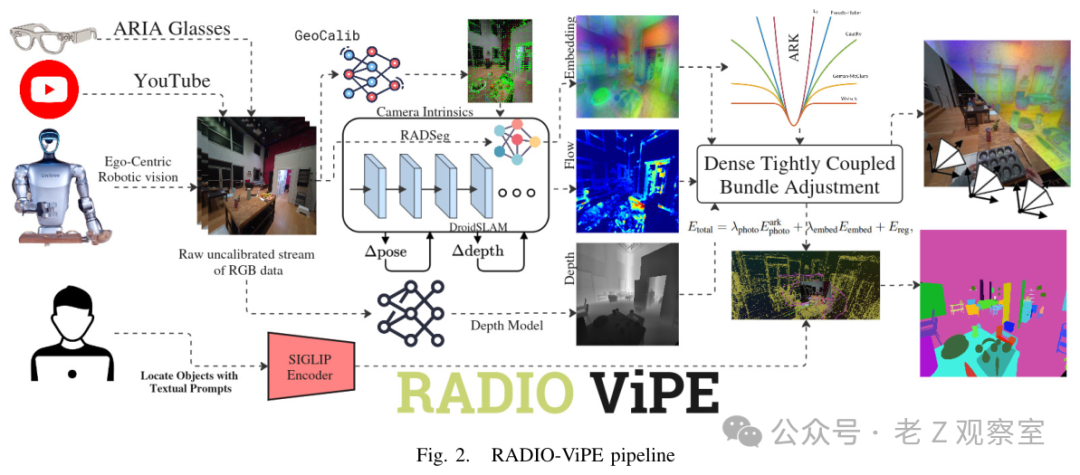
图 2 展示的是整条 pipeline。视频进来以后,系统选关键帧,用 GeoCalib 帮相机内参起步,再估计单目深度。RADSeg/RADIO 特征被提出来以后,不只留给最后的文本查询,还会参与跨帧对应、优化和关键帧连接。换句话说,它把“这里看起来像什么”和“这里在三维空间哪里”放到同一张工单里处理。
一个细节很有意思:semantic flow。普通光流在纹理少的地方会犯糊涂,比如白墙、光滑桌面、重复花纹的柜子。RADIO-ViPE 会把几何光流和语义相似性融合,让跨帧对应多一条证据。还有 embedding-based co-visibility,系统会用全局语义描述子去找非邻近关键帧,如果两帧看到语义相近的区域,就给 factor graph 加连接。我的反应是,这比单纯“加个 VLM”扎实得多,因为它真的改变了建图时的信息流。
开放词汇查询放在后面:系统把三维点的 RADIO 特征映射到 SigLIP 空间,再和文本查询匹配。用户说“椅子”“桌边区域”“可能挡路的家具”,地图里就能找到对应区域。这里当然还谈不上完美理解,但它至少把语言接口接到了三维结构上。
这一步的意义在仓库机器人里会更明显。货架编号会变,临时堆放区也会变,工人一句“去蓝色周转箱后面那排空位”,系统得把词、物体和空间关系同时对齐。对于这类涉及 计算机视觉 与复杂环境交互的任务,单纯的几何定位显然已经不够用了。
真正难的是客厅里有人走动、家具会变位置
如果只在静态房间里测试,很多 SLAM 系统看起来都还不错。问题一旦换成真实客厅,麻烦会立刻变具体:孩子从镜头前跑过去,扫地机器人推了一下椅子,客人把箱子从门口挪到墙边。几何优化最怕这类东西,因为它们昨天还在那里,今天换了地方;上一帧能当参照,下一帧就成了误导。
RADIO-ViPE 没有粗暴地把动态区域全部丢掉。这个选择我认同。人当然该降权,但被移动过的家具不能简单消失,墙和地板又应该保留强约束。论文把区域大致分成三类:稳定表面、被人挪动的物体、正在运动的人或物。系统用多个关键帧之间的语义一致性来估计稳定程度,再让不同区域在优化里产生不同影响。
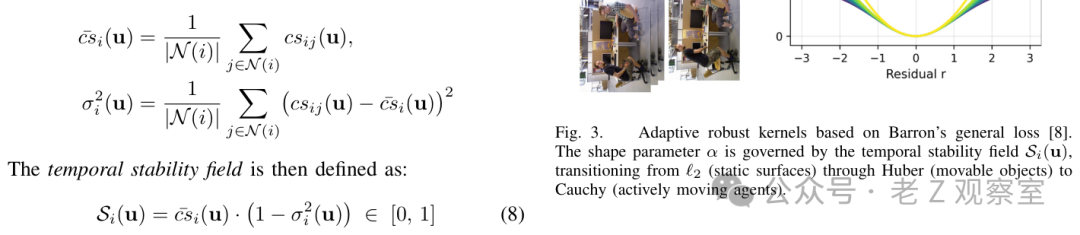
图 3 看起来像一个技术细节,但我觉得它接近整篇论文最有部署味的部分。稳定区域继续强力约束相机位姿;可移动物体的影响被放软;正在运动的人被压得更低。这样做的好处是,系统不需要提前知道“人”“椅子”“箱子”的固定类别,也不完全依赖人工指定动态 mask。它看的是跨时间是否稳定。
这里也有我的存疑点。短视频里证据不够时,稳定性判断可能会摇摆;两个外观相似的椅子被换了位置,语义上仍然很像,系统会不会误判?论文主结果说明方向有效,但我还想看到更多失败案例,尤其是第一视角长视频里那种半遮挡、重复家具、频繁挪动物体的情况。
数字不错,但我还不敢把它想成端侧产品
实验最有说服力的是动态 TUM-RGBD。普通 RADIO-ViPE 的平均 ATE 是 1.90 厘米,加上 adaptive robust kernel 后到 1.63 厘米。拿 ViPE 的 2.17 厘米作参照,这个差距不是摆设。我的理解是,语义 embedding 和动态降权确实帮系统少信了一些坏约束,尤其在有人走动或物体扰动的序列里。

Replica 的开放词汇三维语义结果也值得看。RADIO-ViPE 在不拿真值深度、位姿和相机标定的条件下,仍然能排进 top 3。更关键的是,它和使用真值几何信息的 RADIO-ViPEGT 相比,在不含背景的设置里只少一到两个百分点。这个结果让我有点意外。通常免标定、免深度、在线这些限制叠在一起,语义质量很容易被打穿;这里至少说明,几何和语义的互相补位没有白做。

PCA 消融比主表更像工程论文该看的东西。特征压到 256 维,mIoU 损失小于一个百分点,接近完整维度。这个数字不花哨,但很实用。语义地图如果每一帧都背着大特征跑,系统很快会被显存和延迟拖死。压缩后还能保住大部分效果,才有继续谈在线的资格。我更愿意把这看成一个信号:这条路线已经开始认真计算部署账,而不是只追求离线分数。
不过我还不敢把它想成随时能塞进家用机器人或 AR 眼镜的产品。论文实验用到 RTX 4090,速度大约 8 到 10 FPS。研究系统里这已经不错,低功耗设备上就是另一回事。RADSeg、单目深度、光流、滑动窗口优化一起跑,工程压力不会小。还有一个论文自己也提到的边界:带背景的 Replica 设置里,墙、地板这类结构类别表现更差。偏偏机器人导航很依赖这些大结构。
所以我对 RADIO-ViPE 的评价会克制一点:它不是把语义 SLAM 一步做到终点,但它把一个关键方向讲清了。未来的机器人地图不能只是坐标和障碍物列表,它要能被语言访问;更要在有人走动、家具改变、相机没标定的情况下,尽量保持自己不乱。回到开头那个背包场景,真正好用的机器人不该只知道客厅长什么样,还要听得懂那句“沙发旁边”。
在这个意义上,云栈社区 上关于智能感知与空间计算的讨论也指向同一个趋势:让机器理解空间中的语义,远比让它们跑出厘米级精度更难,也更有价值。
 发表于 2026-5-3 19:31:01
|
查看: 79|
回复: 0
发表于 2026-5-3 19:31:01
|
查看: 79|
回复: 0
