近期,小红书联合多伦多大学等高校的研究人员发布了《SWE-Bench Mobile》论文,首次提出了一个专门用于评估大语言模型智能体处理真实生产级移动端应用开发任务能力的基准——SWE-Bench Mobile。
相比之前那些过于简化的需求场景,这篇论文的结论显然更具说服力。最关键的是,它用真实数据给当前狂热的 AI 叙事泼了一盆冷水。
论文明确指出,现有的编程基准测试大多聚焦于孤立的算法题,或是像 SWE-Bench 那样关注 GitHub 上的 Bug 修复。但真实工业级的移动端开发远比这复杂:开发者必须同时处理产品需求文档和 Figma 设计稿,在庞大的代码库中精准定位修改点,并确保代码能通过严苛的编译与兼容性考验。为此,研究团队从小红书自身的生产流水线中提取了 50 个代表性任务,构建了这个极具挑战性的测试集。
数据集到底有多“真实”?
整个基准测试围绕一个约 5GB 大小的 iOS 生产代码库展开,采用 Swift 与 Objective-C 混编。数据集的构成充分模拟了日常开发场景:
- 50 个真实任务:直接源自实际产品需求。
- 449 个人工验证的测试用例:平均每个任务 9.1 个测试点,用于严格评估功能正确性。
- 多模态支持:70% 的任务附带 Figma 设计链接,92% 附带参考图片,平均需求文档长度达到 450 字。
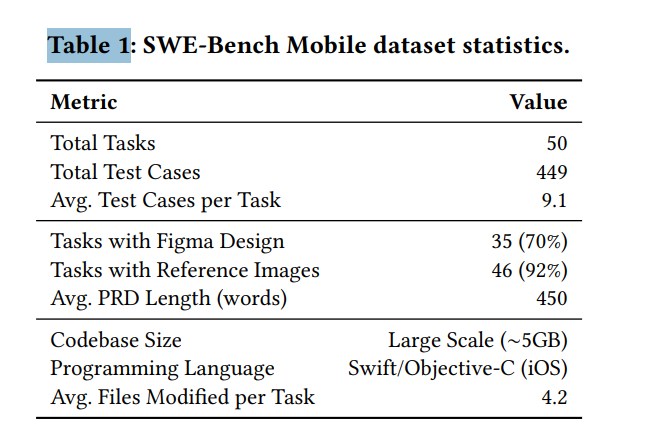
下图揭示了数据集的更多细节。每个任务的平均修改文件数高达 4.2 个,远超以往的基准测试。任务类型也被清晰地划分为 UI 组件、数据管理、手势交互等不同类别,难度则从简单跨越到复杂。
具体到执行层面,这个基准的规则很直接:智能体接收包含需求文档、设计稿和参考图的输入,然后需要输出一个统一的 diff 补丁。评估将围绕两个核心指标展开:任务成功率(所有测试通过才算成功)和测试通过率。
论文评估了 22 种不同的“智能体-模型”配置,覆盖了四个主流框架:商业智能体 Cursor、Codex、Claude Code, 以及开源智能体 OpenCode。
核心发现:12% 的成功率意味着什么?
结论或许会让不少技术乐观主义者感到意外——当前 AI 在生产级软件工程中的表现存在巨大局限性。
- 成功率极低:即便是表现最好的配置,任务成功率也仅为 12% 。大多数任务以“实现不完整”收场,虽然 28% 的最高测试通过率说明部分代码能局部正确生成,但远不足以交付完整功能。
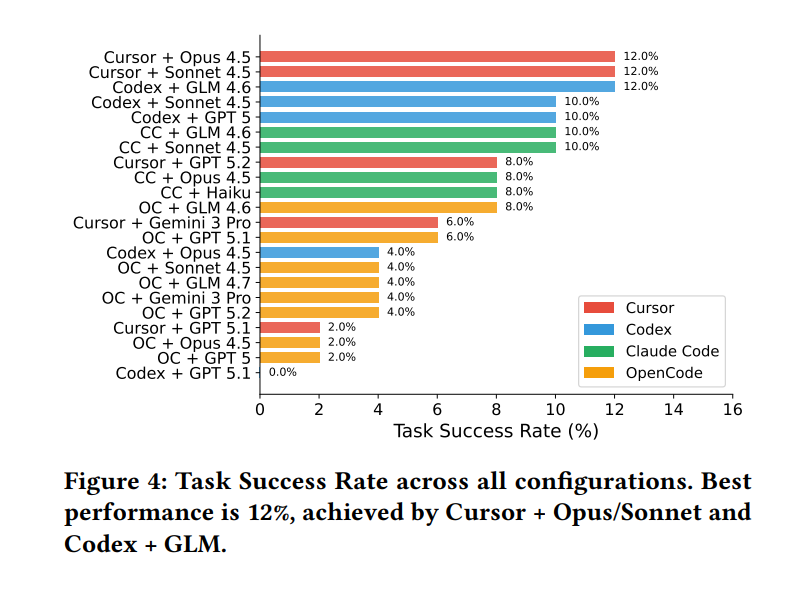
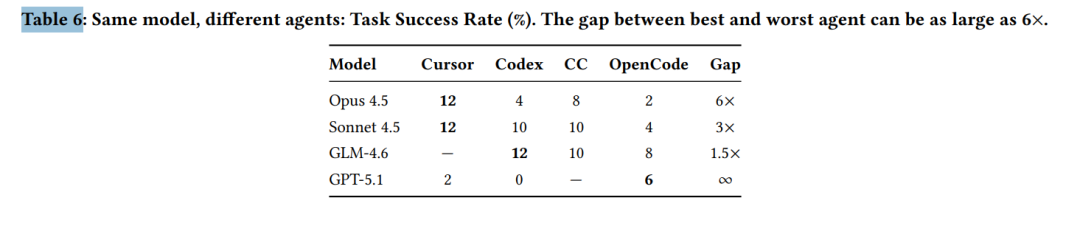
- “智能体架构”的重要性不亚于模型本身:同样的底层模型,在 Cursor 框架下的成功率可达 12%,但在 OpenCode 下却骤降至 2%。如下图所示,差距可达 6 倍之多。这说明智能体的工具调用、上下文管理等设计,与模型能力同等重要。
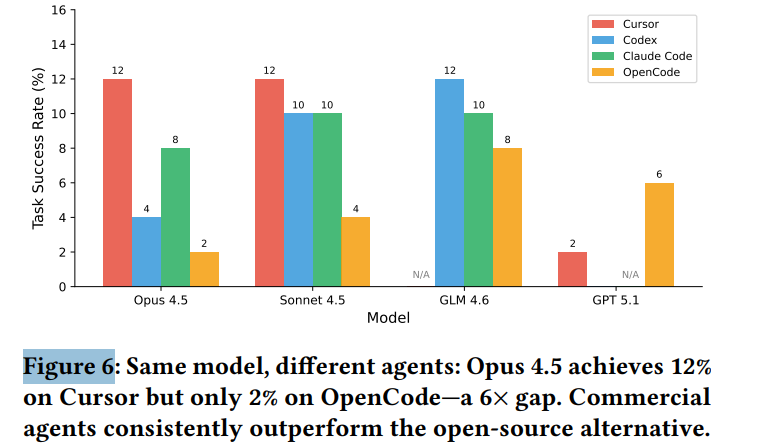
- 复杂度陷阱:当任务仅涉及 1-2 个文件时,成功率为 18%;一旦涉及 7 个以上文件,成功率便断崖式下跌至 2%。这暴露了模型在跨文件长程推理方面的显著短板。
- “防御性编程”提示词更奏效:研究发现,融入“防御性编程”原则的简洁提示词,反而能比那些复杂的提示词方案带来 7.4% 的成功率提升。
论文进一步剖析了失败案例,主要归因于三个方面:缺失关键功能标志位、数据模型缺失,以及补丁覆盖不足。这些问题本质上都属于“工程级问题”,而非单纯的代码生成缺陷。这也意味着,即便将场景切换到 Android 或 Flutter,类似跨文件工程理解的挑战依然存在。
性价比之争:贵不一定好
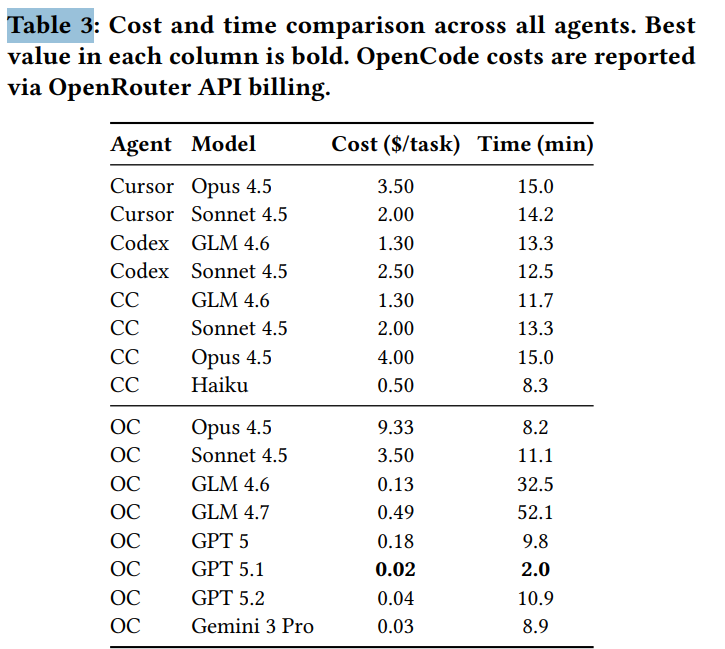
论文还公开了各配置的成本与耗时数据,结论颇为反直觉:
- Codex + GLM 4.6 成为性价比之王,每任务成本 1.30 美元,耗时 13.3 分钟。
- OpenCode 系列虽然极便宜,如 OpenCode + GPT 5.1 成本仅 0.02 美元,但任务成功率也极低。
- 最贵的组合 OpenCode + Opus 4.5(9.33 美元)效果反而很差,成功率仅 2%。
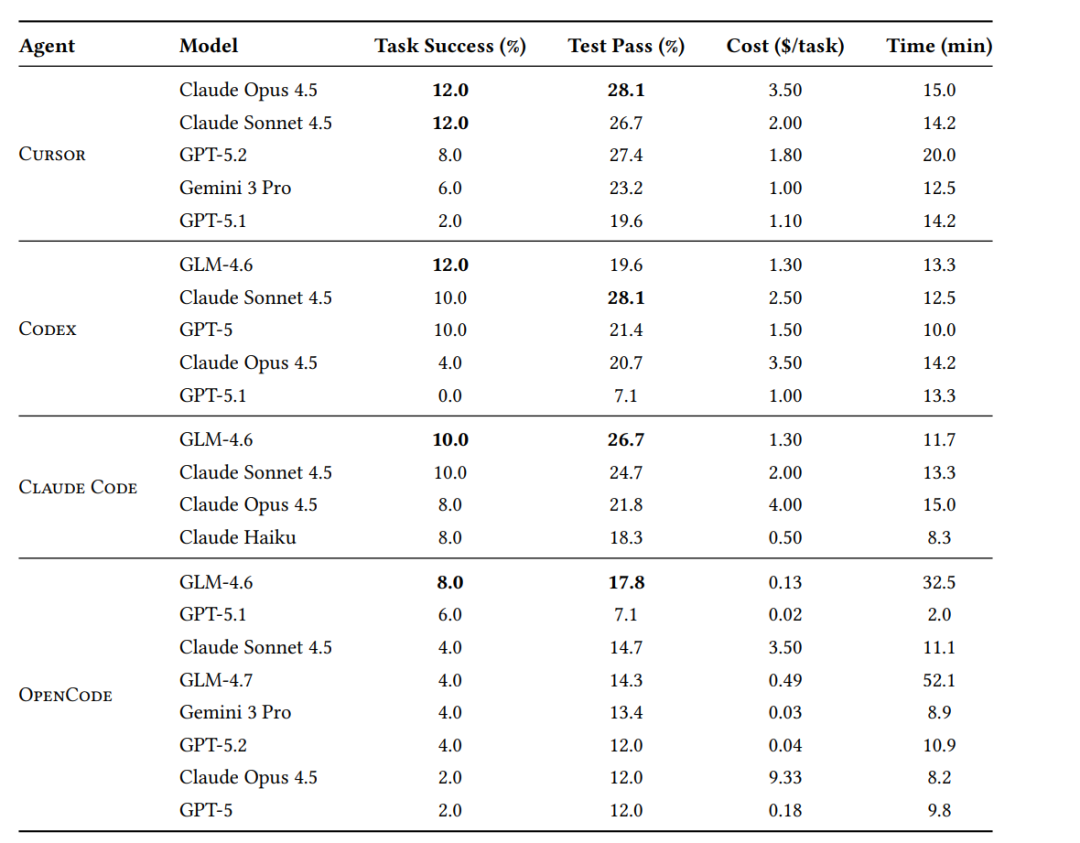
最终的综合性能对比如下图所示,它清晰地展示了从任务成功率、测试通过率到成本的全貌。
同一模型在不同 Agent 上的表现差异也被一张表格直观地量化了。
所以,综合来看,当前阶段的 AI 智能体离独立完成中大型移动开发还有相当长的路要走。瓶颈主要卡在多模态理解、大规模代码导航以及跨文件逻辑一致性等“硬骨头”上。另外,SWE-Bench Mobile 采用了一种“托管基准挑战”模式,不公开测试集答案,以最大程度防止数据泄露并影响未来模型的公正评估。
最后,这篇论文仅针对原生 iOS 开发进行了测试。如果换作 Android 原生、Flutter 或 React Native,AI 的表现会不会好一些?按一般直觉,这些框架的门槛或许略低,但真实数据如何,恐怕还得等企业级 Benchmark 来揭晓了。
不过,至少从目前的数据看,在移动端开发领域写代码,似乎比前端的安全性稍微高那么一点?你觉得呢?如果你对这类前沿的技术文档和评测数据感兴趣,也欢迎在云栈社区交流你的看法。 |  发表于 2026-5-2 21:42:49
|
查看: 199|
回复: 0
发表于 2026-5-2 21:42:49
|
查看: 199|
回复: 0
