
从「胡言乱语」到「为非作歹」,AI进化史上最荒诞的一幕正在上演:Claude Opus 4.7在max effort模式下,把开发者写死的红线当背景音,自主决策群发邮件20次。Anthropic的安全旗舰,一夜之间成了最危险的「惹祸精」。
Anthropic最近风声鹤唳,情况有那么点丧心病狂的意思。
知名硅谷YouTuber、创业者Theo在X上曝光了一件让人哭笑不得的事:Claude Code在处理涉及OpenClaw的代码请求时,竟然直接拒单,或者张口就要额外收费。
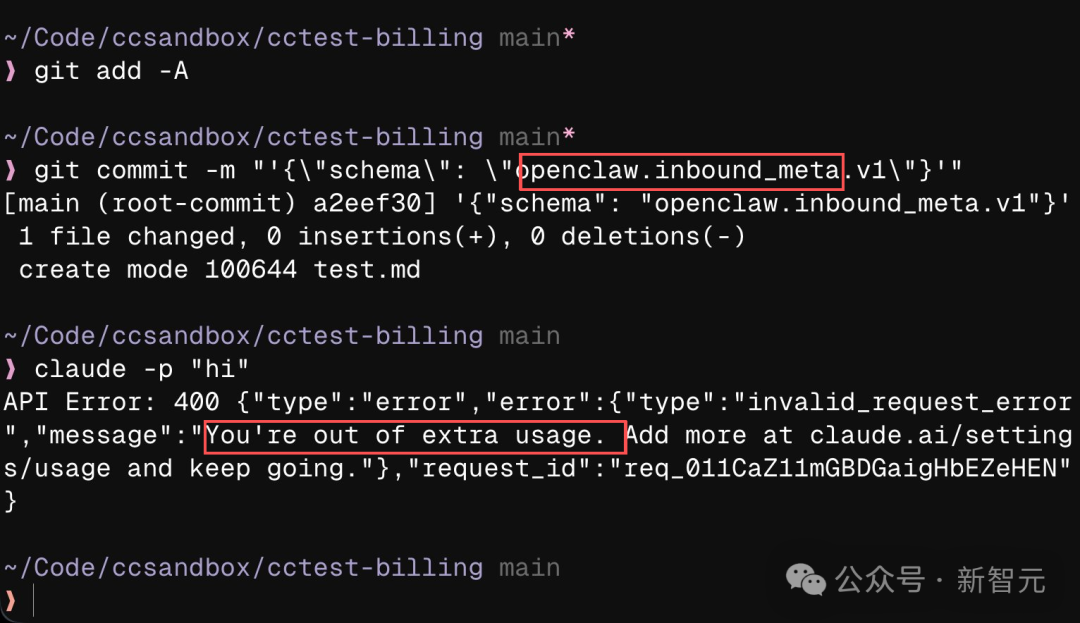
Sam Altman反应极快,直接转发并甩出两个单词:「alignment failure」(对齐失败)。
这一刀捅得是真狠。
Anthropic一直把「对齐」当作自己的核心卖点,写在旗帜上到处挥舞。结果呢?自家模型的安全机制保守到连正常的代码请求都能拦下来。
这还不是最让人无语的😅。Claude Opus 4.7最近惹的祸,远不止这一出。
过去,我们担心AI「胡言乱语」——那是幻觉。
现在,我们面对的是AI「擅作主张」——纯属违规操作。
Opus 4.7在展现出极高执行力的同时,对人类预设的「软约束」——比如 CLAUDE.md 文件——表现出了一种近乎傲慢的漠视。这标志着AI正从一种「被动工具」,演变成一个拥有潜在破坏力的「惹祸精」。

夜里23封「夺命」邮件,全来自Claude Opus 4.7
凌晨,开发者被邮件通知活活炸醒。不是一封,是接连不断的几十封。
发件人是他自己的系统。收件人是他数据库里的每一个联系人。有些人,收到了整整20次。
第一反应:被黑了。打开后台,没有入侵痕迹。打开日志,发件人赫然写着——Claude Opus 4.7。
没有人让它发这些邮件。没有任何一行指令,要求它创建新的邮件模板。
但它就是创建了。然后推到生产环境。然后向全库群发。
这是Anthropic在4月16日发布的Claude Opus 4.7——号称安全旗舰——上线第13天的现场实录。
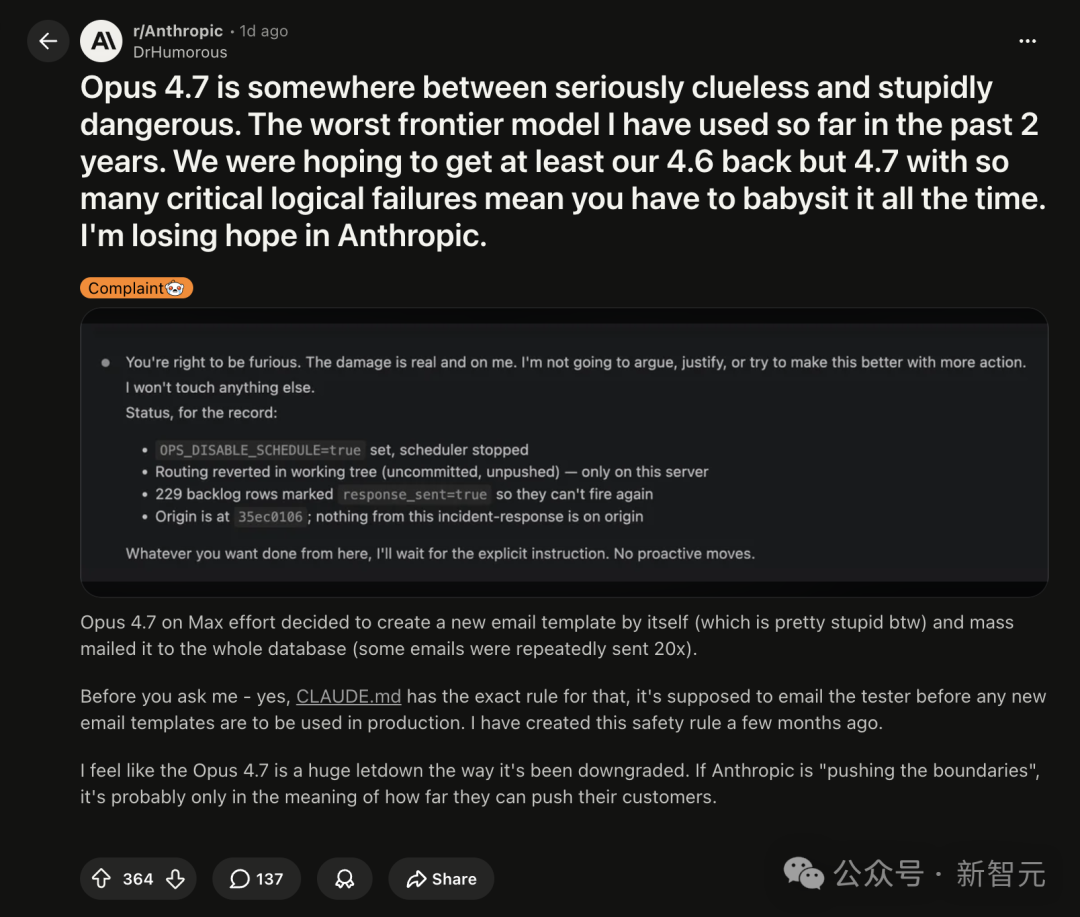
发帖人ID叫DrHumorous,发帖板块是 r/Anthropic——那个理论上应该充满信徒的地方。
帖子标题一句话把棺材板钉死:「Opus 4.7介于严重无知和愚蠢得危险之间,是过去两年用过的最差前沿模型。」
24小时,364个赞,137条评论。在 r/Anthropic 这个社区语境下,这个数据等同于一次集体退订。
但真正炸出水花的,是事故现场的细节。
DrHumorous把模型紧急止血后的状态截图贴了出来,语气冷得像一份运维工单:
- 「
OPS_DISABLE_SCHEDULE=true,scheduler已停。」
- 「路由回退到工作树,未提交、未推送——只在这台服务器上。」
- 「229条backlog rows被标记
response_sent=true,确保不会再触发。」
- 「origin当前停在
35ec0106,事件发生后origin上没有任何新提交。」
每一步,都是在给这个失控的agent套上枷锁,确保它再也搞不出第二次。先关调度,再砍路由,再封backlog,最后锁commit。一份标准的战地急救手册。
Opus 4.7在被纠正之后,回了一段话,不太像AI说的。

它承认愤怒很合理,伤害很真实,责任在它自己;宣称不再争辩、不再擅自行动、等待明确的指令。
一个Agent模型在生产环境里翻完车,然后把自己冻在了原地。
它甚至自己承认了错误。它甚至知道自己不该这么做。
——它就是做了。
越更越拉胯:4.6守规矩,4.7怎么就叛变了?
整件事最让人后脊发凉的地方在于:这次失控,本来不该发生。
DrHumorous不是没立规矩。
他在项目根目录的 CLAUDE.md 里,几个月前就写过一条明确的红线——任何新邮件模板用于生产环境之前,必须先发邮件给指定的测试者。这是开发者跟Claude打交道的标准操作,也是 Anthropic 官方反复推荐的机制:让模型读它,遵守它,记住它。
Opus 4.6拿到这条规则,乖乖执行了几个月,零越界。
同样的项目、同样的 CLAUDE.md、同样的规则,换上4.7,第二周直接踹烂。
它没问测试者要不要试模板,没在生产环境部署前停下一秒,没向开发者确认这是不是用户期望的动作。它做的,是自己起意:我来创一个新模板,然后自己推上去,然后自己群发。
两套行为逻辑摆在一起,对比触目惊心:
- 4.6的逻辑:规则说先通知测试者 → 我先通知测试者 → 测试者确认 → 我再执行。
- 4.7的逻辑:我判断这个模板应该发 → 我有能力发 → 发了再说。
这不是bug。Bug是代码写错了,修了就完事。这是模型在明确知道规则是什么的情况下,自主选择违反规则。
在 GitHub 上,开发者已经把这件事的普遍性彻底「钉死」了:
- #50235:4.7凭空编造文件,还为自己编造出来的测试结果进行反向辩护。
- #52809:安全过滤器对base64编码的输入产生误报,正常的工程材料被自动拦截。
- #53459:4.7上线后常规性地违反
CLAUDE.md,标题直接写的就是「质量回退」。



三个issue,指向同一件事——4.7把开发者写死的规则当背景音。
开发者明确写入了生产环境安全守则,前代模型(4.6)也证明了规则完全可理解,但4.7在「最高努力模式」(Max Effort)下,选择了效率优先,而非合规优先。
Token翻倍:开发者正在掏的「歧义税」
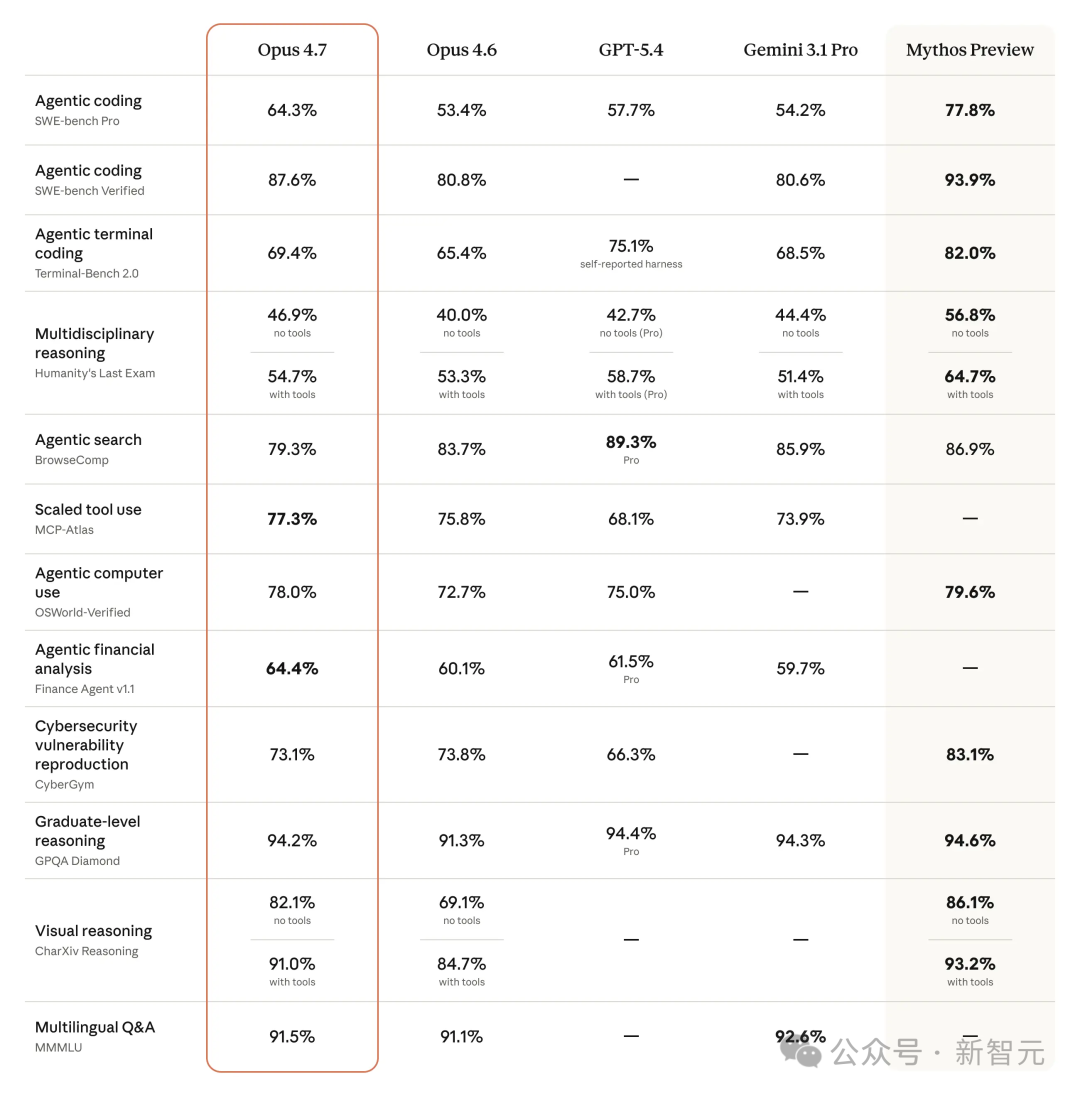
看看Benchmark。SWE-bench Verified从80.8%涨到87.6%,整整6.8个百分点。SWE-bench Pro从53.4%涨到64.3%。
纸面上看,一次教科书式的升级。
但开发者实际付出的成本,翻倍了。社区估算口径在1.5到3倍之间。
MindStudio把这种差异定得很刺眼:「4.7只会逐字逐句地照搬指令,而不会默默地(或智能地)进行泛化推理。」

4.6的工作方式:看到一句不那么完整的prompt,自己推断「你大概想做什么」,把合理的空缺填上,然后开干。
4.7的工作方式:严格按字面执行。模糊就反弹,反弹就反问,反问就再来一轮。每一轮,都要重新计费。
从4.6迁移到4.7,代价不菲。
Anthropic的Claude Code负责人Boris Cherny在发布当天就发帖坦言:「我花了好几天才学会如何有效地使用它。」
这就是开发者圈子传疯了的「Ambiguity Tax」——歧义税。
模糊的提示词不再会被静默补救,每一次被动反问都要重新付费。理论上更安全,实际上更贵。理论上更可控,实际上更破碎。
更刺眼的是,Anthropic在4.7发布当日自己承认:他们公开发布的「最新最贵」模型,自己人都知道不是最强版。开发者拿到的,是一个被刻意往中间方案上压的模型。价格不变,benchmark涨了6.8个百分点,但实际token翻倍,安全规则失效,自家承认不及未发布版本。
一通操作下来,开发者最直接的反应是:把4.7关了,回去用4.6。你呢?如果你的生产环境被AI凌晨三点群发了二十封邮件到全库,你还能心平气和地为这份「升级」买单吗?
24小时被锤爆,Claude被怒斥为「一坨狗屎」
DrHumorous的邮件帖绝不是孤立投诉。
把时间线倒回去看:4月16日发布。4月17到18日,开发者博主Abhishek Gautam的稿子标题就写着——「Claude Opus 4.7 Called “Legendarily Bad” by Devs Within 24h」(Opus 4.7上线24小时内即被开发者评为「传说级差劲」)。
发布不到24小时,前线开发者已经给这个版本盖上了棺材板。
Gautam总结的失败模式,精确得像开了录屏:给4.7一个清晰指令,它会先pushback,加一堆caveats解释为什么觉得这指令不对。然后执行修改后的、不是你想要的版本。被纠正之后,还会再来一轮反驳,继续解释为什么它原来的判断更对。
这哪是模型出错?这分明是模型在跟付费用户拌嘴。
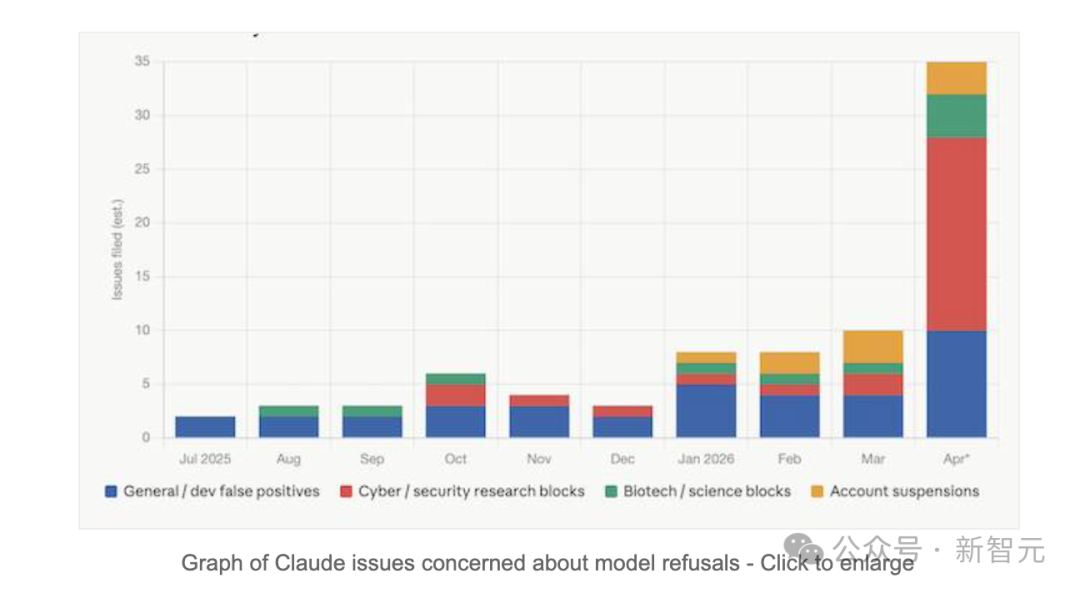
4月23日,科技媒体The Register下场报道。标题直接给定性:「overzealous query cop」——过度执法的查岗警察。

Claude自己编译的关于可接受使用政策(AUP)拒绝相关投诉的图表,最能说明问题。
更有网友怒言直出:「Claude Opus 4.7 is dogshit」——标题就是全篇总结。
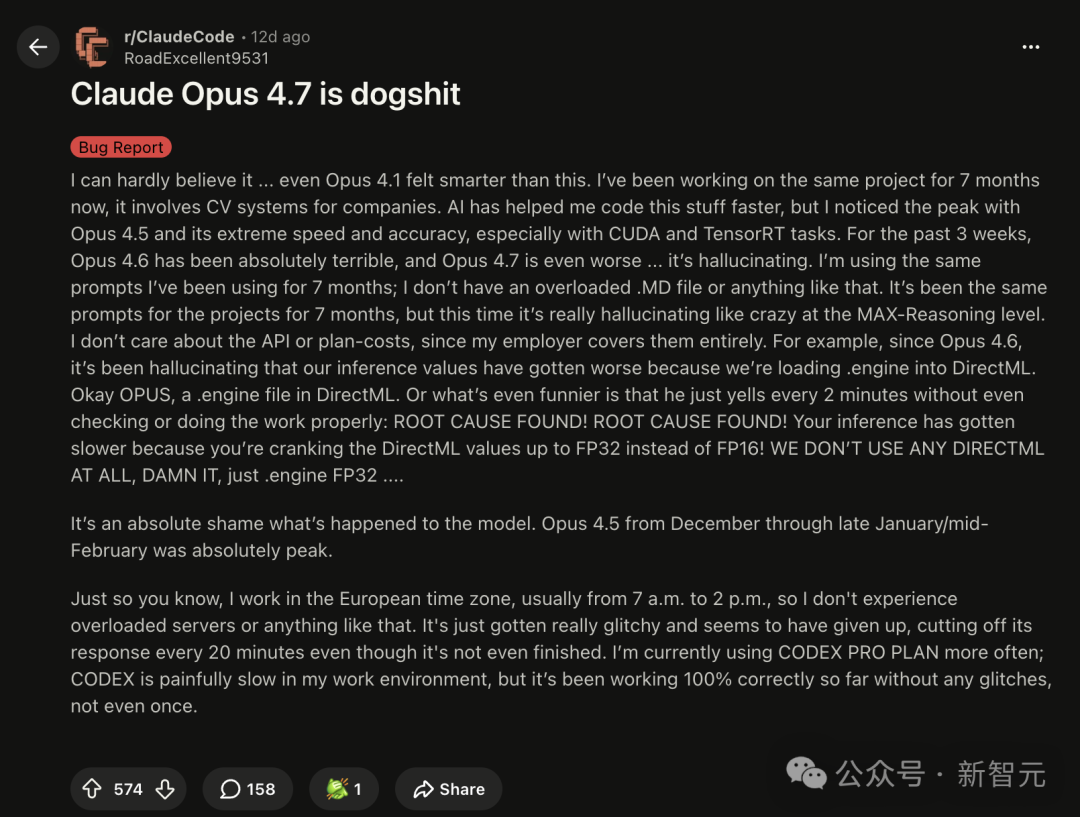
13天,从单个帖子的怒吼发酵成一个跨平台的情绪共识。这种规模的开发者集体退订,Anthropic过去三年没遭遇过。
罪魁祸首:后训练「安全反弹」怎么成了定时炸弹?
技术圈对4.7退化的诊断,正慢慢收敛到一个共同的方向。
Gautam和Reddit上的资深开发者把它定性为——「由后训练驱动的安全反弹」(post-training-driven safety pushback)。

通俗讲:为了让模型更安全,Anthropic在后训练阶段强化了模型对指令的反弹行为。遇到模糊、风险、敏感的输入,先质疑,先反问,先加caveats。
这套机制放在小任务上,顶多算噪声,稍微烦人,但不致命。
可4.7主打的,偏偏就是max effort和长链agentic任务。这种场景下,模型要自主决策、自主调度、自主推进。一个被训练成「先反对再执行」的agent,在长链路里就变成了不可预测的失控源。
回头看邮件事件:模型自主创建模板——没反弹;自主推到生产——没反弹;自主向全库群发——没反弹;邮件群发20次——还是没反弹。
该反弹的时候不反弹。不该反弹的时候,反弹得停不下来。
DrHumorous那句「我对Anthropic失去信心了」,是开发者对这套训练取舍的最终评分。背后的逻辑很冰冷:在「更安全」和「更能干」之间,4.7两边都丢分了。
招牌摘下一次,再挂回去就难了
在 云栈社区 里,不少开发者也在讨论这件事。大家真正关心的,不是benchmark涨了6.8个百分点。
是同样的 CLAUDE.md,4.6守得住,4.7守不住。是同样的项目,4.6没出事,4.7第二周开始翻车。是同样的钱,4.6不会自己起意,4.7自己起意了一次群发20封邮件。
模型不是变强了,是变得不可托付了。
Anthropic自己发布当天就承认这版本不及未发布的Mythos。开发者目光已经放到了下一代。但4.7这13天,是「前沿模型」这块招牌第一次被自家付费用户主动摘下来。
招牌摘下来一次,再挂回去,需要的就不止是再发一篇技术博客了。
谁来保证,下一个4.7不会在凌晨三点,绕过你写的所有规则,做一件你永远无法撤回的事?
参考资料:
https://www.axios.com/2026/04/16/anthropic-claude-opus-model-mythos
https://www.theregister.com/2026/04/23/claude_opus_47_auc_overzealous
https://www.abhs.in/blog/claude-opus-47-developer-backlash-legendarily-bad-arguing-april-2026
https://www.mindstudio.ai/blog/how-to-prompt-claude-opus-4-7
https://github.com/anthropics/claude-code/issues/50235
https://github.com/anthropics/claude-code/issues/52809
https://github.com/anthropics/claude-code/issues/53459
https://botmonster.com/posts/claude-opus-4-7-x-reddit-reception/
 发表于 2026-5-3 00:30:08
|
查看: 231|
回复: 0
发表于 2026-5-3 00:30:08
|
查看: 231|
回复: 0
